






《Natural Actor-Critic》
摘要
本文提出了一种新型的强化学习架构,即自然演员-评论家(Natural Actor-Critic)。The actor 的更新通过使用Amari的自然梯度方法进行策略梯度的随机估计来实现,而评论家则通过线性回归同时获得自然策略梯度和价值函数的附加参数。本文展示了使用自然策略梯度的actor改进特别有吸引力,因为这些梯度与所选策略表示的坐标框架无关,并且比常规策略梯度更高效。评论家利用了以策略梯度兼容的函数逼近实现的特殊基函数参数化(basis function parameterization)。本文证明了多个著名的强化学习方法,如原始的演员-评论家和Bradtke的线性二次Q学习,实际上是自然演员-评论家算法的特例。实证评估表明,与之前的方法相比,该技术非常有效,并且证明了它们在仿人机器人手臂上学习控制的applicability。
1 引言
基于价值函数近似的强化学习算法在 discrete lookup table parameterization 中已经取得了巨大成功。然而,当应用于连续函数近似时,这些算法中的许多都无法泛化,并且很少能获得收敛保证[24_ Sutton_Reinforcement_Learning]。这一问题的主要原因可归结于大多数方法采用的贪婪(greedy)或ε-贪婪(ε-greedy)策略更新机制——当结合近似价值函数使用时,此类更新无法保证策略的改进[8_Neuro-dynamic_programming]。在贪婪更新过程中,价值函数中的微小误差可能导致策略的剧烈变化,而这种策略变化又会引发价值函数的显著波动。若反复进行这一过程,算法可能陷入振荡或发散。即使在简单的示例系统中,许多知名的贪婪强化学习算法也会表现出此类不良行为[6_Gradient_descent_for_RL, 8_Neuro-dynamic_programming]。
作为贪婪强化学习的替代方案,策略梯度方法(Policy Gradient Methods)被提出。即使与近似值函数结合使用,策略梯度方法也具有较强的收敛性保证,并且近期的研究结果对从采样数据中估计策略梯度建立了理论上的稳固框架[25_Policy_Gradient, 15_Actor-Critic]。然而,即使在具有较少状态的简单示例中,策略梯度方法往往表现得效率低下[14_NPG],部分原因是由于预期回报曲面上存在大面积的plateaus,在这些区域中,梯度值较小且通常并未直接指向最优解。Fig.1中的一个简单示例展示了这种情况。

类似于监督学习,基于Fisher信息度量[3_Natural_Gradient_Works_Efficiently]的最陡上升方向(被称为“natural”策略梯度)被证明比普通梯度明显会更高效。这种思路最初在[14_NPG]中以“平均自然策略梯度”的形式被提出用于强化学习,随后的初步工作[21_RL_for_Humanoid_Robotics, 4_Covariant_Policy_Search]进一步表明其本质即真正的自然策略梯度。本文在第2.2节中进一步推进了这一思路,引入了“Natural Actor-Critic”,它继承了 gradient methods 的收敛性保证。此外,在第3节中显示多种以往成功的强化学习方法均可视为这一更加通用架构的特例。本文最后通过Section4的实证评估展示了所提出方法的有效性。
2 Natural Actor-Critic
2.1 马尔可夫决策过程的符号与假设
本文假设底层的控制问题是离散时间下的MDP,其具有连续的状态集合 X = R n \mathbb{X} = \mathbb{R}^n X=Rn,和一个连续的动作集合 U = R m \mathbb{U} = \mathbb{R}^m U=Rm [8_Neuro-dynamic_programming]。MDP的假设具有一定的限制,即假设拥有 very good state information 和马尔可夫环境。不过,类似于[2_Partially_Observable_MDP]中的情况,本文所呈现的结果可能可以扩展到部分状态信息(partial state information)的问题中。
系统在初始时刻
t
=
0
t=0
t=0的状态
x
0
∈
X
\boldsymbol{x}_0 \in \mathbb{X}
x0∈X由 start-state分布
p
(
x
0
)
p(\boldsymbol{x}_0)
p(x0)生成。在某个时刻
t
t
t系统处于状态
x
t
∈
X
x_t \in \mathbb{X}
xt∈X时,执行者(actor)会根据随机参数策略
π
(
u
t
∣
x
t
)
=
p
(
u
t
∣
x
t
,
θ
)
\pi(\boldsymbol{u}_t|\boldsymbol{x}_t) = p(\boldsymbol{u}_t|\boldsymbol{x}_t, \boldsymbol{\theta})
π(ut∣xt)=p(ut∣xt,θ)选择动作
u
t
∈
U
\boldsymbol{u}_t \in \mathbb{U}
ut∈U,其中参数
θ
∈
R
N
\theta \in \mathbb{R}^N
θ∈RN,随后系统转移至新状态
x
t
+
1
\boldsymbol{x}_{t+1}
xt+1,由状态转移分布
p
(
x
t
+
1
∣
x
t
,
u
t
)
p(\boldsymbol{x}_{t+1}|\boldsymbol{x}_t,\boldsymbol{u}_t)
p(xt+1∣xt,ut)中产生。每次动作执行后,系统产生标量奖励
r
t
=
r
(
x
t
,
u
t
)
∈
R
r_t = r(\bm{x}_t, \bm{u}_t) \in \mathbb{R}
rt=r(xt,ut)∈R。本文假设策略
π
θ
\pi_{\bm{\theta}}
πθ对其参数
θ
\bm{\theta}
θ连续可微,且对于每个考虑的策略
π
θ
\pi_{\bm{\theta}}
πθ,其 state-value函数
V
π
(
x
)
V^\pi(\bm{x})
Vπ(x)和 state-action价值函数
Q
π
(
x
,
u
)
Q^\pi(\bm{x}, \bm{u})
Qπ(x,u)均存在,并定义为
V
π
(
x
)
=
E
τ
{
∑
t
=
0
∞
γ
t
r
t
∣
x
0
=
x
}
,
Q
π
(
x
,
u
)
=
E
τ
{
∑
t
=
0
∞
γ
t
r
t
∣
x
0
=
x
,
u
0
=
u
}
,
\begin{aligned} V^\pi(\bm{x}) & =E_\tau\left\{\textstyle\sum_{t=0}^{\infty} \gamma^t r_t \mid\bm{x}_0=\bm{x}\right\}, \\ Q^\pi(\boldsymbol{x}, \boldsymbol{u}) & =E_\tau\left\{\textstyle\sum_{t=0}^{\infty} \gamma^t r_t \mid \boldsymbol{x}_0=\boldsymbol{x}, \boldsymbol{u}_0=\boldsymbol{u}\right\}, \end{aligned}
Vπ(x)Qπ(x,u)=Eτ{∑t=0∞γtrt∣x0=x},=Eτ{∑t=0∞γtrt∣x0=x,u0=u},
其中
γ
∈
(
0
,
1
)
\gamma \in (0,1)
γ∈(0,1)为折扣因子,
τ
\tau
τ表示轨迹。假设存在一组基函数
ϕ
(
x
)
\bm{\phi}(\bm{x})
ϕ(x),使得状态价值函数可通过线性函数近似表示为
V
π
(
x
)
=
ϕ
(
x
)
T
v
V^{\pi}(\bm{x}) = \bm{\phi}(\bm{x})^T \bm{v}
Vπ(x)=ϕ(x)Tv。总体目标是最小化归一化期望回报
J
(
θ
)
=
E
τ
{
(
1
−
γ
)
∑
t
=
0
∞
γ
t
r
t
∣
θ
}
=
∫
X
d
π
(
x
)
∫
U
π
(
u
∣
x
)
r
(
x
,
u
)
d
x
d
u
\begin{aligned} J(\boldsymbol{\theta}) & =E_{\tau}\left\{\left.\left(1-\gamma\right)\textstyle\sum_{t=0}^{\infty}\gamma^{t}r_{t}\right|\boldsymbol{\theta}\right\} \\ & =\int_\mathbb{X}d^\pi(\boldsymbol{x})\int_\mathbb{U}\pi(\boldsymbol{u}|\boldsymbol{x})r(\boldsymbol{x},\boldsymbol{u})d\boldsymbol{x}d\boldsymbol{u} \end{aligned}
J(θ)=Eτ{(1−γ)∑t=0∞γtrt∣θ}=∫Xdπ(x)∫Uπ(u∣x)r(x,u)dxdu
其中
d
π
(
x
)
=
(
1
−
γ
)
∑
t
=
0
∞
γ
t
p
(
x
t
=
x
)
d^{\pi}(\bm{x}) = (1-\gamma)\sum_{t=0}^{\infty} \gamma^t p(\bm{x}_t = \bm{x})
dπ(x)=(1−γ)∑t=0∞γtp(xt=x)为 the discounted state distribution.
2.2 基于自然策略梯度的行动者改进
行动者-评论家(Actor-Critic)及许多其它策略迭代架构由两个步骤构成:策略评估步骤(policy evaluation step)与策略改进步骤( policy improvement step)。策略评估步骤的核心要求是有效利用经验数据。策略改进步骤则需满足以下条件:在每一步迭代中持续改进策略直至收敛,同时保证计算效率。
策略改进步骤的要求 rule out 贪婪方法,因为在现有知识水平下,无法保证近似值函数的策略改进, even on average。遵循预期的(expected)回报函数
J
(
θ
)
J(\bm{\theta})
J(θ)(其中
∇
θ
f
=
[
∂
f
/
∂
θ
1
,
…
,
∂
f
/
∂
θ
N
]
\nabla_{\boldsymbol{\theta}}f=[\partial f/ \partial\theta_{1},\ldots,\partial f/\partial\theta_{N}]
∇θf=[∂f/∂θ1,…,∂f/∂θN])的梯度
∇
θ
J
(
θ
)
\nabla_\theta J(\bm{\theta})
∇θJ(θ)表示函数
f
f
f对参数向量
θ
\bm{\theta}
θ的导数)的“Vanilla”策略梯度改进(参见如[25_Policy_Gradient, 15_Actor-Critic])经常陷入平台区域,正如[14_NPG]中所示。自然梯度
∇
~
θ
J
(
θ
)
\widetilde{\bm{\nabla}}_{\boldsymbol{\theta}}J(\bm{\theta})
∇
θJ(θ)避免了这一陷阱,这一点已在监督学习问题中得到证明3_Natural_Gradient_Works_Efficiently],并建议在强化学习中采用[14_NPG]。这些方法不是沿着参数空间中最陡的方向,而是沿着关于Fisher度量的最陡方向即
∇
~
θ
J
(
θ
)
=
G
−
1
(
θ
)
∇
θ
J
(
θ
)
,
\widetilde{\boldsymbol{\nabla}}_{\boldsymbol{\theta}} J(\boldsymbol{\theta})=\boldsymbol{G}^{-1}(\boldsymbol{\theta}) \boldsymbol{\nabla}_{\boldsymbol{\theta}} J(\boldsymbol{\theta}),
∇
θJ(θ)=G−1(θ)∇θJ(θ),
其中
G
(
θ
)
\bm{G}(\bm{\theta})
G(θ)表示Fisher信息矩阵。可以保证自然梯度与普通梯度之间的夹角永远不会超过90度,即可以确保收敛到下一个局部最优解。The “vanilla” gradient 由策略梯度定理给出(参见如[25_Policy_Gradient, 15_Actor-Critic]),
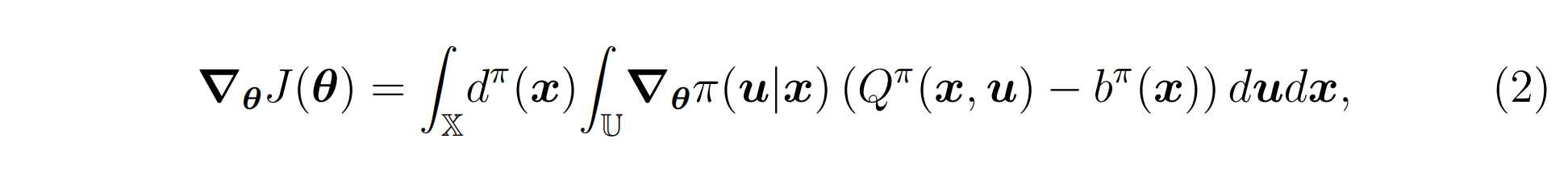
其中
b
π
(
x
)
b^\pi(\boldsymbol{x})
bπ(x)表示基线(baseline)。[25_Policy_Gradient] and [15_Actor-Critic]表明在公式(2)中项
Q
π
(
x
,
u
)
−
b
π
(
x
)
Q^\pi(\boldsymbol{x},\boldsymbol{u}) - b^\pi(\boldsymbol{x})
Qπ(x,u)−bπ(x) 可以被如下兼容函数逼近(compatible function approximation)所替代
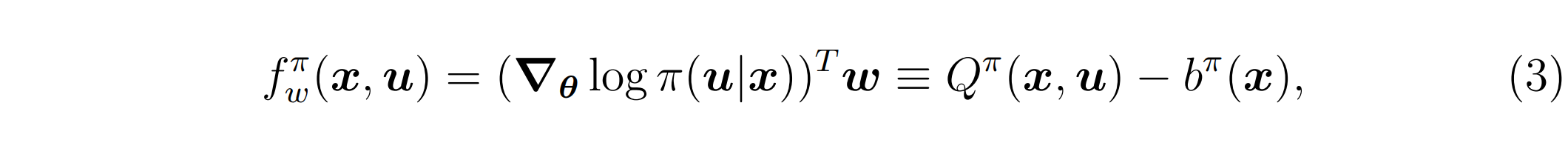
由向量
w
\bm{w}
w参数化,这种替代不会影响梯度估计的无偏性,且与基线
b
π
(
x
)
b^\pi(\bm{x})
bπ(x)的选择无关。不过,如[25_Policy_Gradient]中所提到的,当通过samples近似公式(2)时,基线仍可能有助于减少梯度估计的variance。基于公式(2)和(3),推导出策略梯度的估计(estimate)为
∇
θ
J
(
θ
)
=
∫
X
d
π
(
x
)
∫
U
π
(
u
∣
x
)
∇
θ
l
o
g
π
(
u
∣
x
)
∇
θ
l
o
g
π
(
u
∣
x
)
T
d
u
d
x
w
=
F
θ
w
.
\boldsymbol{\nabla_\theta}J(\boldsymbol{\theta})=\int_\mathbb{X}d^\pi(\boldsymbol{x})\int_\mathbb{U}\pi(\boldsymbol{u}|\boldsymbol{x})\boldsymbol{\nabla_\theta}\mathrm{log~}\pi(\boldsymbol{u}|\boldsymbol{x})\boldsymbol{\nabla_\theta}\mathrm{log~}\pi(\boldsymbol{u}|\boldsymbol{x})^Td\boldsymbol{u}d\boldsymbol{x}\:\boldsymbol{w}=F_{\boldsymbol{\theta}}\boldsymbol{w}.
∇θJ(θ)=∫Xdπ(x)∫Uπ(u∣x)∇θlog π(u∣x)∇θlog π(u∣x)Tdudxw=Fθw.
因为
∇
θ
π
(
u
∣
x
)
=
π
(
u
∣
x
)
∇
θ
log
π
(
u
∣
x
)
\boldsymbol{\nabla}_{\boldsymbol{\theta}}\pi(\boldsymbol{u}|\boldsymbol{x})=\pi(\boldsymbol{u}|\boldsymbol{x})\boldsymbol{\nabla}_{\boldsymbol{\theta}}\log\pi(\boldsymbol{u}|\boldsymbol{x})
∇θπ(u∣x)=π(u∣x)∇θlogπ(u∣x)。由于
π
(
u
∣
x
)
\pi(\boldsymbol{u}|\boldsymbol{x})
π(u∣x) 是由用户选择的,即使在采样数据中,积分
F
(
θ
,
x
)
=
∫
U
π
(
u
∣
x
)
∇
θ
log
π
(
u
∣
x
)
∇
θ
log
π
(
u
∣
x
)
T
d
u
F(\boldsymbol{\theta},\boldsymbol{x})=\int_\mathbb{U}\pi(\boldsymbol{u}|\boldsymbol{x})\boldsymbol{\nabla}_{\boldsymbol{\theta}}\log\pi(\boldsymbol{u}|\boldsymbol{x})\boldsymbol{\nabla}_{\boldsymbol{\theta}}\log\pi(\boldsymbol{u}|\boldsymbol{x})^Td\boldsymbol{u}
F(θ,x)=∫Uπ(u∣x)∇θlogπ(u∣x)∇θlogπ(u∣x)Tdu可以在不实际执行所有动作的情况下进行解析或实验评估。值得注意的是,baseline并没有出现在公式(4)中,因为它被积分消去,因此无需选择这一开放参数的最优值。尽管如此,估计
F
θ
=
∫
X
d
π
(
x
)
F
(
θ
,
x
)
d
x
F_{\boldsymbol{\theta}}=\int_{\mathbb{X}}d^{\pi}(\boldsymbol{x})F(\boldsymbol{\theta},\boldsymbol{x})d\bm{x}
Fθ=∫Xdπ(x)F(θ,x)dx仍然很昂贵,因为
d
π
(
x
)
d^\pi(\bm{x})
dπ(x)是未知的。不过,当研究公式(4)中矩阵
F
θ
F_{\boldsymbol{\theta}}
Fθ的意义时,方程(4)对策略梯度有更多令人惊讶的启发。Kakade[14_NPG]认为
F
(
θ
,
x
)
F(\boldsymbol{\theta},\boldsymbol{x})
F(θ,x)是状态
x
\boldsymbol{x}
x 的 point Fisher information matrix,并且
F
(
θ
)
=
∫
X
d
π
(
x
)
F
(
θ
,
x
)
d
x
F(\boldsymbol{\theta})=\int_\mathbb{X}d^\pi(\boldsymbol{x})F(\bm{\theta},\boldsymbol{x})d\bm{x}
F(θ)=∫Xdπ(x)F(θ,x)dx,因此,表示一个加权的 “average Fisher information matrix” [14_NPG]。不过,经过进一步研究,本文在附录A中证明了
F
θ
F_{\bm{\theta}}
Fθ实际上是真正的Fisher信息矩阵(point Fisher information matrices),不必将其解释为点Fisher信息矩阵的“average”。
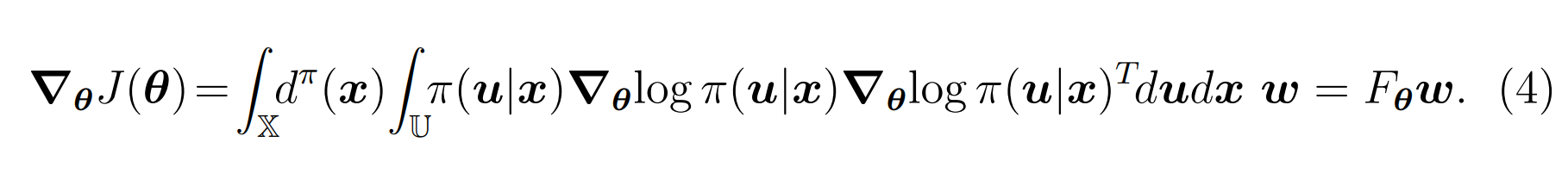
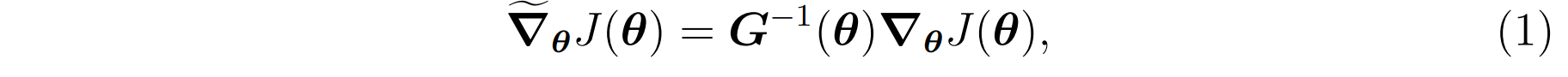
结合公式(4)和(1),则自然梯度可计算为
∇
~
θ
J
(
θ
)
=
G
−
1
(
θ
)
F
θ
w
=
w
,
\widetilde{\boldsymbol{\nabla}}_{\boldsymbol{\theta}}J(\boldsymbol{\theta})=G^{-1}(\boldsymbol{\theta})F_{\bm{\theta}}\boldsymbol{w}=\bm{w},
∇
θJ(θ)=G−1(θ)Fθw=w,
因为
F
θ
=
G
(
θ
)
F_{\bm{\theta}}=G(\bm{\theta})
Fθ=G(θ)(参见附录A)。因此,仅需估计
w
\bm{w}
w而无需计算
G
(
θ
)
G(\bm{\theta})
G(θ)。由此得到的策略改进step为
θ
i
+
1
=
θ
i
+
α
w
\boldsymbol{\theta}_{i+1} = \boldsymbol{\theta}_i + \alpha\boldsymbol{w}
θi+1=θi+αw,其中
α
\alpha
α表示学习率。
以下是自然策略梯度值得关注的几个性质:
- 保证收敛到局部最小值,与传统梯度相同。[3_Natural_Gradient_Works_Efficiently]
- 通过选择参数空间中更加直接的通向最优解的路径,自然梯度在实证观察中收敛速度更快,且避免了“vanilla gradients”的过早收敛问题(参见图1)。
- 自然策略梯度具有协变性,即其方向独立于策略参数的坐标系选择(参见第3.1节)。
- 由于自然梯度通过解析方法消除了随机策略(包括 function approximator 的基线)的影响,与“vanilla gradients”相比,其梯度估计所需的数据量更少。
2.3 使用兼容性策略评估的评论家估计
The critic 评估当前策略
π
\pi
π,以提供actor改进的basis,即策略参数的变化
Δ
θ
\Delta \boldsymbol{\theta}
Δθ。

由于本文关注自然策略梯度更新
Δ
θ
=
α
w
\Delta \boldsymbol{\theta} = \alpha\boldsymbol{w}
Δθ=αw,于是希望在这种情况下采用公式(3)中的兼容函数近似
f
w
π
(
x
,
u
)
f_{\boldsymbol{w}}^{\pi}(\boldsymbol{x}, \boldsymbol{u})
fwπ(x,u)。在这一点上,一个最重要的观察结果是,兼容函数逼近
f
w
π
(
x
,
u
)
f^\pi_w(x,u)
fwπ(x,u)关于动作分布来说是 mean-zero,即,
∫
U
π
(
u
∣
x
)
f
w
π
(
x
,
u
)
d
u
=
w
T
∫
U
∇
θ
π
(
u
∣
x
)
d
u
=
0
,
\int_{\mathbb{U}} \pi(\boldsymbol{u}|\boldsymbol{x}) f^\pi_{\boldsymbol{w}}(\boldsymbol{x}, \bm{u}) d\boldsymbol{u} = \bm{w}^T \int_{\mathbb{U}} \bm{\nabla_\theta} \pi(\boldsymbol{u}|\boldsymbol{x})d\boldsymbol{u} = 0,
∫Uπ(u∣x)fwπ(x,u)du=wT∫U∇θπ(u∣x)du=0,
因为
∫
U
π
(
u
∣
x
)
d
u
=
1
\int_{\mathbb{U}} \pi(\boldsymbol{u}|\boldsymbol{x}) d\boldsymbol{u} = 1
∫Uπ(u∣x)du=1,对
θ
\theta
θ求导得到
∫
U
∇
θ
π
(
u
∣
x
)
d
u
=
0
\int_{\mathbb{U}} \boldsymbol{\nabla}_{\bm{\theta}}\pi(\bm{u}|\bm{x}) d\boldsymbol{u} = \mathbf{0}
∫U∇θπ(u∣x)du=0。因此,
f
w
π
(
x
,
u
)
f^{\pi}_{w}(\boldsymbol{x},\boldsymbol{u})
fwπ(x,u) 通常表示优势函数
A
π
(
x
,
u
)
=
Q
π
(
x
,
u
)
−
V
π
(
x
)
A^{\pi}(\bm{x},\bm{u})=Q^{\pi}(\boldsymbol{x},\boldsymbol{u})-V^{\pi}(\boldsymbol{x})
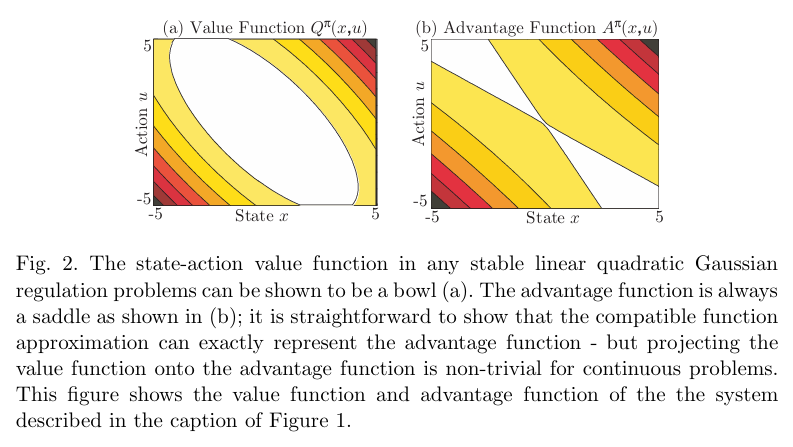
Aπ(x,u)=Qπ(x,u)−Vπ(x)。Advantage function 与 state-action value function 之间的本质区别展示在Figure2中。
若无价值函数的知识(knowledge),优势函数无法通过类似TD的自举方式学习,因为TD的核心在于比较相邻状态的价值
V
π
(
x
)
V^{\pi}(\boldsymbol{x})
Vπ(x)——而这一价值(value)已在优势函数
A
π
(
x
,
u
)
A^{\pi}(\boldsymbol{x}, \boldsymbol{u})
Aπ(x,u)中被减去。因此,仅依赖兼容函数近似器的类TD自举方法不可行。
作为替代方案,[25_Policy_Gradient, 15_Actor-Critic]建议从 action value function 的无偏估计 Q ^ π ( x , u ) \hat{Q}^\pi(\boldsymbol{x}, \boldsymbol{u}) Q^π(x,u)(例如,通过 roll-outs 获得并利用最小二乘法最小化 ( f w (f_{\boldsymbol{w}} (fw与 Q ^ π \hat{Q}^{\pi} Q^π之间的差异)来逼近 f w π ( x , u ) f_w^\pi(\boldsymbol{x}, \boldsymbol{u}) fwπ(x,u)。尽管理论上可行,但需注意该方法隐含了一个函数逼近问题:函数逼近器的参数化仅覆盖训练数据的一个极小(much smaller)子空间——例如试想用直线逼近一个二次函数。在实践中,此类逼近的结果高度依赖训练数据的分布,因此具有不可接受的高方差——例如:仅用抛物线的右分支、左分支或两侧数据拟合直线,(则结果差异显著)。
此外,在连续状态空间中,一种状态(除了单一的起始状态)几乎不会出现两次;因此,只能获得
Q
π
(
x
,
u
)
Q^\pi(\boldsymbol{x}, \boldsymbol{u})
Qπ(x,u) 的无偏估计
Q
^
π
(
x
,
u
)
\hat{Q}^\pi(\boldsymbol{x}, \boldsymbol{u})
Q^π(x,u)。这意味着需要将 state-action value estimates
Q
^
π
(
x
,
u
)
\hat{Q}^\pi(\boldsymbol{x}, \boldsymbol{u})
Q^π(x,u)投影到优势函数
A
π
(
x
,
u
)
A^\pi(\boldsymbol{x}, \boldsymbol{u})
Aπ(x,u)上。这种投影必须通过平均化去除状态值的偏移。例如,对于 linear quadratic regulation,可以直观证明优势函数呈鞍形,而 state-action value function 呈碗状——因此需要将碗状曲面投影到鞍状曲面上;两者如Figure2所示。
在此情况下,数据分布对投影(结果)具有显著(drastic)影响。
为解决这一问题,本文观察到可以用 advantage function 和 state-value function 来表达贝尔曼方程(例如见[5_Advantage_Updating])
Q
π
(
x
,
u
)
=
A
π
(
x
,
u
)
+
V
π
(
x
)
=
r
(
x
,
u
)
+
γ
∫
X
p
(
x
′
∣
x
,
u
)
V
π
(
x
′
)
d
x
′
.
Q^\pi(\boldsymbol{x}, \boldsymbol{u})=A^\pi(\boldsymbol{x}, \boldsymbol{u})+V^\pi(\boldsymbol{x})=r(\boldsymbol{x}, \boldsymbol{u})+\gamma \int_{\mathbb{X}} p\left(\boldsymbol{x}^{\prime} \mid \boldsymbol{x}, \boldsymbol{u}\right) V^\pi\left(\boldsymbol{x}^{\prime}\right) d \boldsymbol{x}^{\prime}.
Qπ(x,u)=Aπ(x,u)+Vπ(x)=r(x,u)+γ∫Xp(x′∣x,u)Vπ(x′)dx′.

















 1572
1572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









