




随着 AI 驱动代码编辑器的普及,开发者开始越来越依赖自然语言与工具的交互。然而,Cursor 不再支持通过删除账号实现无限期免费使用,Windsurf 的高级功能也需要订阅费用。对于喜欢使用自然语言进行开发的程序员来说,这样的限制无疑提高了工具使用的门槛。那么,有没有一款工具可以兼具强大的功能和免费的体验?Google IDX 的到来,或许正是开发者们期待已久的答案。
作为 Google 推出的新一代 AI 代码编辑器,Google IDX 不仅支持自然语言交互,还提供免费使用和云端开发等多种优势。这篇文章将带你全面了解这款工具,以及如何利用它提升开发效率。
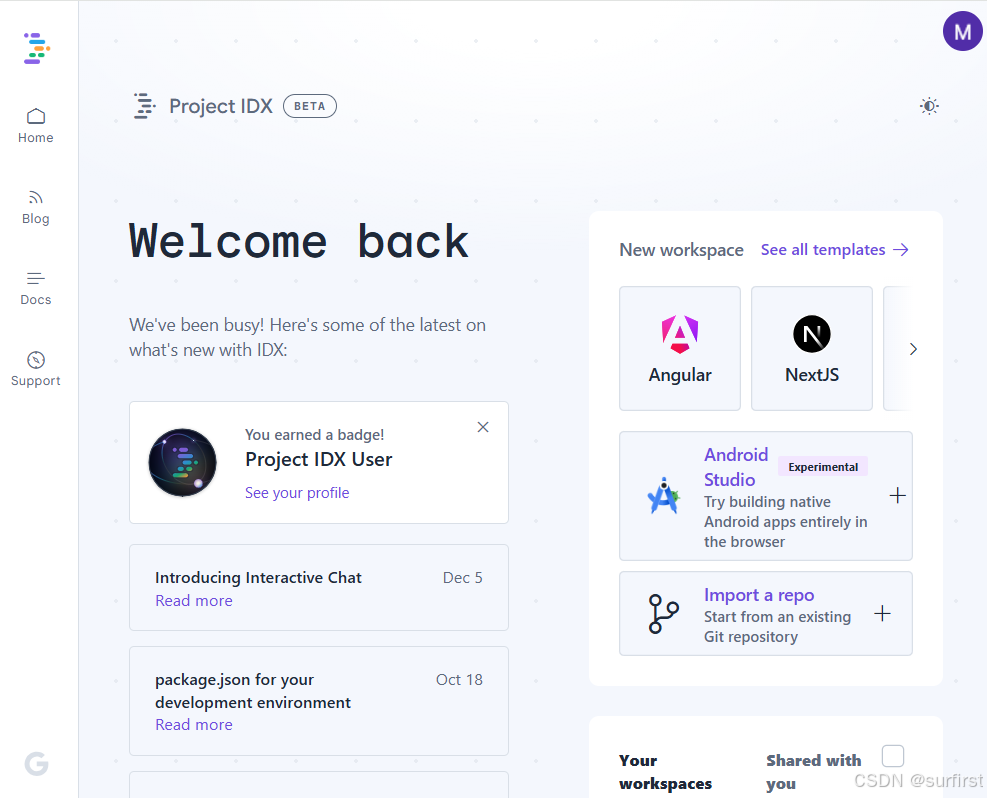
开发者应该关注 Google IDX 的 3 个原因
在当下的技术趋势中,Google IDX 的价值体现在以下几个方面:
-
云端开发的重要性愈加突出
随着远程办公和全球化协作的普及,基于云的开发工具成为团队协作的核心。Google IDX 让开发者无需复杂的本地配置,即可在云端高效开发。 -
AI 正在重塑开发流程
AI 技术正在改变代码生成、调试甚至性能优化的方式。Google IDX 内置的 Gemini 技术,让 AI 助力开发真正落地。 -
支持多平台开发的需求增加
当前全栈开发者常需切换多个框架和平台。Google IDX 提供内置的多框架支持和在线模拟器,统一了开发流程。
Google IDX 简介
Google IDX 是一款完全基于云的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











