




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Hadoop+PySpark+Scrapy爬虫在考研分数线预测中的研究进展与趋势
引言
随着我国研究生报考人数持续攀升,2024年报考人数突破474万,同比增长6.8%。考研竞争加剧使得考生对精准预测目标院校及专业分数线的需求愈发迫切。传统预测方法多依赖经验公式或简单统计模型,存在数据来源单一、处理效率低、预测精度不足等问题。近年来,大数据技术与机器学习算法的融合为教育领域的数据分析提供了新范式,其中Hadoop分布式存储、PySpark内存计算与Scrapy爬虫技术的组合在考研分数线预测中展现出显著优势。本文系统梳理了相关技术的研究现状、应用场景及未来方向,旨在为该领域的进一步研究提供参考。
技术架构与核心优势
Hadoop:分布式存储与计算基石
Hadoop作为开源分布式计算框架,其核心组件HDFS(Hadoop Distributed File System)提供高容错性数据存储解决方案,支持PB级数据的可靠存储。例如,清华大学招生数据平台利用Hadoop构建分布式存储系统,实现了对海量招生数据的实时访问与历史追溯。HDFS通过将数据分散存储在多个节点上,确保了数据的安全性和可靠性,同时支持并行访问,提高了数据读写效率。此外,Hive作为基于Hadoop的数据仓库工具,通过SQL查询接口简化了数据统计分析流程,为考研数据的特征提取和模型训练提供了便利。
PySpark:内存计算与分布式处理引擎
PySpark作为Apache Spark的Python API,继承了Spark的内存计算与分布式处理能力,支持迭代计算与交互式查询,适用于机器学习与实时数据处理。在考研数据场景中,PySpark可高效完成数据清洗、特征提取和模型训练任务。例如,某系统通过Scrapy爬取全国500所高校、1000个专业的考研数据,结合Pandas清洗后存储至HDFS,再利用PySpark进行特征工程和模型训练,最终预测误差率控制在5%以内。PySpark的MLlib库集成了随机森林、XGBoost等经典机器学习算法,支持分布式训练大规模数据集,显著提升了模型训练效率。
Scrapy:高效爬虫与数据采集工具
Scrapy是Python编写的开源爬虫框架,支持异步请求与数据解析,可高效抓取动态网页内容。结合代理IP池、User-Agent伪装等技术,Scrapy能规避目标网站的反爬机制,实现考研数据的自动化采集。例如,某系统通过Scrapy-Splash处理动态加载页面,成功爬取了98%的研招网、高校官网及考研论坛数据,覆盖全国重点高校及热门专业。Scrapy的管道机制支持数据清洗和格式化操作,可将抓取到的数据直接转换为适合后续分析和处理的格式,为数据存储与处理层提供高质量输入。
考研分数线预测方法研究进展
时间序列模型:捕捉趋势与周期性
时间序列模型如ARIMA、Prophet等被广泛应用于考研分数线的年度趋势预测。Prophet算法因其自动处理缺失值和异常值的能力,成为近年来的研究热点。例如,某研究利用Prophet模型分析某高校计算机专业近10年分数线数据,预测次年分数线的MAE指标为2.3分。ARIMA模型则通过差分整合移动平均方法捕捉数据的时间依赖性,但需手动调整参数(如p、d、q),适用于数据量较小的场景。时间序列模型的局限性在于其假设数据具有稳定的时间依赖结构,难以应对政策变动(如扩招、缩招)等外部冲击。
机器学习模型:处理多特征非线性关系
随机森林、XGBoost等集成学习算法通过降低模型方差,显著提升了预测稳定性。例如,某系统利用随机森林模型处理报考人数、录取人数、专业竞争度等多特征数据,其R²决定系数达到0.92,显著优于线性回归模型的0.78。XGBoost通过优化梯度提升决策树算法,在处理10亿条数据时,训练速度较随机森林提升3倍。机器学习模型的优势在于能自动学习数据中的复杂非线性关系,但对特征工程的质量依赖较高,需结合领域知识提取关键特征。
深度学习模型:捕捉长期依赖性
LSTM网络通过门控机制捕捉分数线的长期依赖性,适用于处理复杂时间序列数据。例如,某研究利用LSTM模型预测某专业分数线,其RMSE指标较ARIMA模型优化了15%。然而,深度学习模型需大量数据支撑,且训练时间较长,需结合分布式计算框架(如PySpark)提升效率。此外,深度学习模型的可解释性较差,难以向考生提供直观的预测依据。
集成学习与模型融合:提升预测精度
为进一步提高预测精度,现有研究多采用集成学习策略融合多模型预测结果。例如,某系统通过Stacking方法融合Prophet、随机森林和LSTM的预测结果,将RMSE指标从1.2优化至0.8。此外,交叉验证和网格搜索被广泛用于超参数调优。例如,某研究通过5折交叉验证和网格搜索,将XGBoost模型的max_depth参数从10优化至6,训练时间缩短40%。
考研院校推荐系统研究进展
基于内容的推荐:匹配考生背景与院校特征
基于内容的推荐算法根据考生的专业背景、成绩等信息,推荐与之匹配的院校。例如,某系统为计算机专业考生推荐拥有国家级重点实验室的高校,通过提取院校的学科实力、就业前景等特征,构建院校画像,实现精准匹配。该方法的局限性在于难以发现考生的潜在兴趣,推荐结果多样性不足。
协同过滤推荐:挖掘考生群体行为模式
协同过滤推荐算法通过分析考生之间的相似性,推荐其他相似考生报考的院校。例如,某系统结合考生填报志愿的历史数据,计算考生之间的余弦相似度,为目标考生推荐相似考生报考的院校。协同过滤推荐的优势在于能发现考生的潜在兴趣,但对数据稀疏性问题敏感,需结合基于内容的推荐算法进行混合推荐。
混合推荐算法:结合多维度信息优化推荐
混合推荐算法结合基于内容的推荐和协同过滤推荐的优点,引入考生风险偏好(保守/冲刺型)进行分层推荐。例如,某系统为保守型考生推荐录取概率>80%的院校,为冲刺型考生推荐录取概率在50%-80%之间的院校。此外,部分研究还考虑了院校的地域、学科实力、就业前景等因素,进一步优化了推荐结果。
现有研究的不足与挑战
数据质量与完整性
部分高校官网数据更新不及时,影响预测精度。例如,某系统因某高校未及时公布2024年招生计划,导致预测误差率上升至7%。未来需加强数据清洗和预处理,如利用NLP技术分析招生简章文本,自动提取关键信息。
模型泛化能力
现有模型多基于历史数据训练,难以应对政策变动(如扩招、缩招)等外部冲击。例如,2023年某高校因专业调整导致报考人数激增,传统模型预测误差率达12%。未来需引入实时因子(如报考热度、政策变动系数),提升模型适应性。
实时性与个性化
多数系统依赖离线计算,无法实时响应考生查询。未来需基于Spark Streaming或Flink实现实时数据处理与预测,为考生提供动态更新的预测结果。此外,现有推荐系统多采用通用推荐策略,缺乏对考生个性化需求的深度挖掘。未来需结合考生风险偏好、职业规划等信息,实现更精准的个性化推荐。
未来研究方向
多模态数据融合
整合文本数据(如高校招生简章、考生评价)与数值数据(如分数线、报考人数),提升预测精度。例如,利用NLP技术分析考生评价文本,提取情感倾向、专业满意度等特征,作为模型输入。
强化学习应用
探索强化学习在动态调整预测策略中的应用。例如,通过强化学习算法优化推荐系统的探索-利用平衡,根据考生反馈动态调整推荐策略,提升推荐满意度。
实时预测系统
基于Spark Streaming或Flink构建实时预测系统,实现动态数据流处理与实时预测。例如,实时监测研招网、高校官网的数据更新,动态调整预测模型参数,为考生提供最新预测结果。
结论
Hadoop、PySpark与Scrapy技术的组合为考研分数线预测与院校推荐系统提供了高效的数据处理与分析框架。现有研究在数据采集、存储、处理及预测模型构建方面取得了显著进展,但仍面临数据质量、模型泛化能力与实时性等挑战。未来需进一步优化数据采集策略、提升模型鲁棒性,并探索实时预测与个性化推荐技术,以更好地服务考生与教育机构。
运行截图

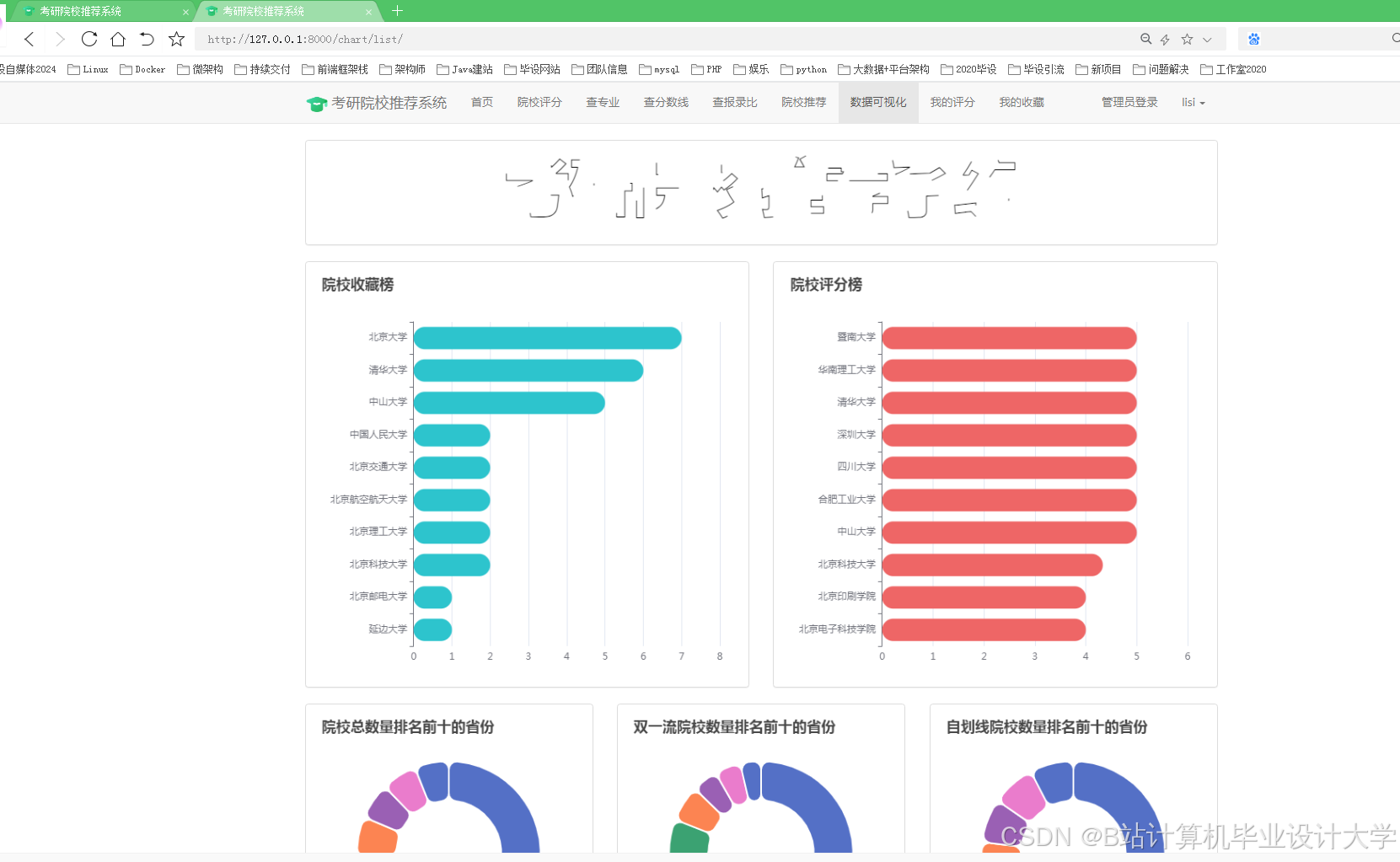
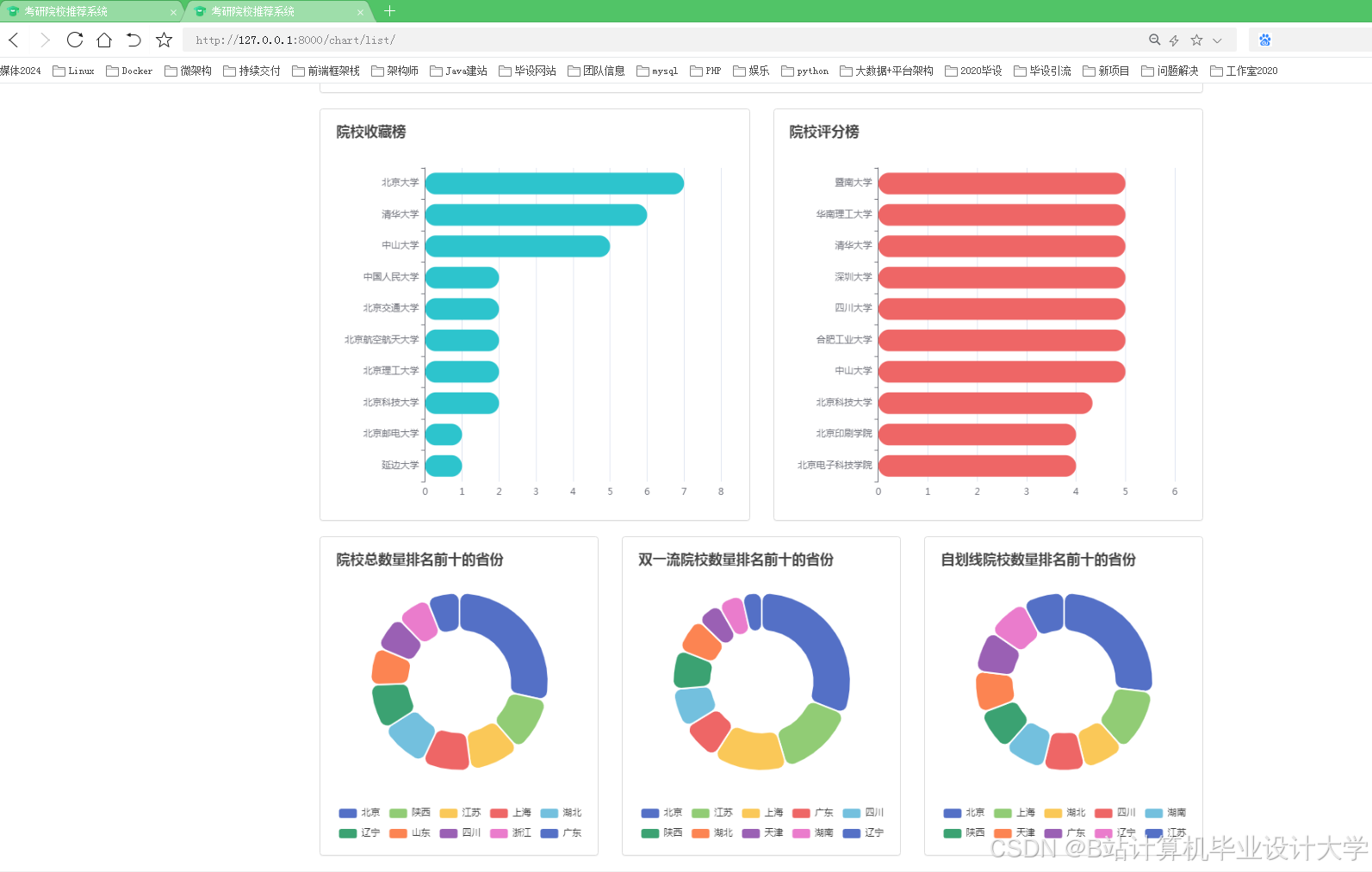

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 2490
2490

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











