 Python 自动化特征工程实现
Python 自动化特征工程实现





 这篇博客介绍了一种使用Python进行自动化特征工程的方法,通过定义一系列的衍生函数(如Num、Evr、Avg等),针对不同时间窗口计算用户额度使用率的统计特征。这些特征包括了使用率的计数、是否存在、平均值、总和等,覆盖了申请前30天至360天的不同时间段,从而构建了用户的12个新特征。该方法适用于数据预处理和机器学习模型的输入特征构建。
这篇博客介绍了一种使用Python进行自动化特征工程的方法,通过定义一系列的衍生函数(如Num、Evr、Avg等),针对不同时间窗口计算用户额度使用率的统计特征。这些特征包括了使用率的计数、是否存在、平均值、总和等,覆盖了申请前30天至360天的不同时间段,从而构建了用户的12个新特征。该方法适用于数据预处理和机器学习模型的输入特征构建。
参考:Python手写了 35 种可解释的特征工程方法 - 腾讯云开发者社区-腾讯云
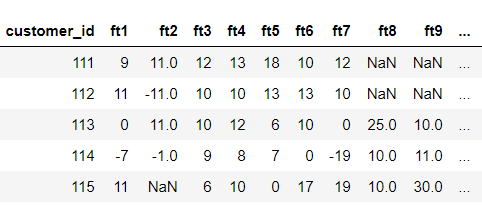
一、数据集
把计算每个用户额度使用率记为特征ft ,按照时间轴以月份p为切片展开,得到申请前30天内的额度使用率,申请前30天至60天内的额度使用率,申请前60天至90天内的额度使用率,…,申请前330天至360天内的额度使用率,得到用户的12个特征。
二、主函数
#读取数据
data = pd.read_excel('textdata.xlsx')
#指定参与衍生的变量名
FEATURE_LIST = ['ft','gt']
#指定聚合月份
P_LIST = [3,6]
#调用变量衍生函数
gen = feature_generation(data, FEATURE_LIST, P_LIST)
df = gen.fit_generate()三、构建feature_generation类
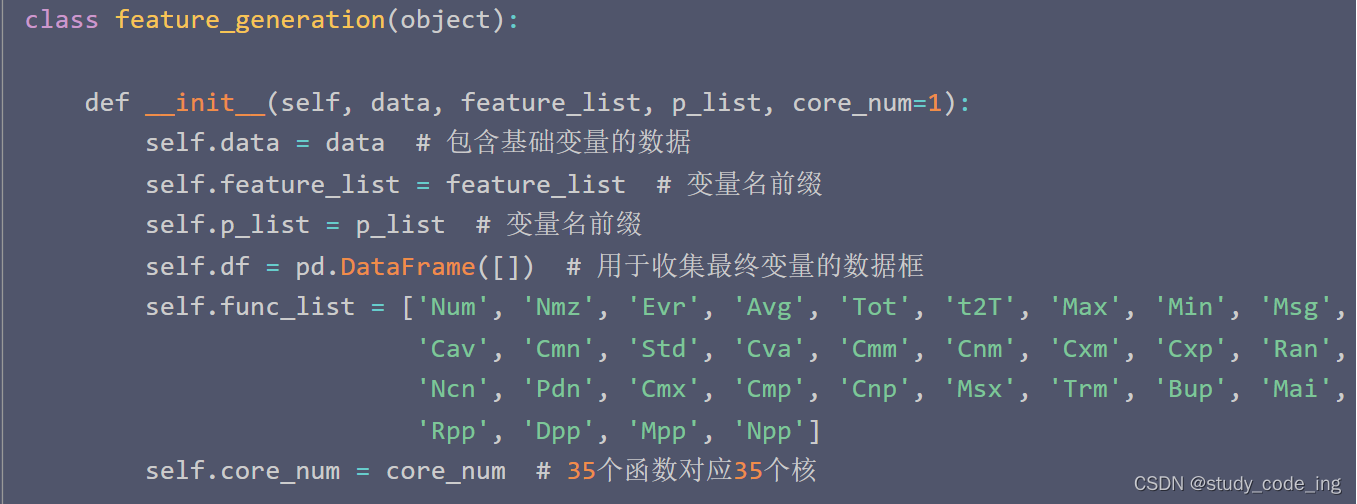
data 为需要处理的数据
feature_list 需要处理的变量名的前缀
p_list 需要聚合的月份
df 用于收集最终变量的数据表
四、定义fit_generate
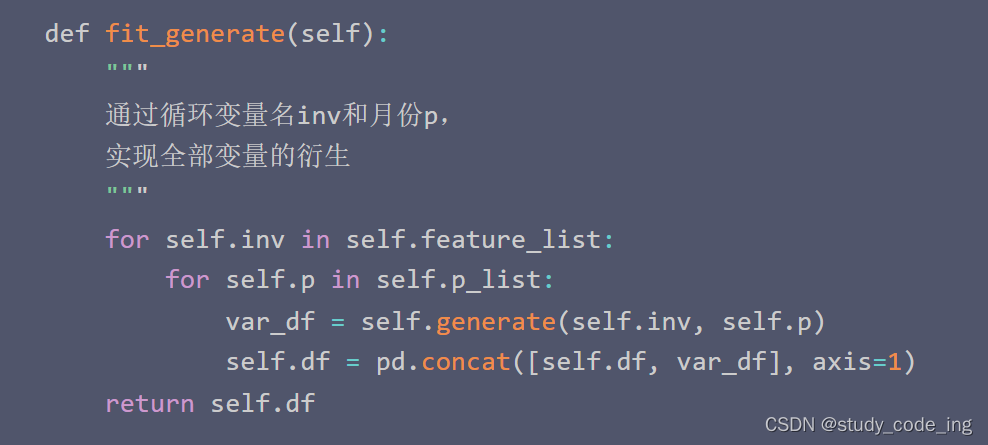
使用分批迭代的方法,外层循环遍历需要衍生的特征,内层循环遍历月份,在循环中过generate函数将特征名和月份传入,将结果存入var_df,通过concat将var_df并如selt.df,最后返回self.df。Keras使用分批迭代(fit_generate)的方式训练数据_MXuDong的博客-优快云博客_fit_generate
五、函数generate
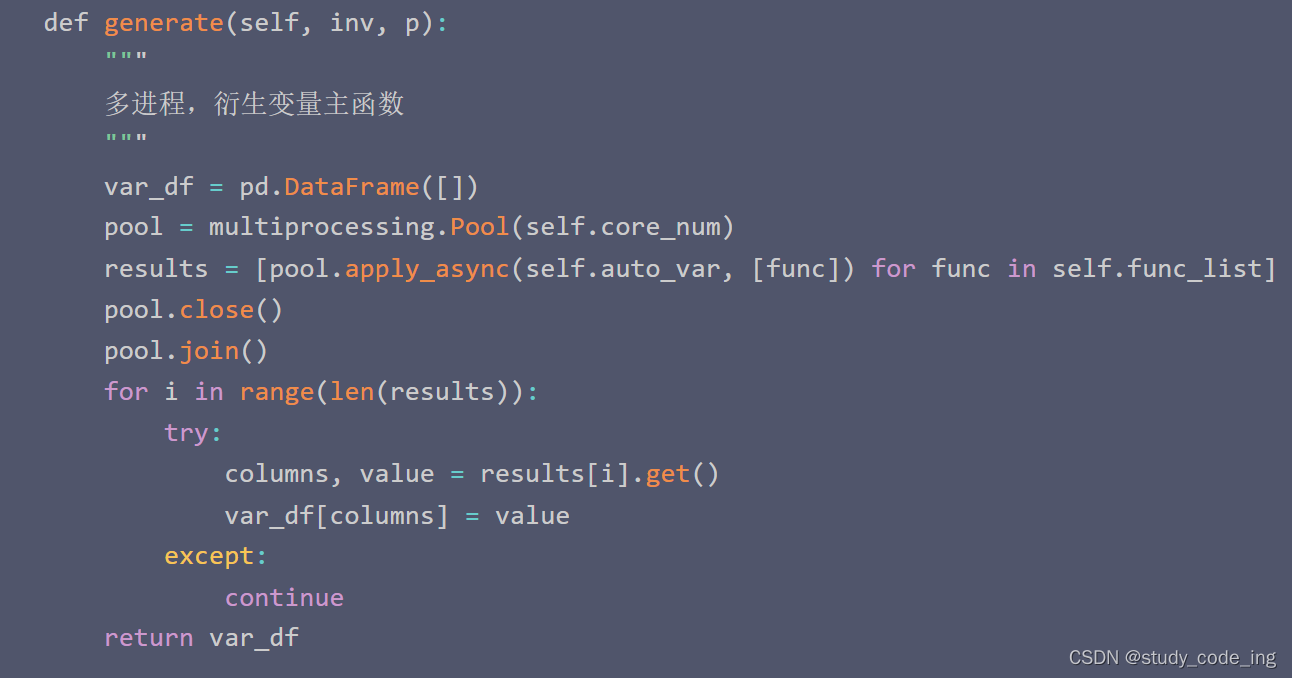
调用auto_var函数,将列名和数据传入results,用var_df储存,最后返回var_df
六、函数auto_var
# 定义批量调用双参数的函数,具体函数请往下面看。
def auto_var(self, func):
if func == 'Num':
try:
return self.Num(self.inv, self.p)
except:
print("Num PARSE ERROR", self.inv, self.p)
elif func == 'Nmz':
try:
return self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 867
867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









