






最近国产大模型DeepSeek-671B火出圈了!但很多小伙伴问:想在自己的服务器上部署这个「7000亿参数巨无霸」,究竟需要什么配置?今天我们就来一一揭秘
一、为什么需要本地部署?

在探讨 DeepSeek 671B 本地化部署所需配置之前,先来深入了解一下本地化部署所带来的独特优势。
(一)数据安全的坚固堡垒
在当今这个数据驱动的时代,数据安全的重要性怎么强调都不为过。当我们将 DeepSeek 671B 进行本地化部署时,就如同为数据构筑了一座坚不可摧的堡垒。所有的数据处理和存储都在本地环境中完成,无需将敏感信息上传至云端,从而有效避免了因网络传输或第三方云服务可能引发的数据泄露风险 。对于企业而言,无论是商业机密、客户隐私数据,还是关键业务数据,都能得到更可靠的保护。在医疗领域,患者的病历信息涉及个人隐私,本地化部署的 DeepSeek 671B 可用于医疗数据分析和诊断辅助,确保患者数据不会外流,维护患者的隐私安全。
(二)个性化定制的自由舞台
每个用户或企业的业务需求和应用场景各不相同,本地化部署 DeepSeek 671B 模型能满足个性化需求。在本地环境中,用户可依实际情况灵活调整、优化模型,如按特定领域知识和数据微调,使其适配金融风险评估、法律合同审查等专业领域应用,还能根据业务规模和负载合理配置硬件资源,平衡性能与成本。一家自然语言处理创业公司通过本地化部署并定制模型,打造出智能写作辅助工具,在市场上崭露头角。
(三)使用自主性的有力保障
本地化部署使 DeepSeek 671B 用户自主性更高。无需依赖外部网络和第三方服务,可随时按需启动使用,避免因网络波动、服务器故障或第三方服务限制导致的使用中断。在网络不稳定地区或对服务连续性要求高的场景中优势明显,如科研团队进行紧急实验数据分析时,不受网络状况影响,能稳定高效地用本地化部署的 DeepSeek 671B 处理数据和训练模型,提高科研效率。
二、硬件配置要求大揭秘
DeepSeek 671B 作为一款超大规模的大语言模型,其本地化部署对硬件配置有着较高的要求。接下来,让我们深入了解一下部署 DeepSeek 671B 所需的硬件配置。下面这张图是所需的最低配置

(一)CPU:核心运算的大脑
在 DeepSeek 671B 的本地化部署中,需要 64 核以上的服务器集群 CPU。因其运行涉及海量数据处理和复杂运算,如文本生成时要分析处理大量文本数据。强大 CPU 能快速执行运算,保障模型高效运行。
不同级别 CPU 在部署和运行中的表现差异大。比如 Intel Xeon 单核性能出色,适合处理单个任务;AMD EPYC 系列多核性能更优,能同时处理多个任务,提升整体运算效率。
(二)内存:数据处理的高速通道
内存方面,至少需要 512GB 以上。这是因为 DeepSeek 671B 模型规模庞大,运行时需要加载大量的模型参数和数据,充足的内存可以确保这些数据能够快速地被读取和处理,从而提高模型的运行效率。在进行知识问答时,模型需要快速读取大量的知识数据,以准确回答用户的问题。如果内存不足,模型在处理任务时可能会频繁地进行数据交换,将数据从内存中写入硬盘,再从硬盘中读取到内存,这会导致运行速度大幅下降,甚至出现程序崩溃的情况。
(三)硬盘:数据的存储仓库
DeepSeek 671B 模型文件大,运行还会产生临时数据和缓存文件,硬盘至少需 1TB 以上。不同类型硬盘对部署和数据读取速度影响大,SSD 读写快、响应时间短,能提高模型运行效率;HDD 虽容量大,但读写慢,会使模型加载和数据读取缓慢,影响使用效果。为确保 DeepSeek 671B 高效运行,建议优先选 SSD 作为存储硬盘。
(四)显卡:图形处理与运算加速的利器
显卡在 DeepSeek 671B 的部署中扮演着重要的角色,多节点分布式训练(如 8x A100/H100)是较为理想的配置。这是因为 DeepSeek 671B 在训练和推理过程中,需要进行大量的矩阵运算和复杂的数学计算,显卡的并行计算能力能够大大加速这些计算过程,提高模型的训练和推理速度。NVIDIA A100 和 H100 显卡采用了先进的架构和技术,拥有强大的计算核心和高带宽显存,能够快速地处理大规模的数据,为 DeepSeek 671B 的运行提供强大的计算支持。显卡性能的优劣直接影响着模型的训练和推理速度。性能较弱的显卡在处理大规模数据时,可能会出现计算速度慢、卡顿等问题,导致模型的训练和推理效率低下。而高性能的显卡则能够快速地完成计算任务,提高模型的运行效率,为用户提供更快速、准确的服务。
(五)其他硬件:稳定运行的保障
除主要硬件外,1000W + 高功率电源和散热系统也必不可少。高功率电源为硬件稳定供电,确保设备高负载运行时无电力故障,DeepSeek 671B 运行时功率消耗大,需高功率电源。散热系统可降低硬件运行产生的热量,防止过热损坏,延长硬件寿命。DeepSeek 671B 运行时 CPU、显卡等硬件产热多,散热不及时易致硬件性能下降或损坏,所以良好散热系统对硬件稳定性和寿命很关键。
三、特殊情况与解决方案
(一)量化技术:降低硬件门槛
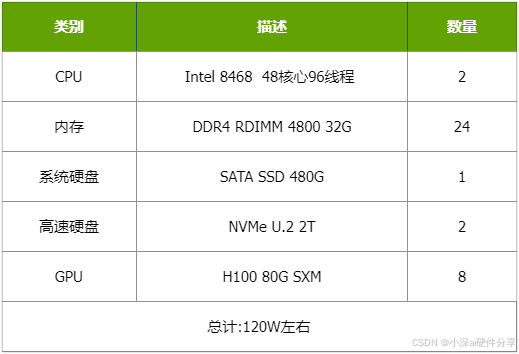
在硬件配置无法完全满足 DeepSeek 671B 标准要求时,量化技术是有效解决方案。4-bit/8-bit 量化技术将模型参数以较低精度表示,大幅降低显存占用。传统模型部署中参数常以 32-bit 或 16-bit 等高精度存储,需较大显存空间,而 4-bit/8-bit 量化技术可降低存储精度,让模型能在显存较小硬件上运行,4-bit 量化技术或使 DeepSeek 671B 模型显存占用降低数倍,实现显存有限硬件上的部署。量化虽可能影响模型精度,但经合理参数调整优化,精度损失可控。在对精度要求不高的一般性文本生成、简单知识问答等场景,量化后的 DeepSeek 671B 仍能提供满意服务。我们在这里就使用了Q4量化,本来deepseek671B以FP16精度部署的话需要1400GB的显存,需要一个服务器集群才可以,而经过Q4量化,只需要一台8卡H100服务器足够了。以下是我们推荐的运行Q4量化版deepseek相关配置,经过测试,生成token速度可以达到20token/s,5到10人并发使用环境下也可以达到10token/s以上,还是能够流畅使用的。

















 3316
3316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









