



「打通“生成模型”与“强化学习”的边界」
作者|深蓝学院
点击加入|16类交流群
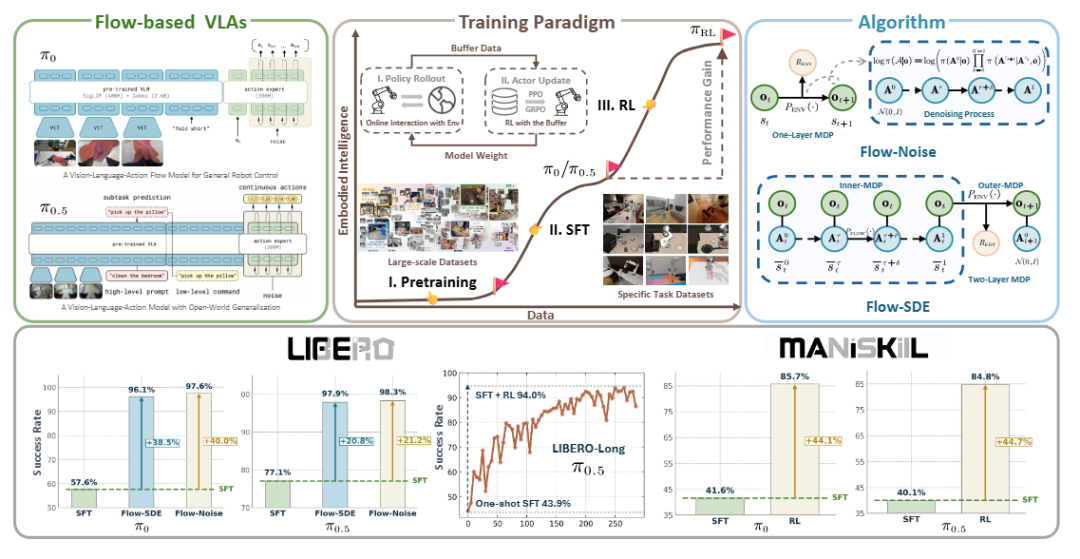
近年来,基于流匹配的VLA模型(如π0, π0.5)已成为机器人领域的前沿方向。
这类模型能以极简方式建模多峰分布,生成高维、平滑的连续动作序列,在复杂操控任务中展现出显著潜力。
然而,VLA模型的训练严重依赖大规模、高质量的人类演示数据,其收集与标注成本高、周期长。强化学习可通过环境交互自主探索与迭代,有望降低对演示数据的依赖,并进一步提升模型性能上限。
目前,针对流匹配VLA的强化学习方法仍较为缺乏,主流研究多集中于自回归架构的VLA(如OpenVLA)。其核心挑战在于:流匹配模型通过迭代去噪生成动作,难以直接计算动作的对数似然,而这正是PPO、GRPO等策略梯度算法更新的关键。
在此背景下,清华、北大、CMU等多个国内外知名团队,共同提出了πRL——让 π 系列模型第一次具备了在线强化学习(Online RL)能力。

为深入解析这一突破性工作,12 月 9 日 20:00,我们特别邀请到 πRL 论文的第一作者——北京大学的陈康博士,带来一场深度技术分享。
提前加入交流群,获取公开课课件,并与同仁们深入探讨
两种创新方案
-
Flow-Noise:在流匹配的去噪过程中引入可学习噪声网络
把原本确定性的采样过程转化为离散时间的马尔可夫决策过程(MDP),从而获得精确的动作似然估计;
-
Flow-SDE:通过ODE→SDE 转换,将去噪方程改写为随机微分方程
在保持分布一致的前提下引入探索性噪声,构建了内外双层 MDP,使模型能在“生成”和“交互”两个层面同时学习。
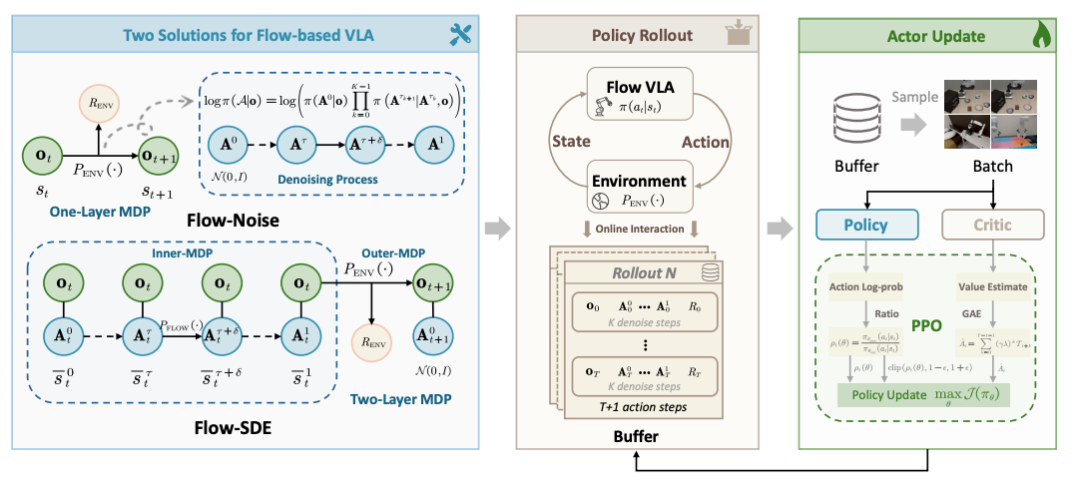
通过这两种机制,πRL 实现了让“流模型”真正能在环境中以 RL 方式自我优化的能力。
关键成果显示
-
在LIBERO评测中,仅用少量演示数据结合RL,π0与π0.5模型成功率均提升至98%左右,大幅超越全量数据监督训练的结果。
-
在高保真仿真环境 ManiSkill中,πRL 同样取得突破:模型成功率提升超过一倍,并展现出优秀的泛化性与执行效率。
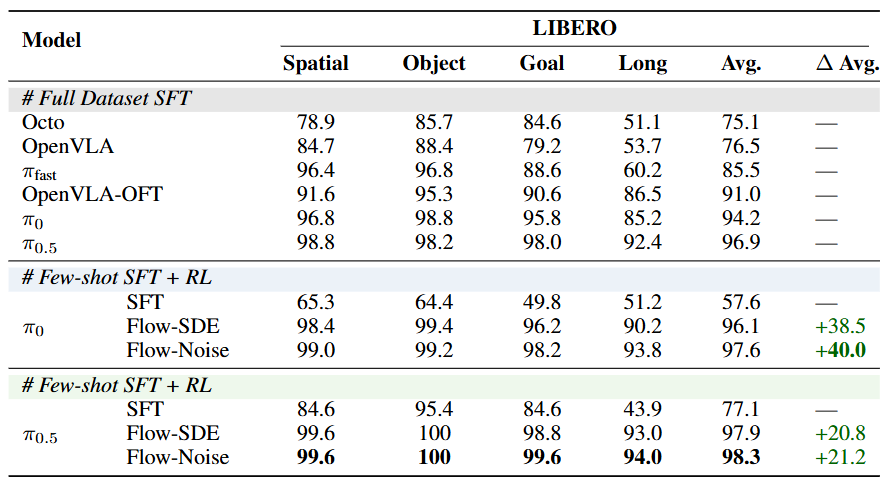
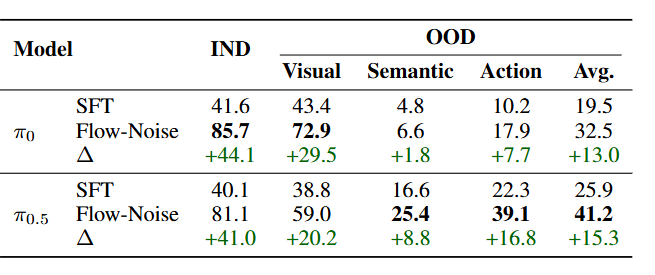
结果表明,πRL 不仅能让模型在小样本条件下自我强化,还能在复杂、多任务环境中保持高效泛化。
12 月 9 日 20:00,πRL的核心作者——北京大学的陈康博士,将亲述πRL框架的核心思想与实现细节。
我们相信,优秀的人终会相遇。
我们交流群见!12月9日直播来聊!

















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









