








 该博客介绍了CVPR2021一篇关于人体姿态估计的文章,提出了一种名为Disentangled Keypoint Regression的方法。通过HRNet作为主干网络,模型首先输出不同尺度的特征,然后通过自适应卷积模块计算offset,最后结合heatmap和offset预测人体关键点。该方法在CrowdPose数据集上进行了实验,展示了其在人体姿态估计任务上的优越性能。
该博客介绍了CVPR2021一篇关于人体姿态估计的文章,提出了一种名为Disentangled Keypoint Regression的方法。通过HRNet作为主干网络,模型首先输出不同尺度的特征,然后通过自适应卷积模块计算offset,最后结合heatmap和offset预测人体关键点。该方法在CrowdPose数据集上进行了实验,展示了其在人体姿态估计任务上的优越性能。
Bottom-Up Human Pose Estimation Via Disentangled Keypoint Regression
解构式关键点回归
CVPR 2021
论文地址:https://arxiv.org/pdf/2104.02300.pdf
代码地址:https://github.com/HRNet/DEKR
一、模型结构
1、主干网络:HRNet-HRNet详解_gdtop的个人笔记-优快云博客

输入:[3, 512, 512]
输出:[32, 128,128]、[64, 64, 64]、[128, 32, 32]、[256, 16, 16]
拼接输出:[480, 128, 128]
2、heatmap
输入:[480, 128, 128]
卷积:[480, 32, 1, 1]、[32, 32,3,1]、[32, 15,1,1]
输出:heatmap [15, 128, 128]
3、offset
输入:[480, 128, 128]
offset_feature:conv[480, 210, 1, 1],14个关键点(CrowdPose数据集),共14个分支,每个分支15个通道,即[15, 128, 128]。
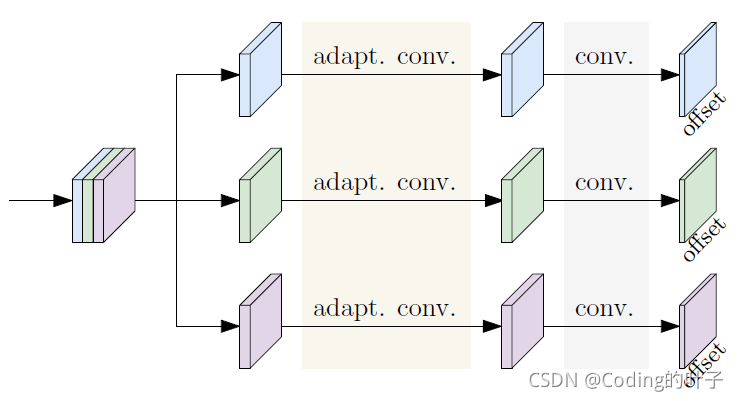
3.1 自适应卷积 adapt. conv.
(1)仿射变换矩阵:[15, 128, 128] --conv(15,4,3,1)、reshape-->[128x128, 2, 2]
(2)offset: 仿射变换矩阵乘以基本矩阵,然后减去基本矩阵得到位置偏移,[128x128, 2, 9]--reshape-->[18, 128, 128]
(3)平移矩阵:[15, 128, 128] --conv(15,2,3,1)、reshape-->[2, 128, 128]
(4)offset:将(2)中结果加上平移矩阵,相当于对结果做了一次平移变换。经过这个步骤,基本确定每个像素点相关的3x3个点坐标。[18, 128, 128]
(5)out:[15, 128, 128]、[18, 128, 128]--DeformConv2d(15, 15, 3, 1)-->[15, 128, 128]
(6)out:(5)中为相关像素点卷积结果,再加上原始输入[15, 128, 128]得到最终输出[15, 128, 128]。
class AdaptBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, outplanes, stride=1,
downsample=None, dilation=1, deformable_groups=1):
super(AdaptBlock, self).__init__()
regular_matrix = torch.tensor([[-1, -1, -1, 0, 0, 0, 1, 1, 1],\
[-1, 0, 1, -1 ,0 ,1 ,-1, 0, 1]])
self.register_buffer('regular_matrix', regular_matrix.float())
self.downsample = downsample
self.transform_matrix_conv = nn.Conv2d(inplanes, 4, 3, 1, 1, bias=True)
self.translation_conv = nn.Conv2d(inplanes, 2, 3, 1, 1, bias=True)
self.adapt_conv = ops.DeformConv2d(inplanes, outplanes, kernel_size=3, stride=stride, \
padding=dilation, dilation=dilation, bias=False, groups=deformable_groups)
self.bn = nn.BatchNorm2d(outplanes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
N, _, H, W = x.shape
transform_matrix = self.transform_matrix_conv(x)
transform_matrix = transform_matrix.permute(0,2,3,1).reshape((N*H*W,2,2))
offset = torch.matmul(transform_matrix, self.regular_matrix)
offset = offset-self.regular_matrix
offset = offset.transpose(1,2).reshape((N,H,W,18)).permute(0,3,1,2)
translation = self.translation_conv(x)
offset[:,0::2,:,:] += translation[:,0:1,:,:]
offset[:,1::2,:,:] += translation[:,1:2,:,:]
out = self.adapt_conv(x, offset)
out = self.bn(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out3.2 offset
14个分支[15, 128, 128]分别经过两次自适应卷积和Conv[15, 2, 1, 1]得到14x[2, 128, 128],拼接之后得到[28, 128, 128]。
4、poses
(1)将offset中取值减去各个像素的位置坐标得到posemap,[28, 128, 128]
(2)选取heatmap中最后一维来作为人体中心点得分,heatmap[-1](1, 128, 128),对其进行最大池化后选出取值大于阈值0.01的分数ctr_score与位置坐标,最多保留30个中心点,即最多检测出30个人。假设符合条件的有N个点,然后从posemap中选择相应的姿态[N, 14, 2]。
(3)heatmap中剩余14维度为14个关键点的热力值,根据保留的中心点,用各个关键点平均值作为热力值得分heat_score。
(4)最终分数为:ctr_score * heat_score
(5)NMS:在同一人体关键点框内,如果两个属于不同中心点的关键点数量过近,且过近关键点的数量过多,那么仅保留heat_score最大的关键点。



















 2328
2328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











