




作者 | 师彬杰,Zoom 数据平台工程师
整理 | Apache DolphinScheduler 社区运营组
随着业务规模扩大和数据形态复杂化,Zoom 在调度系统上的需求也从传统的批处理调度扩展到了对流处理任务的统一管理。为此,Zoom 选择 Apache DolphinScheduler 作为底层调度框架,构建了一个支持批流一体的调度平台,并结合 Kubernetes、多云部署等现代化基础设施进行了深度定制与优化。本文将结合 Zoom 实际业务落地过程中的经验,深入解读这一系统的设计演进、关键问题应对与未来规划。
背景与挑战:从批处理向流处理拓展
在早期阶段,Zoom 的数据平台以 Spark SQL 批处理任务为主,调度任务通过 DolphinScheduler 的标准插件运行于 AWS EMR 上。
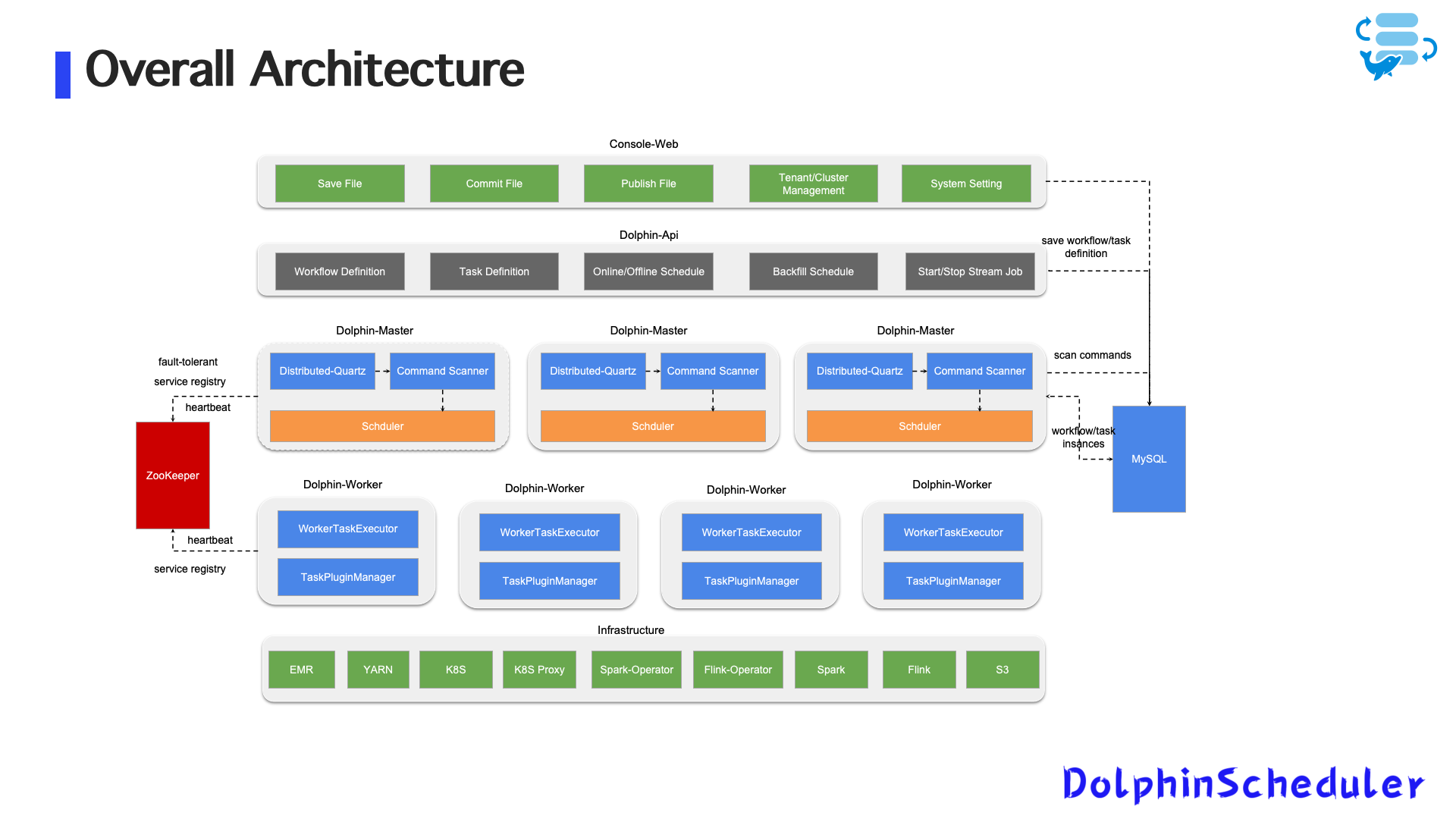
图1:早期整体架构
但随着业务需求的变化,大量实时计算需求涌现,例如:
- Flink SQL 实时指标计算;
- Spark Structured Streaming 用于日志与事件数据处理;
- 实时任务需要支持长时间运行、状态跟踪、异常恢复等能力。
这对 DolphinScheduler 提出了全新的挑战:如何让流任务像批任务一样“被调度”与“被管理”?
初始架构的限制与问题暴露
原始做法
在最初的流任务集成方案中,Zoom 使用 DolphinScheduler 的 Shell 任务插件,调用 AWS EMR API 启动流任务(如 Spark/Flink)。
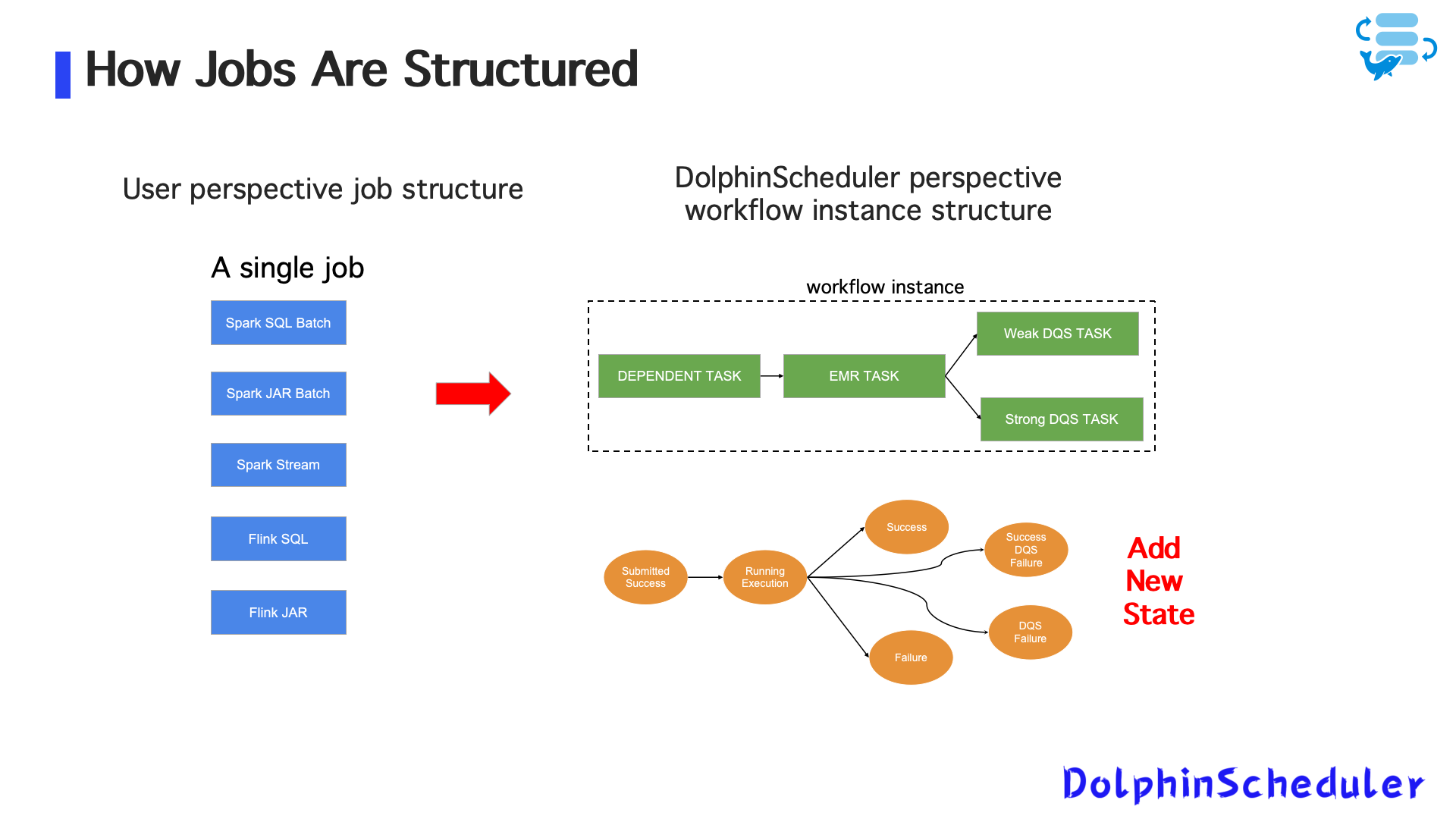
图2:早期任务结构
执行逻辑简单,但很快暴露出多个问题:
- 无状态控制:任务提交后即退出,不跟踪运行状态,导致重复提交或误判失败;
- 无任务实例与调度日志:运维排障困难,缺少日志与监控链路;
- 代码逻辑割裂:流任务与批任务使用不同逻辑,难以统一维护与演进。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3708
3708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











