



 本文深入介绍了K近邻(KNN)算法,这是一种基于实例的学习方法,用于分类任务。通过计算新样本与已有样本之间的距离,选取最近的K个邻居并遵循多数投票原则确定类别。在CIFAR-10数据集上,展示了KNN算法的实现过程,包括数据预处理、模型构建和效果测试。通过对图像数据进行卷积和池化操作,构建了简单的神经网络模型进行分类。
本文深入介绍了K近邻(KNN)算法,这是一种基于实例的学习方法,用于分类任务。通过计算新样本与已有样本之间的距离,选取最近的K个邻居并遵循多数投票原则确定类别。在CIFAR-10数据集上,展示了KNN算法的实现过程,包括数据预处理、模型构建和效果测试。通过对图像数据进行卷积和池化操作,构建了简单的神经网络模型进行分类。
k近邻算法
参考:K-近邻算法(KNN)_自动化所副盐的博客-优快云博客
任务九 深度学习 K近邻学习_Heihei_study的博客-优快云博客
概述
K Nearest Neighbor算法又叫KNN算法K最近邻(k-Nearest Neighbor,KNN),是一种常用于分类的算法,是有成熟理论支撑的、较为简单的经典机器学习算法之一。该方法的基本思路是:如果一个待分类样本在特征空间中的k个最相似(即特征空间中K近邻)的样本中的大多数属于某一个类别,则该样本也属于这个类别,即近朱者赤,近墨者黑。显然,对当前待分类样本的分类,需要大量已知分类的样本的支持,因此KNN是一种有监督学习算法。
原理
如图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类。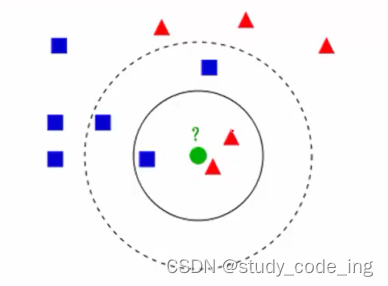
如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
从上面例子我们可以看出,k近邻的算法思想非常的简单,也非常的容易理解,该算法的原理大概意思就是怎么给新来的点如何进行归类,只要找到离它最近的k个实例,哪个类别最多即可。
三个要素
- 距离度量
- 分类决策规则
- K值的选取
k近邻算法实例实现分类(CIFAR-10)
这是一个经典的小彩色图像集,具有50000个训练数据,10000个测试数据,大小均为32*32,有10类标签(类别鲜明),目的是预测图片属于什么样类别的
CIFAR-10https://www.cs.toronto.edu/~kriz/cifar.html

计算选取点与当前点的距离(将图像对应像素点相减,最后求累加和)
深度学习(八)-CIFAR-10分类_未名湖畔的落叶的博客-优快云博客_cifar10 分类
数据处理
在处理时,因为是彩色图片,由 [R, G, B] 组成,需要使用三维,将图片转化为三维像素表示
transform = transforms.Compose([
transforms.ToTensor(), # 将数据转为 tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化
])
trainset = torchvision.datasets.CIFAR10(root="./data", train=True, download=False, transform=transform)
testset = torchvision.datasets.CIFAR10(root="./data", train=False, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)看图片信息
classes = ("airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck")
(data, label) = trainset[100]
print(classes[label], "\t", data.shape)
show((data+1)/2).resize((100, 100))模型构建
个参数可以自己设置
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.player1 = nn.Sequential( # [3, 32, 32]
nn.Conv2d(3, 6, 5), # 卷积层 [6, 28, 28]
nn.ReLU(), # 激活函数
nn.MaxPool2d(2) # 池化 [6, 14, 14]
)
self.player2 = nn.Sequential( # [6, 14, 14]
nn.Conv2d(6, 16, 5), # [16, 10, 10]
nn.ReLU(),
nn.MaxPool2d(2) # [16, 5, 5]
)
self.player3 = nn.Sequential( # 全连接层
nn.Linear(16*5*5, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
def forward(self, x): # 传播过程
x = self.player1(x)
x = self.player2(x)
x = x.view(x.size()[0], -1) # 平面展开
output = self.player3(x)
return output各层权重与偏置信息
for name, parameters in model.named_parameters():
print(name, ": ", parameters.size())效果测试
dataiter = iter(testloader) # 显示4张图片
images, labels = dataiter.next()
print("实际类别: ", " ".join("%11s"%classes[labels[j]] for j in range(4)))
show(torchvision.utils.make_grid((images+1)/2)).resize((400, 100)) # resize: 图片缩放 make_grid:将多个图片拼到一个网格预测
outputs = model(Variable(images))
_, predicted = torch.max(outputs.data, 1)
print("预测类别: ", " ".join("%11s"%classes[predicted[j]] for j in range(4)))
















 1703
1703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









