






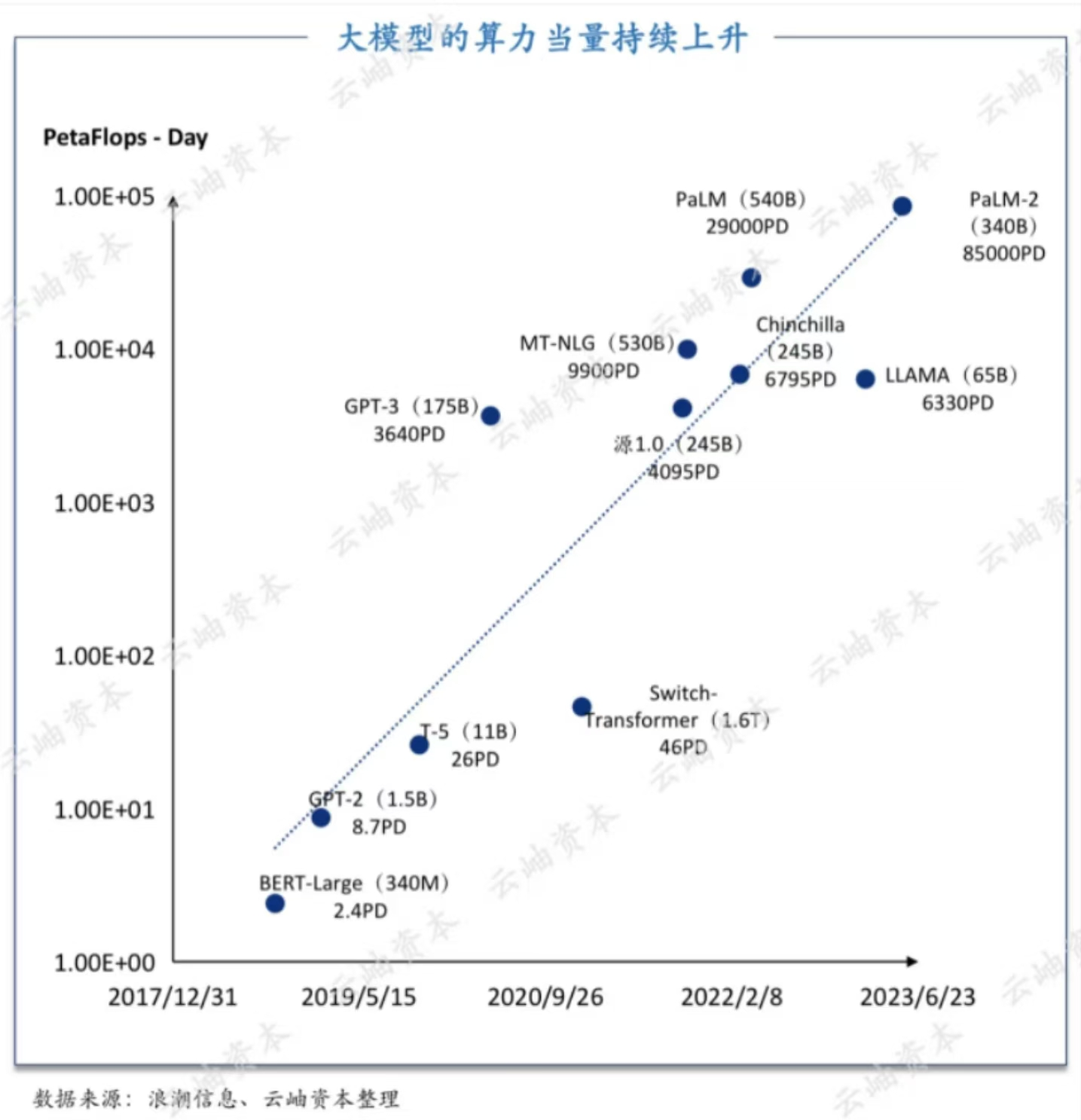
2025年,AI行业迎来爆发式增长,从大模型训练到AIGC应用,算力需求持续攀升。然而,不同规模的企业在硬件选择上往往面临巨大差异——创业团队追求性价比,中型企业需要稳定扩展,大厂则关注超大规模算力调度。
为此,我们发布《2025年度AI硬件白皮书》,从实际业务场景出发,拆解创业团队、中型企业、大厂的服务器配置逻辑,助你精准匹配算力需求,避免资源浪费。
 01 创业团队(4卡及以下方案):低成本启动,高效验证
01 创业团队(4卡及以下方案):低成本启动,高效验证
适用场景:AI初创公司、高校实验室、个人开发者(LLM微调、AIGC内容生成) 核心痛点:预算有限,但需快速验证模型可行性
推荐配置方案
-
显卡选择:
-
NVIDIA RTX 4090(24GB显存):适合小模型微调、Stable Diffusion推理
-
NVIDIA RTX 6000 Ada(48GB显存):适合7B~13B参数LLM全参数微调
-
-
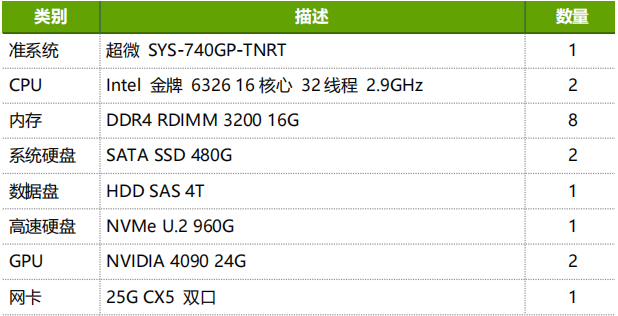
服务器方案:
-
单卡工作站(如Dell Precision 7960)或四卡及以下服务器(如超微 SYS-740GP-TNRT)
-
云+本地混合部署(训练用本地卡,推理上云)
-
关键指标: ✅ 显存≥24GB(避免OOM报错) ✅ PCIe 4.0 x16带宽(确保数据传输效率) ✅ 风冷/基础液冷(控制噪音与散热成本)
案例:贵阳某AI绘画4人工作室使用单卡RTX 6000 Ada,3小时完成SDXL-LoRA训练,成本仅为云服务的1/5。
02 中型企业(多卡并行):稳定扩展,支撑业务增长
适用场景:AI SaaS公司、垂直领域模型训练(金融、医疗等) 核心痛点:需平衡算力规模与TCO(总拥有成本)
推荐配置方案
-
显卡选择:
-
NVIDIA H100 80GB(NVLink互联):适合几百亿参数模型训练
-
A100 40GB/80GB(二手市场高性价比):适合预算有限但需多卡并行的场景
-
-
服务器方案:
-
4~8卡GPU服务器(如Supermicro AS-4124GO-NART)
-
RDMA高速网络(降低多节点通信延迟)
-
关键指标: ✅ NVLink/Switch互联(避免PCIe带宽瓶颈) ✅ 2000W以上冗余电源(保障长时间高负载运行) ✅ 液冷散热方案(降低30%以上能耗)
案例:武汉某医疗AI公司采用以下8卡H20集群,将CT影像分析模型的训练周期从2周缩短至3天。
| 类别 | 详情 |
| CPU | 英特尔至强Max 9468(2.1GHz/48-Core)处理器*2 |
| GPU | HGX H20 8GPU 模组 |
| 内存 | 2T内存 64G DDR5*32 |
| 系统盘 | 480G *2 |
| NVMe | 3.84T NVMe *4 |
| raid 卡 | 支持raid0/1/10/JBOD |
| 网卡 | CX5 25G * 1 |
| IB卡 | 400G MCX75310AAS-NEAT * 6 |
03 大厂/超算中心(数据中心级):极致算力,弹性调度
适用场景:云服务商、国家级AI实验室、千亿参数大模型训练 核心痛点:超大规模分布式训练、绿色节能、运维自动化
推荐配置方案
-
显卡选择:
-
NVIDIA H100集群(DGX SuperPOD架构)
-
-
服务器方案:
-
机柜级GPU服务器(如NVIDIA DGX H100系统)
-
全栈液冷数据中心(PUE<1.2)
-
关键指标: ✅ InfiniBand/NVSwitch组网(支撑万卡级并行训练) ✅ 智能算力调度系统(动态分配训练/推理资源) ✅ 碳中和认证(符合ESG政策要求)
案例:广东某头部云厂商部署H100智算中心,支持千亿参数大模型训练,算力利用率提升40%。
 04 年AI硬件趋势:3大关键变化
04 年AI硬件趋势:3大关键变化
-
推理硬件多元化:除了GPU,LPU(Groq)、NPU(华为昇腾)开始进入边缘计算市场
-
二手显卡市场升温:A100/H800因禁售令成为稀缺资源,企业需警惕翻新卡
-
液冷成为标配:欧盟新规要求数据中心PUE<1.3,液冷服务器需求激增
立即免费领取: 👉 点击立即咨询 添加客服,获取1V1服务器配置咨询
AI硬件的选择,本质是“业务需求+预算+未来扩展性”的平衡。无论是创业团队的精打细算,还是大厂的超大规模部署,合理的硬件配置都能让每一分算力投入产生最大价值。
你的团队正处于哪个阶段?欢迎留言讨论!

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









