 Kaggle实战:Titanic项目实战与本地部署教程
Kaggle实战:Titanic项目实战与本地部署教程




目录
一、简介
以Titanic Top 4% with ensemble modeling为例,熟悉使用Kaggle网站及项目复现。
二、前期准备
1、python环境
官网下载python(我使用的是3.8.10版本),搭建python环境
2、pycharm
pycharm : http://www.jetbrains.com/pycharm/download/#section=windows(社区版)也可以下载专业版
三、网页运行
1、网址:kaggle.com
2、注册账号
3、打开一个项目
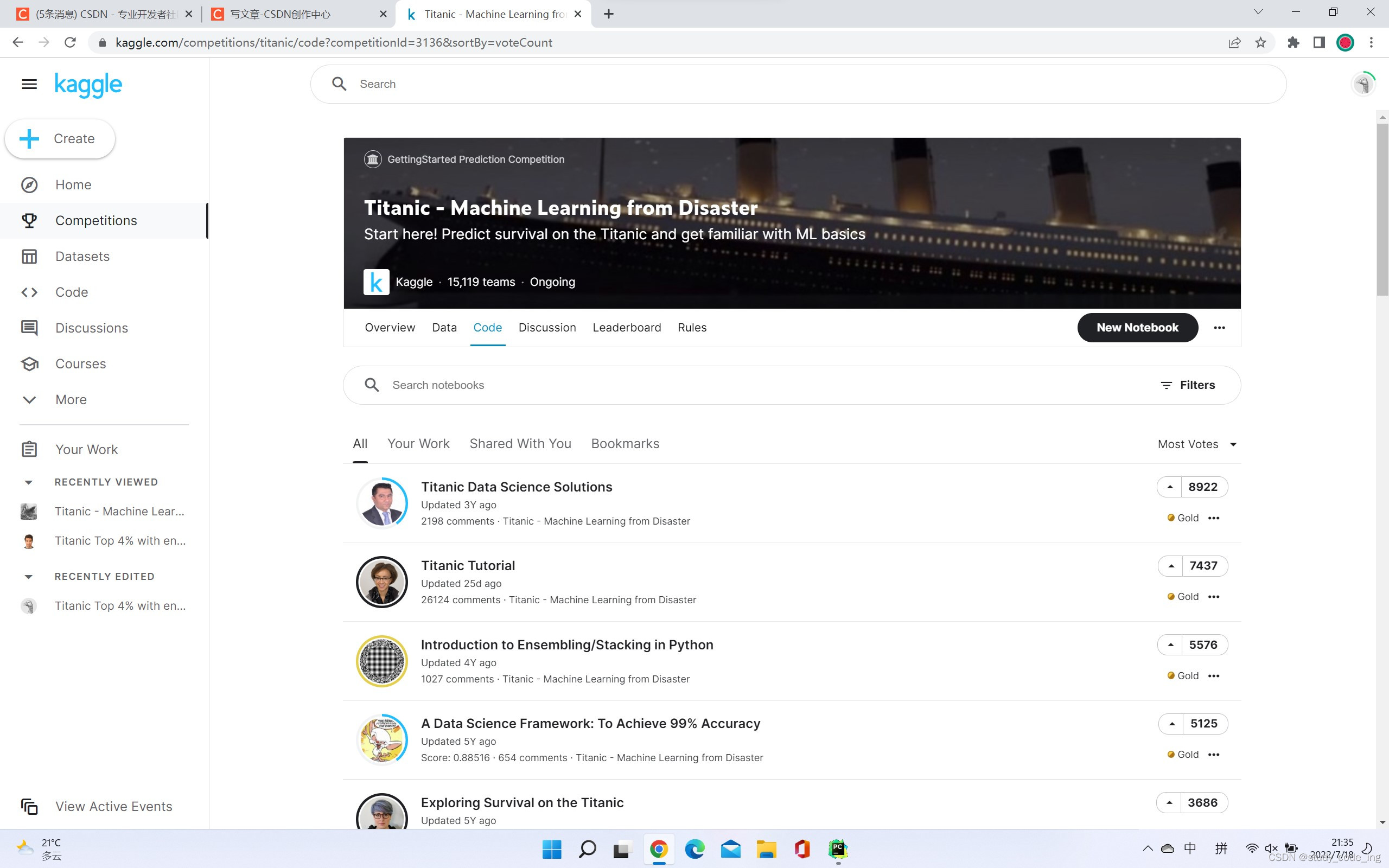
4、进入后可以看到项目的代码
5、点Edit可以进入编辑模式
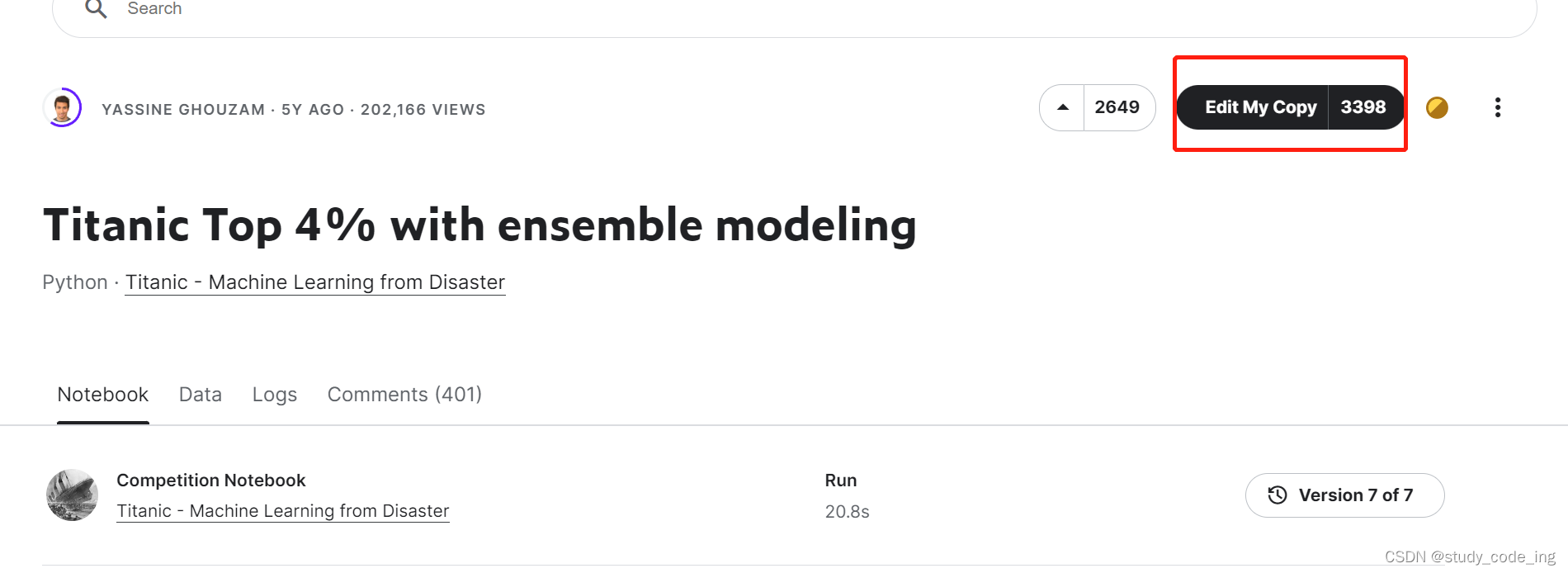
6、此处可以更改名字并保存
后面可在左侧任务栏your work找到
7、选择run all可以运行
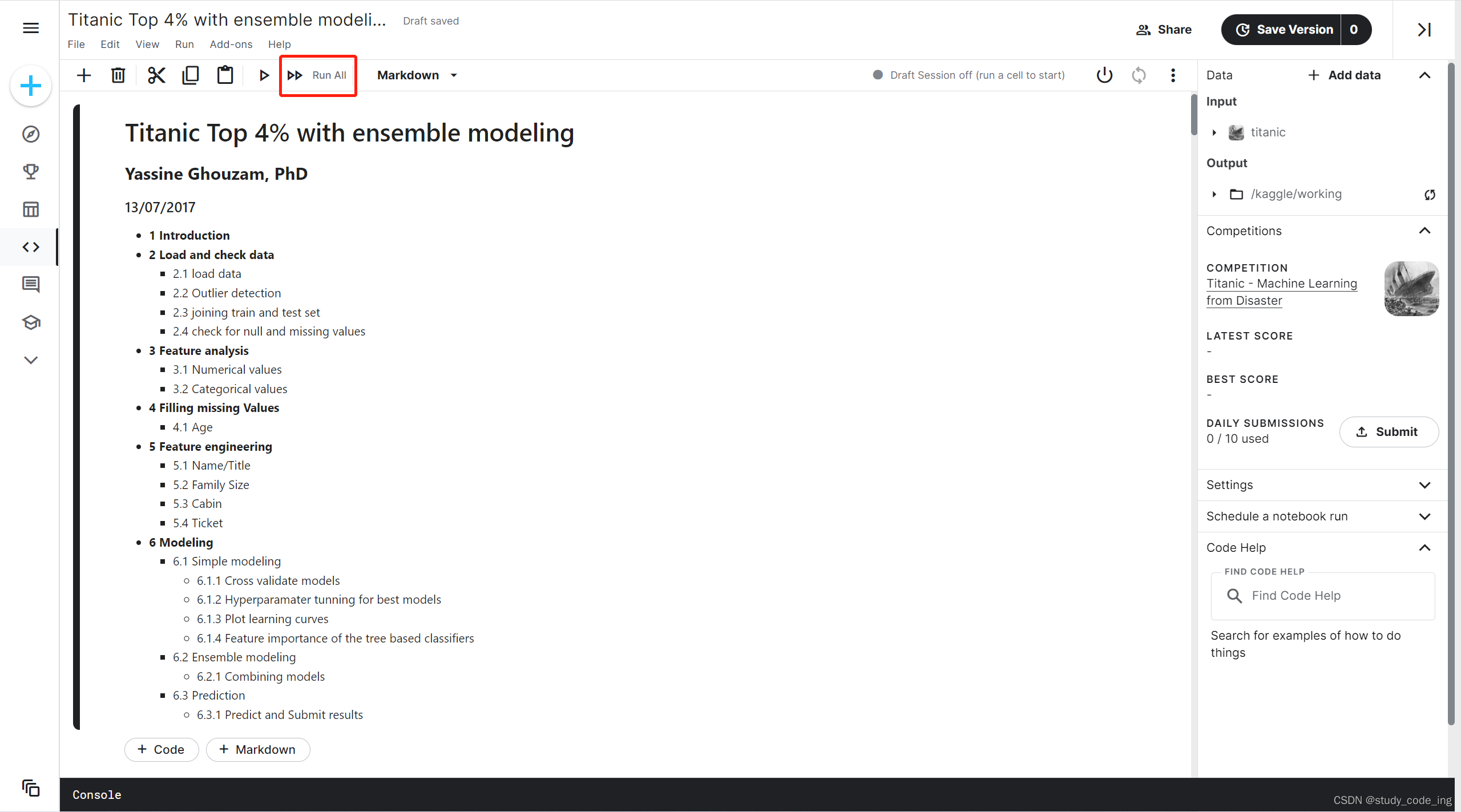
运行过程如下可参考
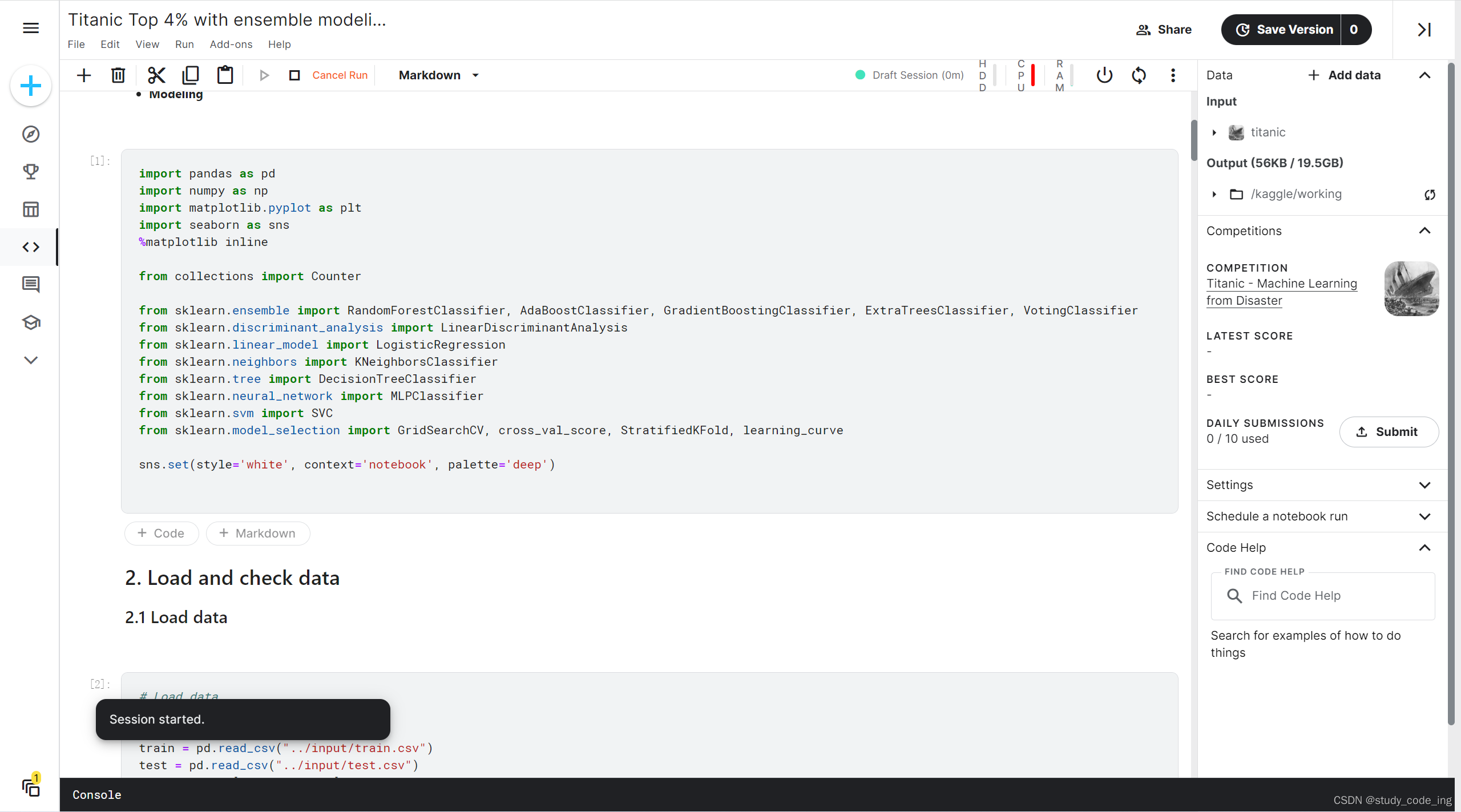
可以看到运行到的位置、结果和报错
8、在output处下载运行结果
下载结果为压缩包解压即可

三、本地运行
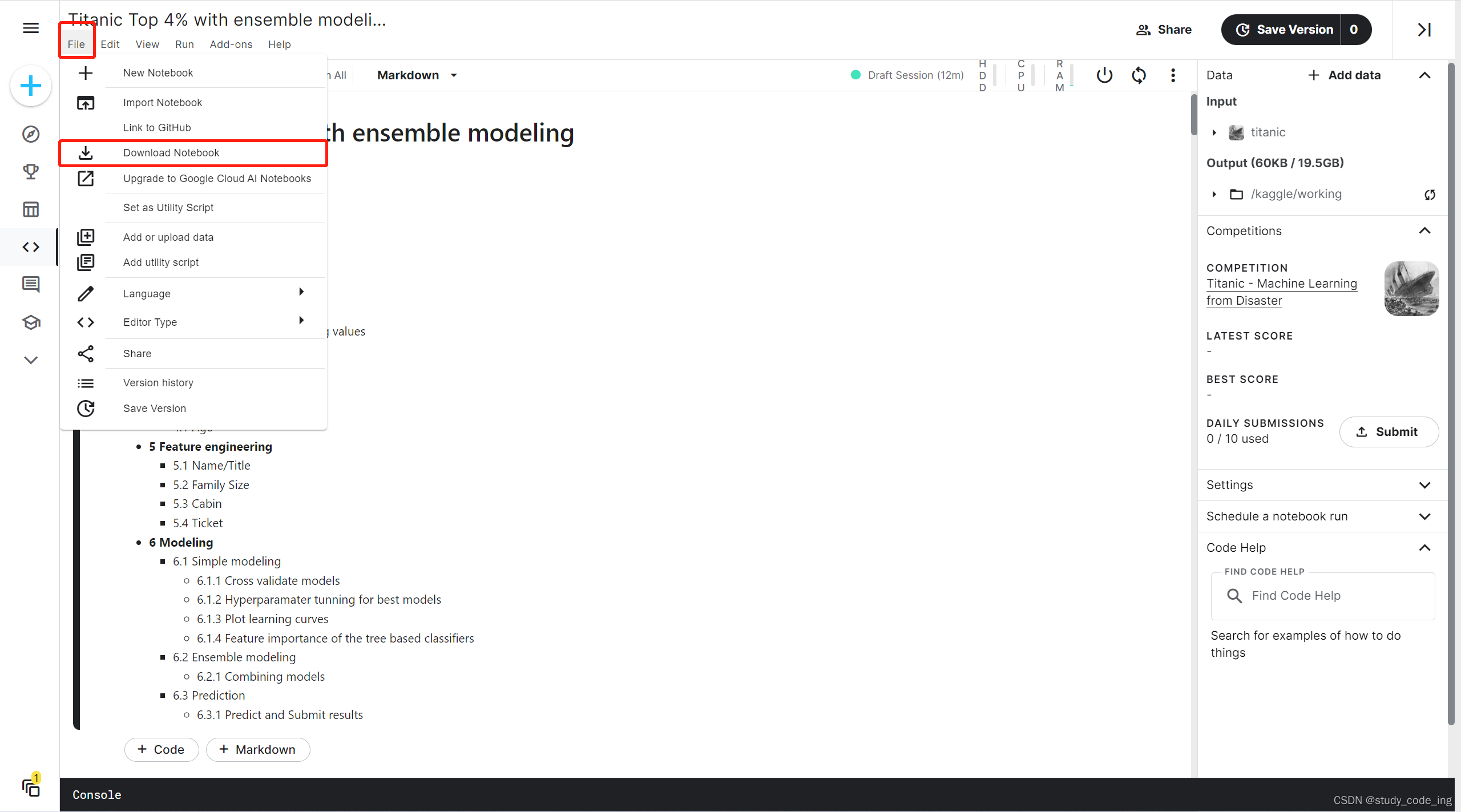
1、在编辑模式下载源代码
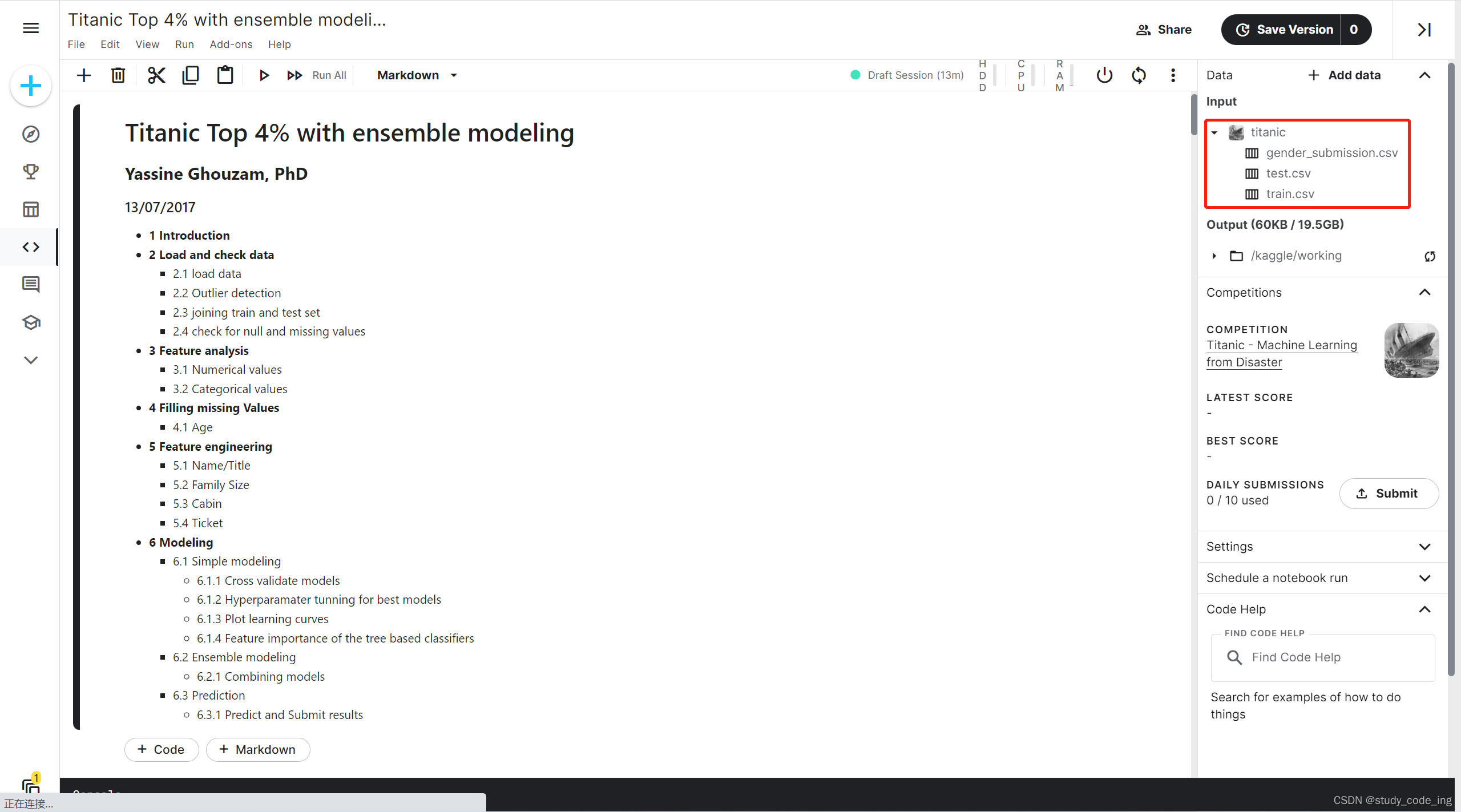
2、下载数据集
3、创建一个文件夹放置数据集及源代码
4、准备环境
1)确保python环境和pycharm安装完成
2)下载jupyter
window+R,然后输入cmd,enter回车
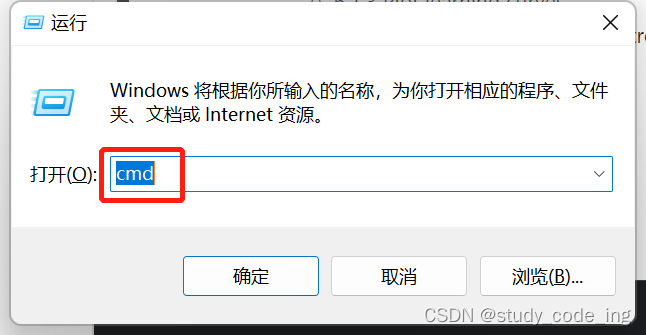
输入以下命令
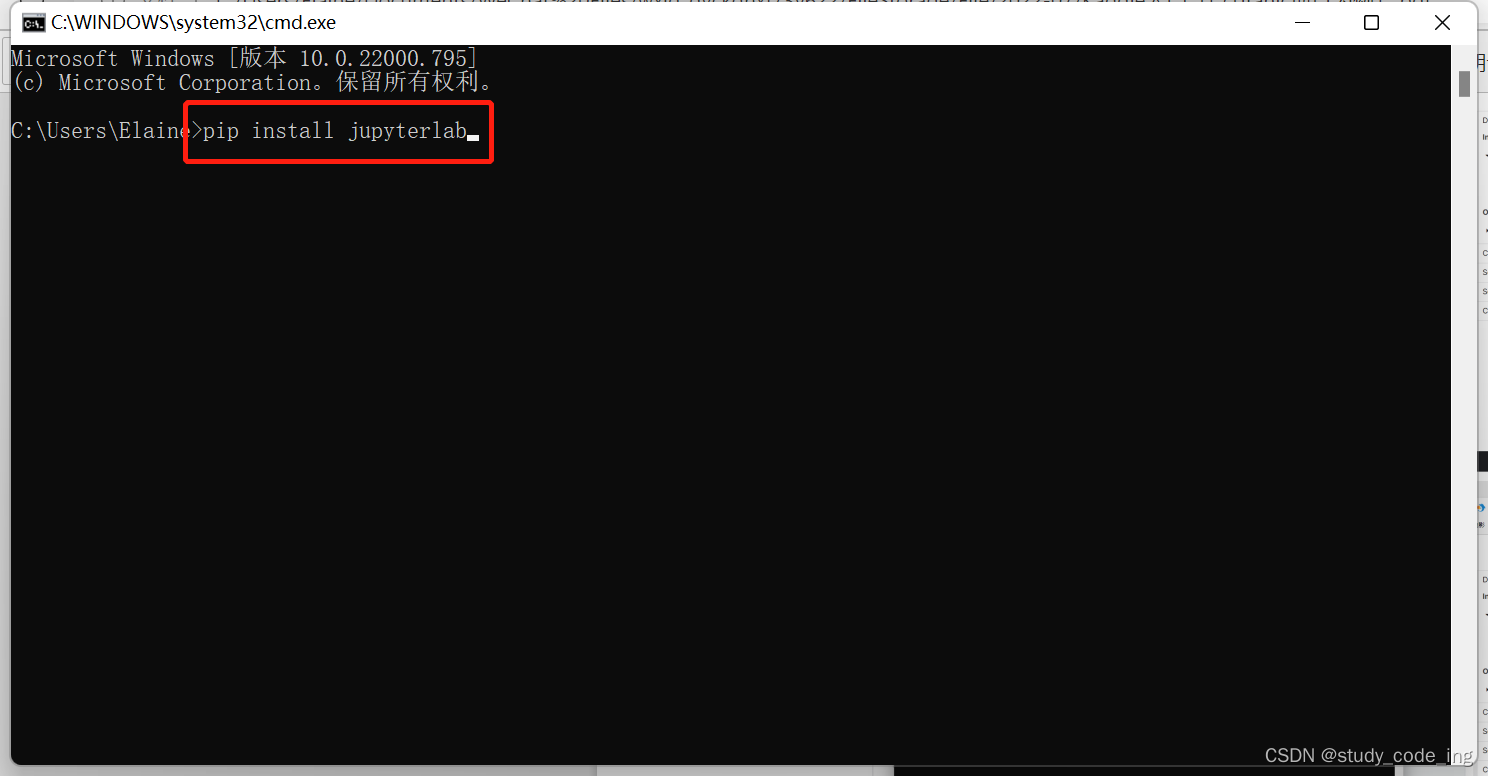
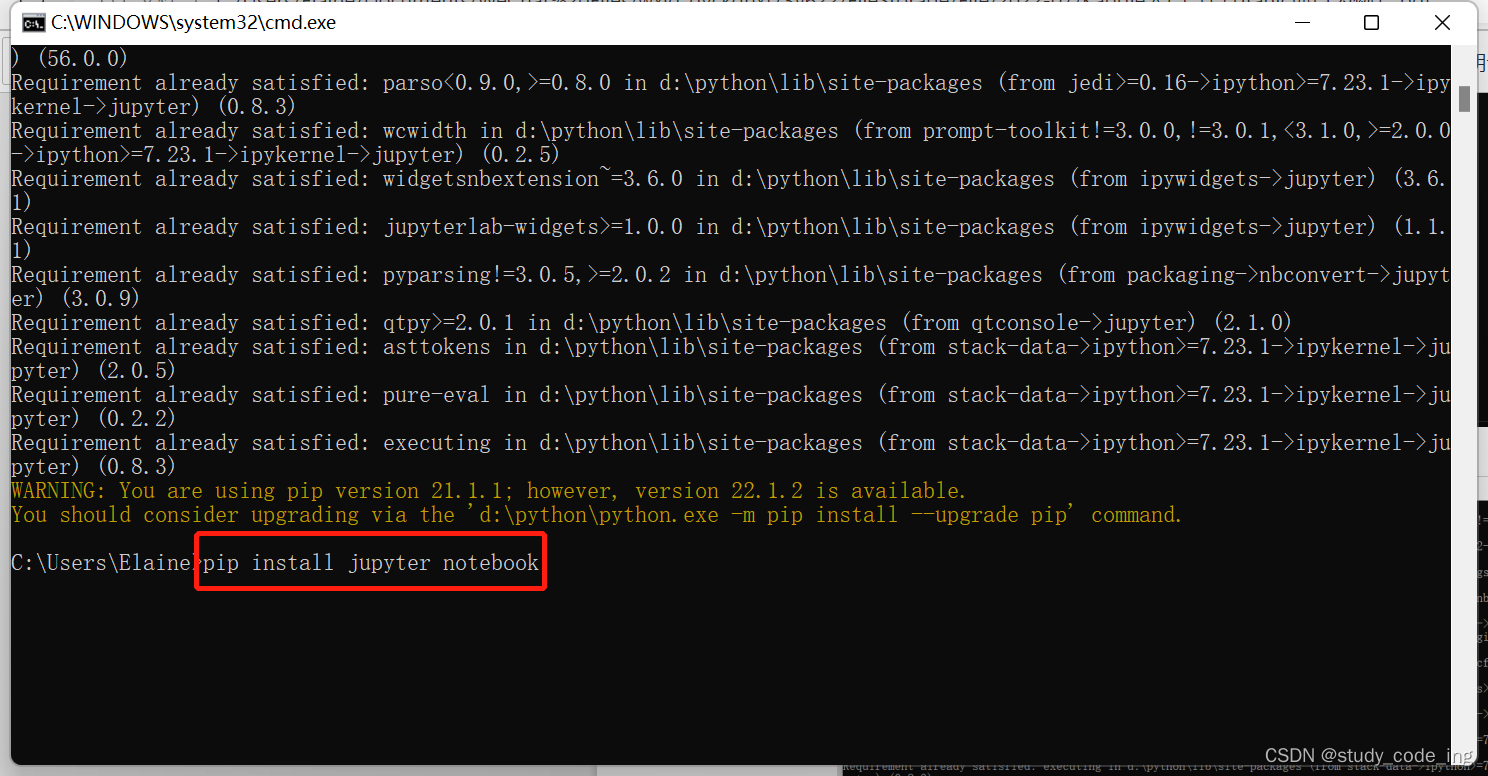
显示successful即为安装成功
3)在pycharm中打开项目文件(文件你刚刚下载新建的文件夹)
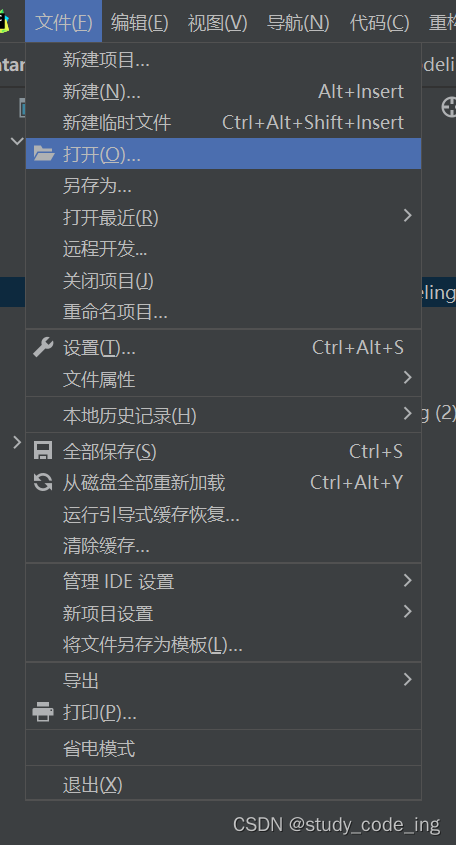
4)点击下载的源代码即可打开下载的代码
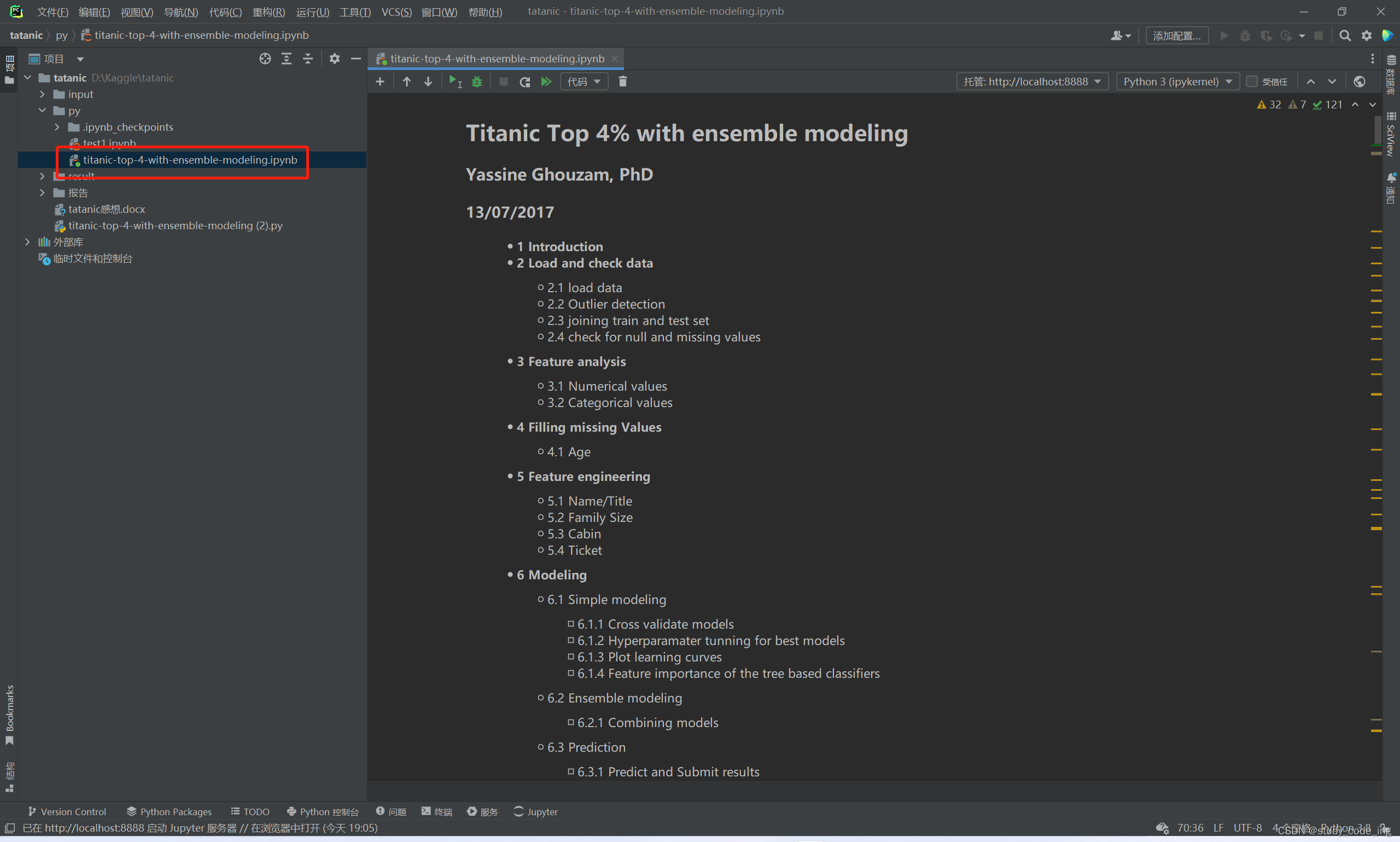
5)下载需要的库
如果库下面带有红色波浪线是没有下载的原因
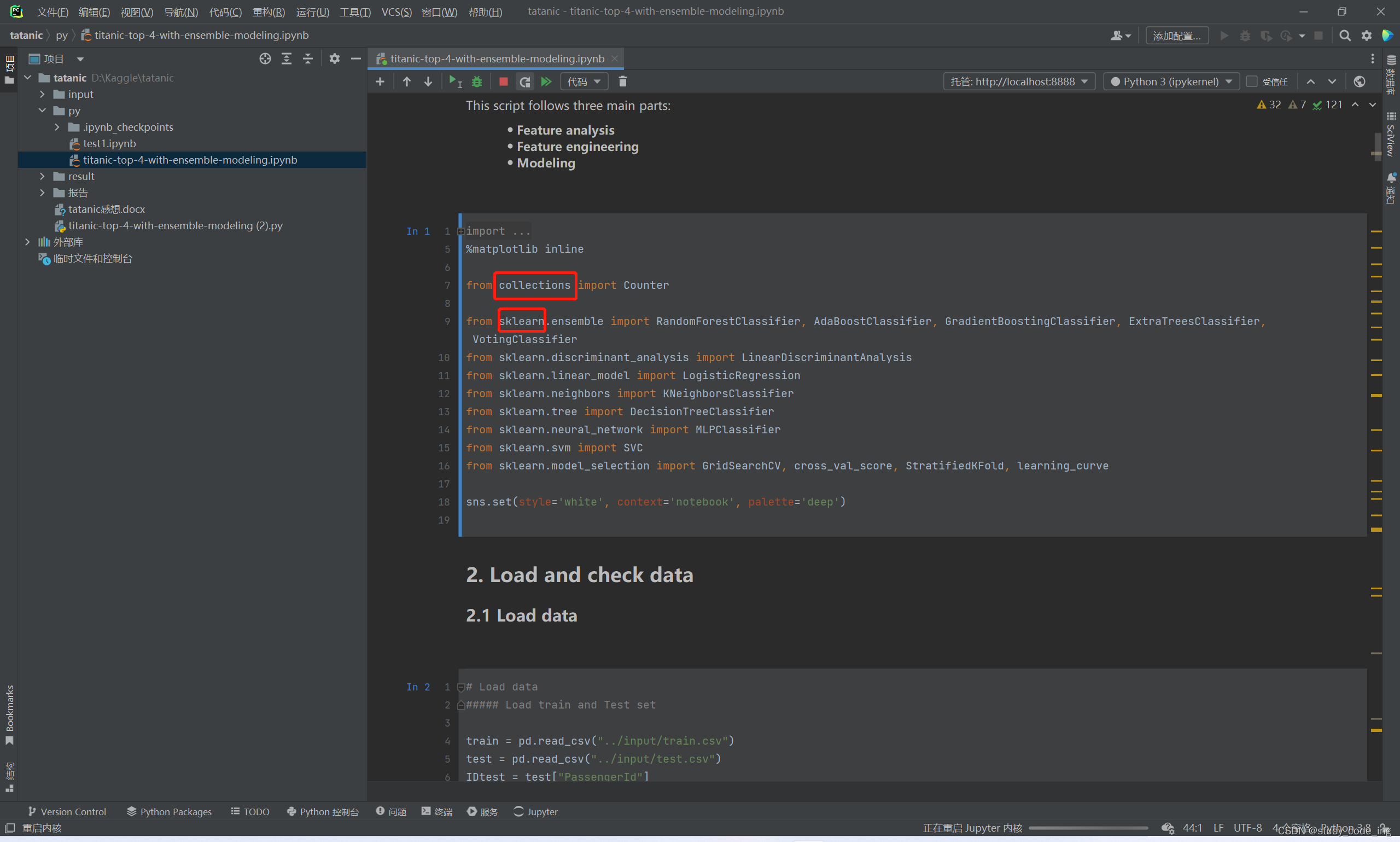
下载方法如二:
第一,鼠标放过去会显示安装,点击安装即可(一次好像只能安装一个,一起安装好像会安装失败)
第二、点文件设置
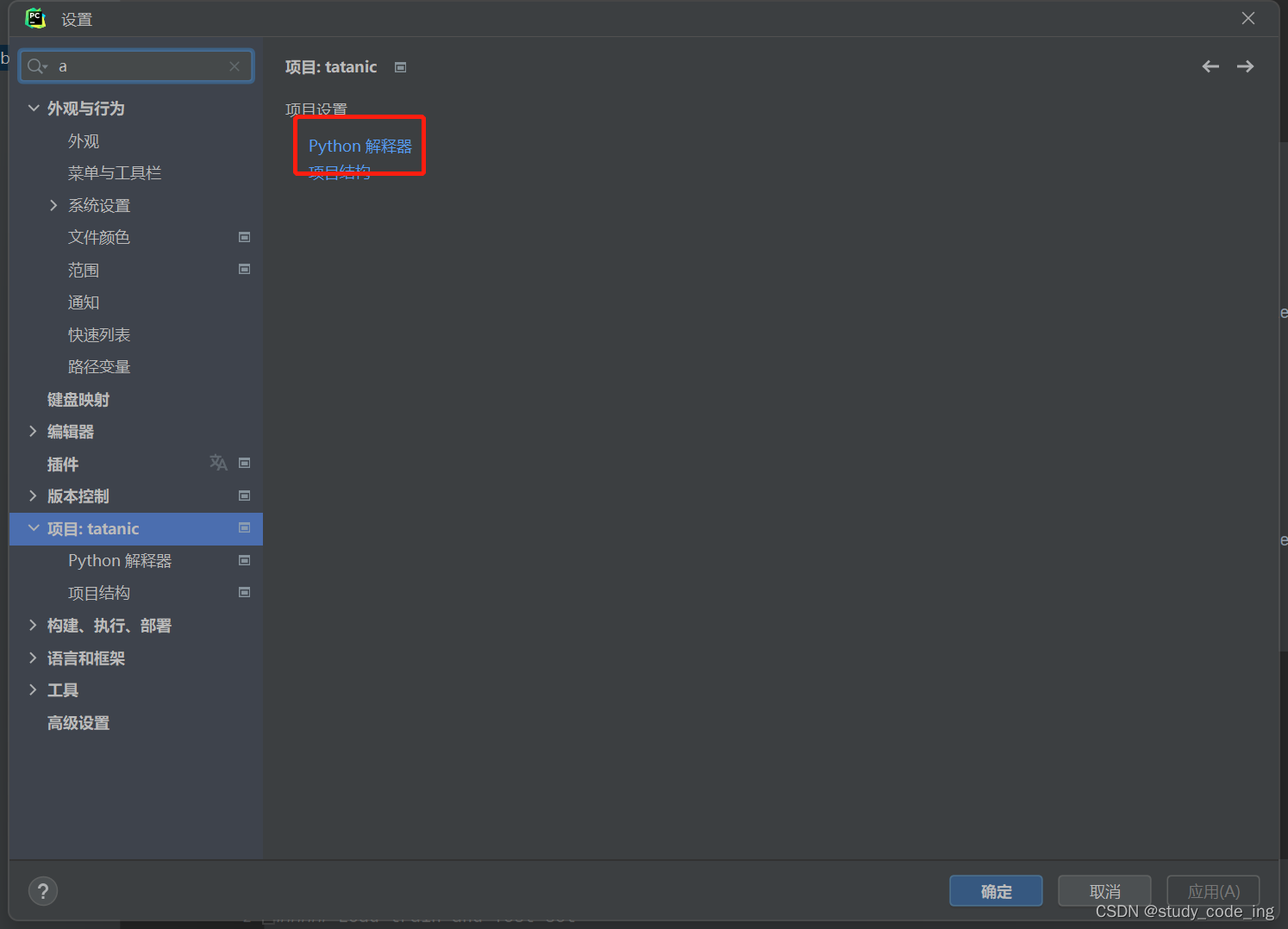
点对应的项目(此处tatanic打错,应为titanic)后带你python编辑器
点+号
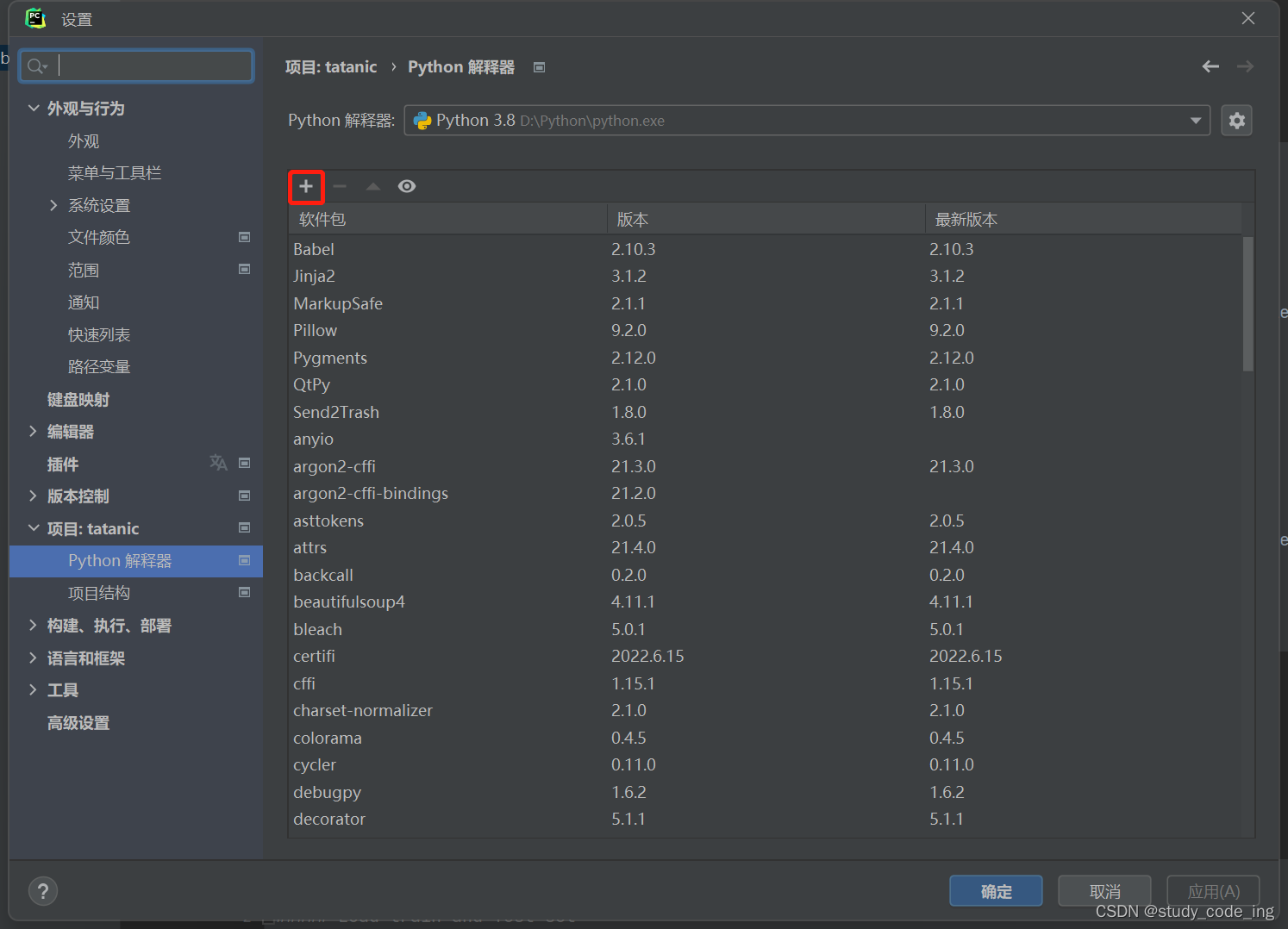
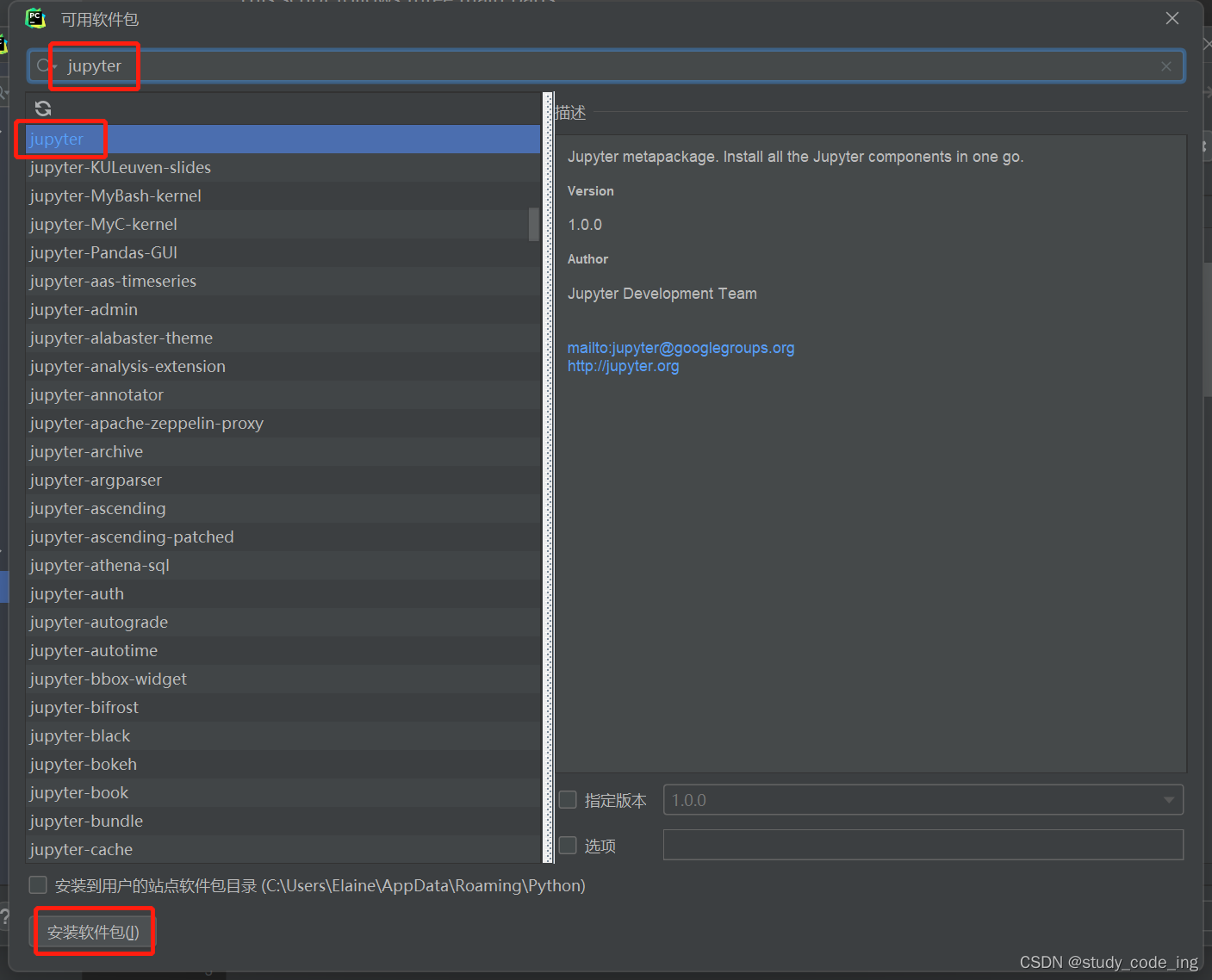
搜索需要安装的库的名称,找到对应的安装即可
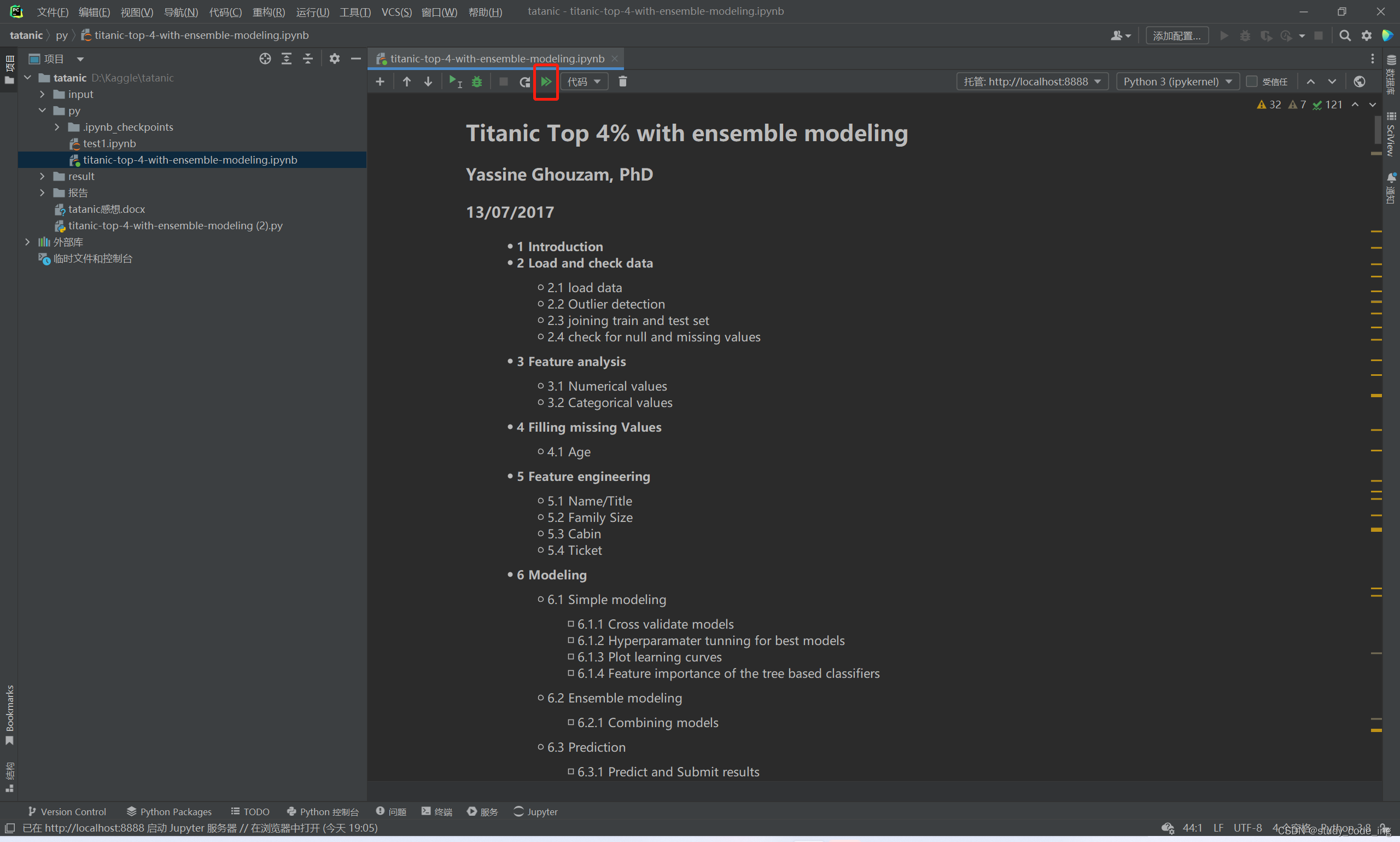
6)点击此可全部运行
也可以点击此左侧三角分布运行(shift+enter 为下一步),运行完成后可看到运行结果
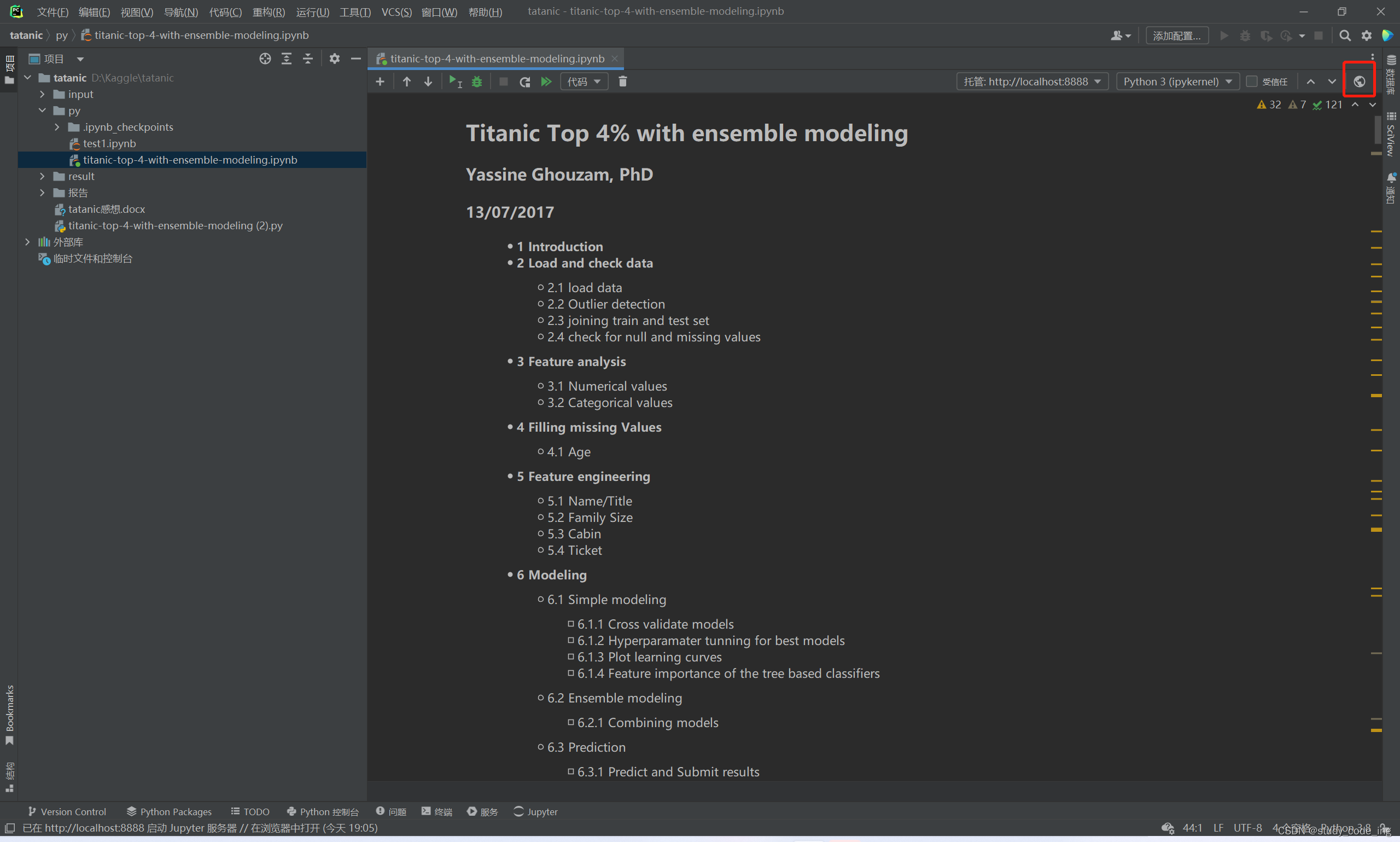
当然,这里还有一种运行方式
点击此图标,可跳转到jupyter网页运行(或者打开cmd,输入jupyter notebook也可跳转,运行完成后下载结果
四、温馨提示
1、如果运行时没有运行结果可以检查一下python的运行环境是否有问题

















 3761
3761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









