



概述
Kafka 是由 LinkedIn 开发、后由Apache软件基金会维护的分布式流处理平台,采用Scala和Java编写。它本质是一个高吞吐、持久化的发布-订阅消息系统,专注于处理实时数据流(如用户行为日志、点击流等)。在收集日志的场景中,Kafka 可以作为一个消息中间件,用于接收、存储和转发大量的日志,链路,指标数据。
观测云
观测云是一款专为 IT 工程师打造的全链路可观测产品,它集成了基础设施监控、应用程序性能监控和日志管理,为整个技术栈提供实时可观察性。这款产品能够帮助工程师全面了解端到端的用户体验追踪,了解应用内函数的每一次调用,以及全面监控云时代的基础设施。此外,观测云还具备快速发现系统安全风险的能力,为数字化时代提供安全保障。
本文提到的是 Kafka 和观测云集成,即通过观测云的采集器 DataKit 采集消费 Kafka 日志,以下是使用观测云 DataKit 的 KafkaMQ 采集器进行 Kafka日志数据消费的最佳实践。
部署 Kafka
目前 DataKit 支持的 Kafka 版本有 [ version:0.8.2 ~ 3.2.0 ]。
下载 3.2.0 版本,解压即可使用。
wget https://archive.apache.org/dist/kafka/3.2.0/kafka_2.13-3.2.0.tgz
1、启动 Zookeeper 服务
$ bin/zookeeper-server-start.sh config/zookeeper.properties
2、启动 KafkaServer
$ bin/kafka-server-start.sh config/server.properties
3、创建 Topic
创建名为 testlog 的 Topic 。
$ bin/kafka-topics.sh --create --topic testlog --bootstrap-server localhost:9092
4、启动 Producer
$ bin/kafka-console-producer.sh --topic testlog --bootstrap-server localhost:9092
部署 DataKit
DataKit 是一个开源的、跨平台的数据收集和监控工具,由观测云开发并维护。它旨在帮助用户收集、处理和分析各种数据源,如日志、指标和事件,以便进行有效的监控和故障排查。DataKit 支持多种数据输入和输出格式,可以轻松集成到现有的监控系统中。
登录观测云控制台,在「集成」 - 「DataKit」选择对应安装方式,当前采用 Linux 主机部署 DataKit。
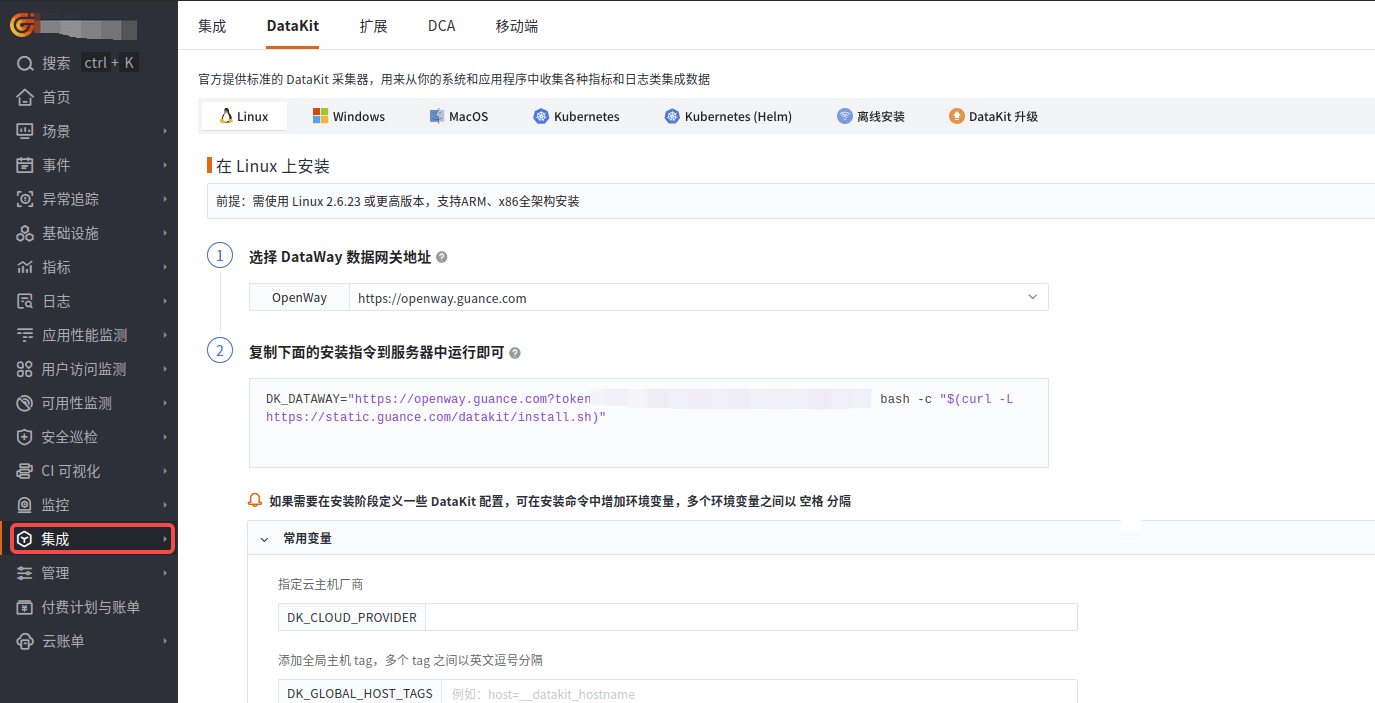
开启 KafkaMQ 采集器
进入 DataKit 安装目录下 (默认是 /usr/local/datakit/conf.d/ ) 的 conf.d/kafkamq 目录,复制 kafkamq.conf.sample 并命名为 kafkamq.conf 。
类似如下:
-rwxr-xr-x 1 root root 2574 Apr 30 23:52 kafkamq.conf
-rwxr-xr-x 1 root root 2579 May 1 00:40 kafkamq.conf.sample
调整 kafkamq 采集器配置如下:
- addrs = ["localhost:9092"],该文采集器 DataKit 和 Kafka 安装到同一台操作系统中,localhost 即可。
- kafka_version = "3.2.0",该文使用 Kafka 的版本。
- [inputs.kafkamq.custom],删除注释符号“#”。
- [inputs.kafkamq.custom.log_topic_map],删除注释符号“#”。
- "testlog"="log.p",testlog 为 Topic 的名字,log.p 为观测云 Pipeline 可编程数据处理器的日志字段提取规则配置。涉及的业务日志和 log.p 的内容详细见下面的《使用 Pipeline》。
- 其他一些配置说明:
- group_id = "datakit-group":消费者组名称,相同组内消费者共享分区消费进度。不同消费者组可独立消费同一主题。
- assignor = "roundrobin":分区轮询分配给消费者,适合组内消费者订阅相同主题列表,实现负载均衡。
注意:开启或调整 DataKit 的配置,需重启采集器(shell 下执行 datakit service -R)。
[[inputs.kafkamq]]
addrs = ["localhost:9092"]
# your kafka version:0.8.2 ~ 3.2.0
kafka_version = "3.2.0"
group_id = "datakit-group"
# consumer group partition assignment strategy (range, roundrobin, sticky)
## rate limit.
#limit_sec = 100
## sample
# sampling_rate = 1.0
## kafka tls config
# tls_enable = true
## PLAINTEXT/SASL_SSL/SASL_PLAINTEXT
# tls_security_protocol = "SASL_PLAINTEXT"
## PLAIN/SCRAM-SHA-256/SCRAM-SHA-512/OAUTHBEARER,default is PLAIN.
# tls_sasl_mechanism = "PLAIN"
# tls_sasl_plain_username = "user"
# tls_sasl_plain_password = "pw"
## If tls_security_protocol is SASL_SSL, then ssl_cert must be configured.
# ssl_cert = "/path/to/host.cert"
## -1:Offset Newest, -2:Offset Oldest
offsets=-1
## skywalking custom
#[inputs.kafkamq.skywalking]
## Required: send to datakit skywalking input.
# dk_endpoint="http://localhost:9529"
# thread = 8
# topics = [
# "skywalking-metrics",
# "skywalking-profilings",
# "skywalking-segments",
# "skywalking-managements",
# "skywalking-meters",
# "skywalking-logging",
# ]
# namespace = ""
## Jaeger from kafka. Please make sure your Datakit Jaeger collector is open!
#[inputs.kafkamq.jaeger]
## Required: ipv6 is "[::1]:9529"
# dk_endpoint="http://localhost:9529"
# thread = 8
# source: agent,otel,others...
# source = "agent"
# # Required: topics
# topics=["jaeger-spans","jaeger-my-spans"]
## user custom message with PL script.
[inputs.kafkamq.custom]
#spilt_json_body = true
#thread = 8
#storage_index = "" # NOTE: only working on logging collection
## spilt_topic_map determines whether to enable log splitting for specific topic based on the values in the spilt_topic_map[topic].
#[inputs.kafkamq.custom.spilt_topic_map]
# "log_topic"=true
# "log01"=false
[inputs.kafkamq.custom.log_topic_map]
"test_log"="log.p"
# "log01"="log_01.p"
#[inputs.kafkamq.custom.metric_topic_map]
# "metric_topic"="metric.p"
# "metric01"="rum_apm.p"
#[inputs.kafkamq.custom.rum_topic_map]
# "rum_topic"="rum_01.p"
# "rum_02"="rum_02.p"
#[inputs.kafkamq.remote_handle]
## Required
#endpoint="http://localhost:8080"
## Required topics
#topics=["spans","my-spans"]
# send_message_count = 100
# debug = false
# is_response_point = true
# header_check = false
## Receive and consume OTEL data from kafka.
#[inputs.kafkamq.otel]
#dk_endpoint="http://localhost:9529"
#trace_api="/otel/v1/traces"
#metric_api="/otel/v1/metrics"
#trace_topics=["trace1","trace2"]
#metric_topics=["otel-metric","otel-metric1"]
#thread = 8
## todo: add other input-mq
编写 Pipeline
log.p 规则内容:
data = load_json(message)
protocol = data["protocol"]
response_code = data["response_code"]
set_tag(protocol,protocol)set_tag(response_code,response_code)
group_between(response_code,[200,300],"info","status")
group_between(response_code,[400,499],"warning","status")
group_between(response_code,[500,599],"error","status")
time = data["start_time"]
set_tag(time,time)
default_time(time)
效果展示
发送业务日志样例
业务日志样例文件如下:
#info
{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":204,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-05-01T00:37:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
#error
{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":504,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-05-01T00:39:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
#warn
{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":404,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-05-01T00:38:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
日志发送命令
在 Producer 启动后,分别发送如下三条日志内容,三条日志一条为 info 级别("response_code":204),另一条为 error 级别("response_code":504),最后一条为 warn 级别日志("response_code":404)。
>{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":204,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-04-30T08:47:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
>{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":504,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-04-30T08:47:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
>{"protocol":"HTTP/1.1","upstream_local_address":"172.20.32.97:33878","response_flags":"-","istio_policy_status":null,"trace_id":"5532224c1013b9ad6da1efe88778dd64","authority":"server:1338","method":"PUT","response_code":404,"duration":83,"upstream_service_time":"83","user_agent":"Jakarta Commons-HttpClient/3.1","bytes_received":103,"downstream_local_address":"172.21.2.130:1338","start_time":"2024-04-30T08:47:11.230Z","upstream_transport_failure_reason":null,"requested_server_name":null,"bytes_sent":0,"route_name":"routes","x_forwarded_for":"10.0.0.69,10.23.0.31","upstream_cluster":"outbound|1338|svc.cluster.local","request_id":"80ac7d31-a598-4dc8-bb74-1850593f61e4","downstream_remote_address":"10.23.0.31:0","path":"/api/dimensions/items","upstream_host":"172.20.9.101:1338"}
效果
- 通过 DataKit 采集到 Kafka 的三条业务日志
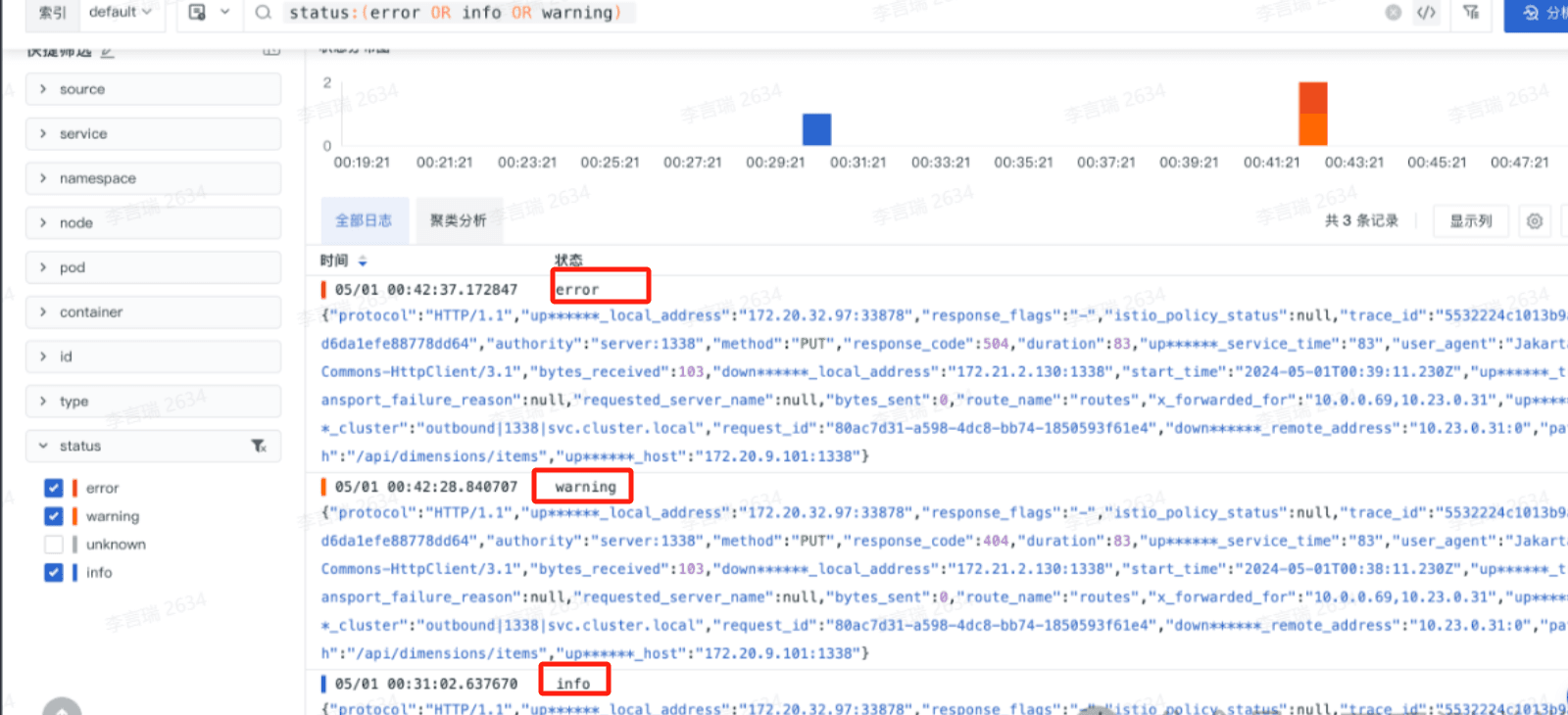
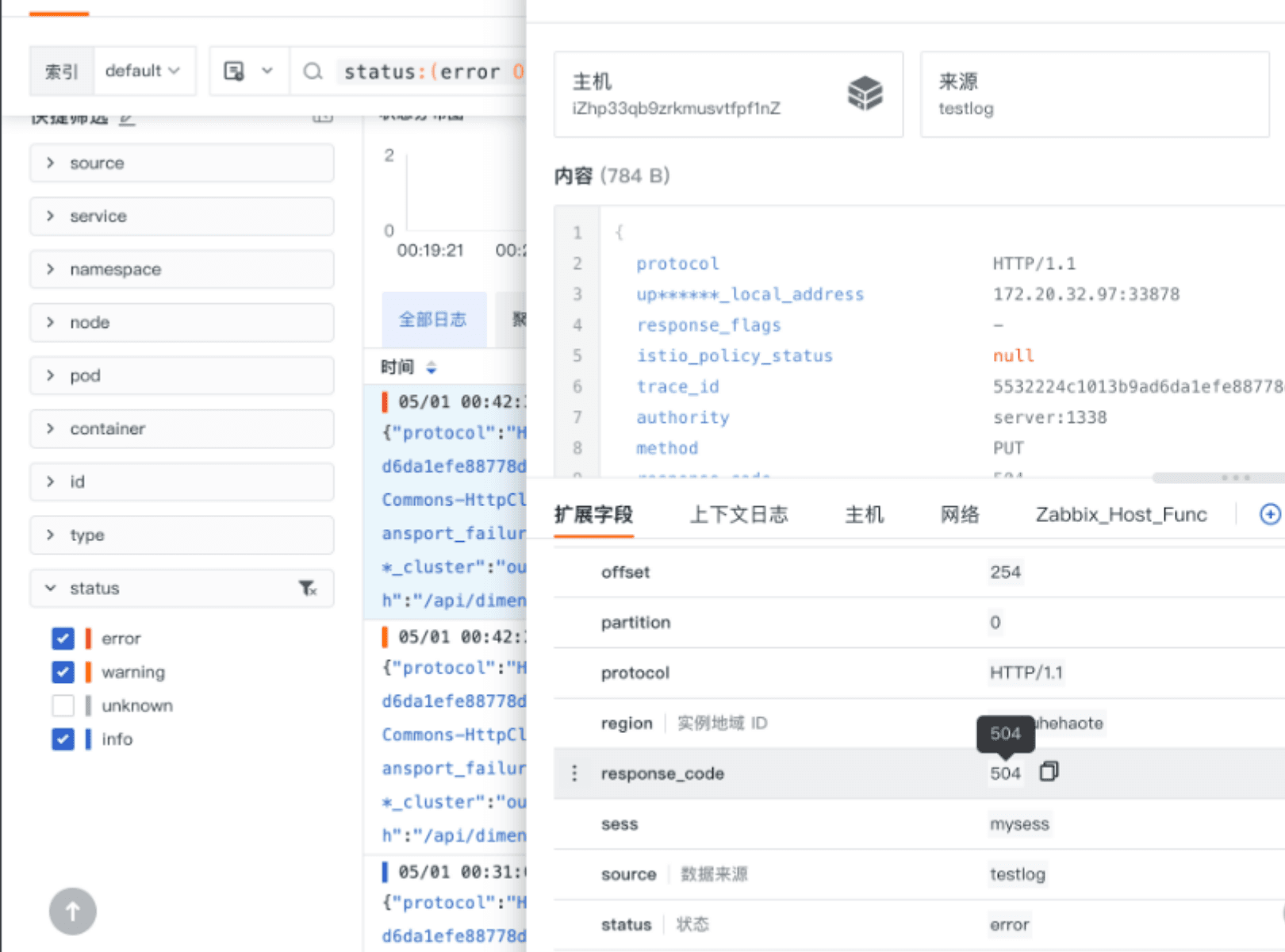
- 使用 Pipeline 对日志进行字段提取的效果展示
下图 protocol、response_code 以及 time 都是使用 Pipeline 提取后的效果。
结语
通过 Kafka 与观测云 DataKit KafkaMQ 采集器集成,实现了 Kafka 日志数据的高效采集和处理,并结合观测云的 Pipeline 功能,我们能够实时采集业务日志并进行字段提取和分类,便于后续分析和可视化;此外,DataKit 的 KafkaMQ 采集器可扩展应用于其他数据处理场景,如还支持链路(如开源 otel,skywalking,jaeger),指标,RUM 等数据的消费,这种集成方案提升了系统的可观测性,同时反映了观测云平台的开放和包容性,加速了企业的数字化转型。


















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









