 πRL:流式具身模型的强化学习突破
πRL:流式具身模型的强化学习突破




导读
在具身智能的世界里,一个终极问题始终存在:
当机器人完成了模仿,它该如何继续“自己学”?传统的视觉语言行动模型(VLA)依赖人类演示数据训练,它们能精准地模仿,却难以超越教师。
而对于最新一代流式 VLA(如 π0、π0.5),情况更复杂——
这些模型通过连续流匹配生成动作,能控制机械臂完成精细任务,却无法轻易在真实环境中进行强化学习,因为它们的“行动概率”几乎无法计算。清华、北大、中科院与 CMU 团队的这项研究提出了突破口——他们让 π 系列模型第一次具备了在线强化学习(Online RL)能力。
这套名为 πRL 的框架,让机器人不再只是“模仿人类”,而能在环境中反复尝试、修正与进步。
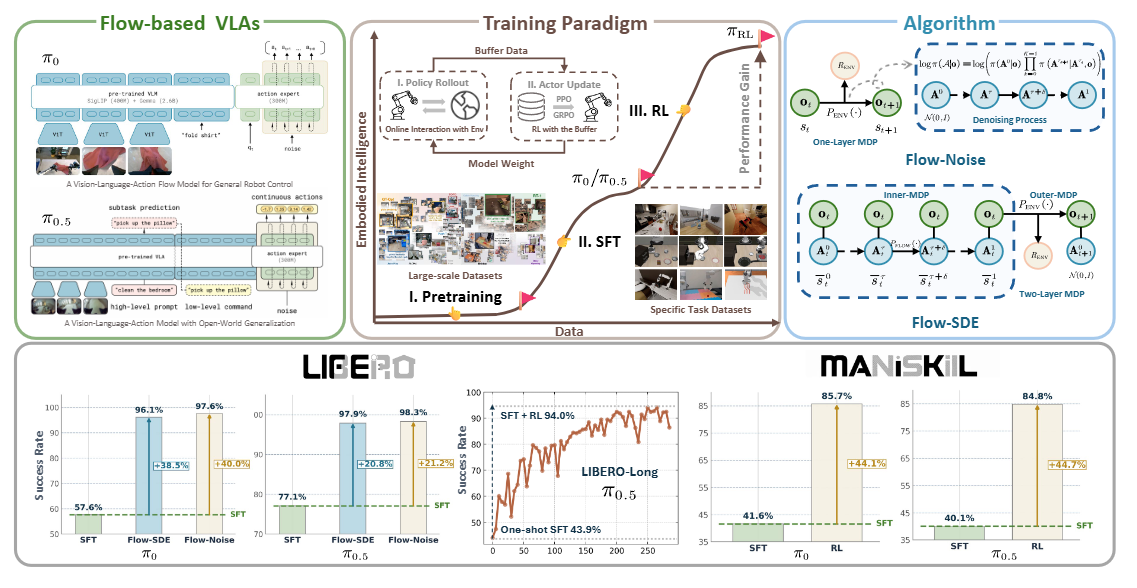
▲图1|πRL 是首个针对流匹配架构的在线强化学习框架,结合 Flow-Noise 与 Flow-SDE 两种策略,使 π0 与 π0.5 模型在少量示范下也能持续自我强化。在 LIBERO-Long 任务中,πRL 将 π0.5 的单示例成功率从 43.9% 提升至 94.0%;在 ManiSkill 上更支持 4,352 种多任务并行训练,验证了其大规模具身强化能力

研究团队首先发现,现有的强化学习算法几乎都基于自回归式(autoregressive)模型——它们能对离散动作建模,却无法处理流式生成的连续动作。
而 π 系列模型(π0、π0.5)通过“流匹配(Flow Matching)”方式生成一连串细粒度动作,这使得其“动作概率”难以直接估计,成为强化学习中的最大障碍。于是,团队提出了两种创新方案:Flow-Noise 与 Flow-SDE。
前者在流匹配的去噪过程中引入可学习噪声网络,把原本确定性的采样过程转化为离散时间的马尔可夫决策过程(MDP),从而获得精确的动作似然估计;
后者则通过ODE→SDE 转换,将去噪方程改写为随机微分方程,在保持分布一致的前提下引入探索性噪声,构建了内外双层 MDP,使模型能在“生成”和“交互”两个层面同时学习。
通过这两种机制,πRL 实现了让“流模型”真正能在环境中以 RL 方式自我优化的能力。
整个系统以 PPO 算法为核心优化引擎,在多环境并行仿真中不断滚动训练。
结果表明,这种“流式强化”不仅保留了动作的连续性,还显著提升了策略的泛化性能。
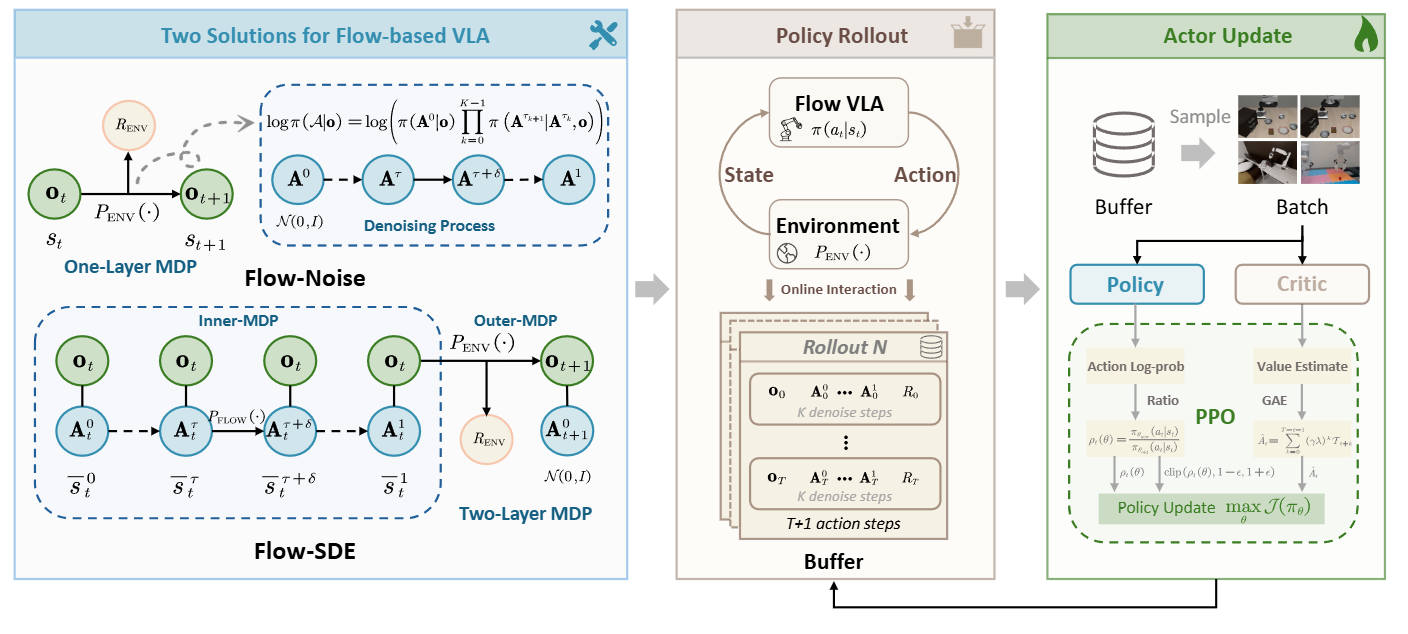
▲图2|两种流式强化优化思路:Flow-Noise 与 Flow-SDEFlow-Noise 在单层 MDP 中引入可学习噪声,通过完整的去噪序列计算动作似然;Flow-SDE 则将去噪过程转化为随机微分方程(SDE),在双层 MDP 中实现“边生成边交互”的强化学习。两种方法共同解决了流式模型在强化学习中难以求解似然的问题

首次实现“流式”强化学习
πRL 是第一个支持流匹配架构的在线强化学习框架。传统 RL 难以处理连续流式动作,因为每一步生成都依赖上一步的去噪过程。研究者通过引入 Flow-Noise 和 Flow-SDE 两条路径,成功让 π 系列模型具备可微分、可计算的动作似然,从而能够直接使用策略梯度(如 PPO)进行优化。这意味着未来的机器人模型,不再局限于自回归动作空间,也能在流模型架构中实现强化学习。
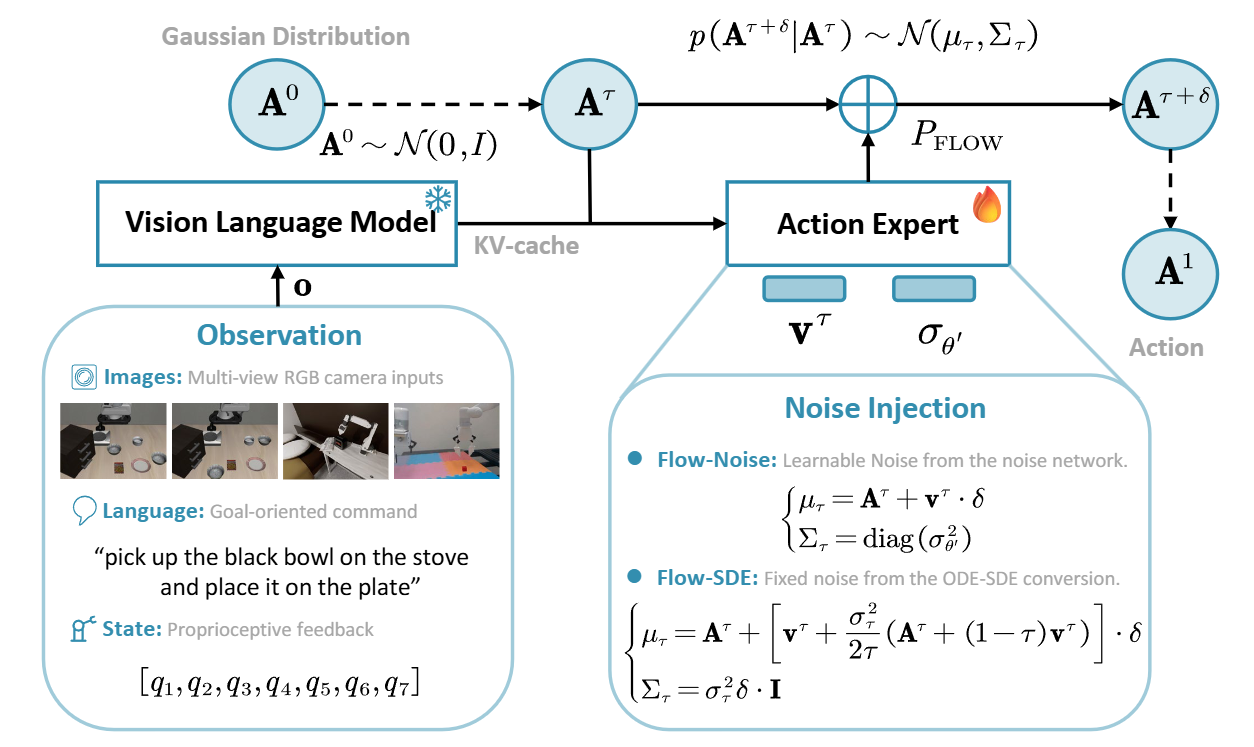
▲图3|流匹配中的噪声注入机制:以 π0.5 为例,模型将图像、语言和状态信息融合为统一输入,在去噪过程中动态注入噪声。Flow-Noise 采用可学习噪声网络,Flow-SDE 则使用固定噪声调度,两者共同提升了模型的探索性与稳定性
两层 MDP,让模型“边去噪边探索”
在 Flow-SDE 中,研究者提出了“双层 MDP”结构:内层 MDP 负责处理去噪的生成过程,外层 MDP 对接真实环境交互。每次决策都同时更新两个层级的状态与奖励,使机器人能在生成过程中动态调整探索强度。这种结构让流模型的“生成轨迹”与环境行为紧密结合,形成了一种具身级的“内外循环学习”。
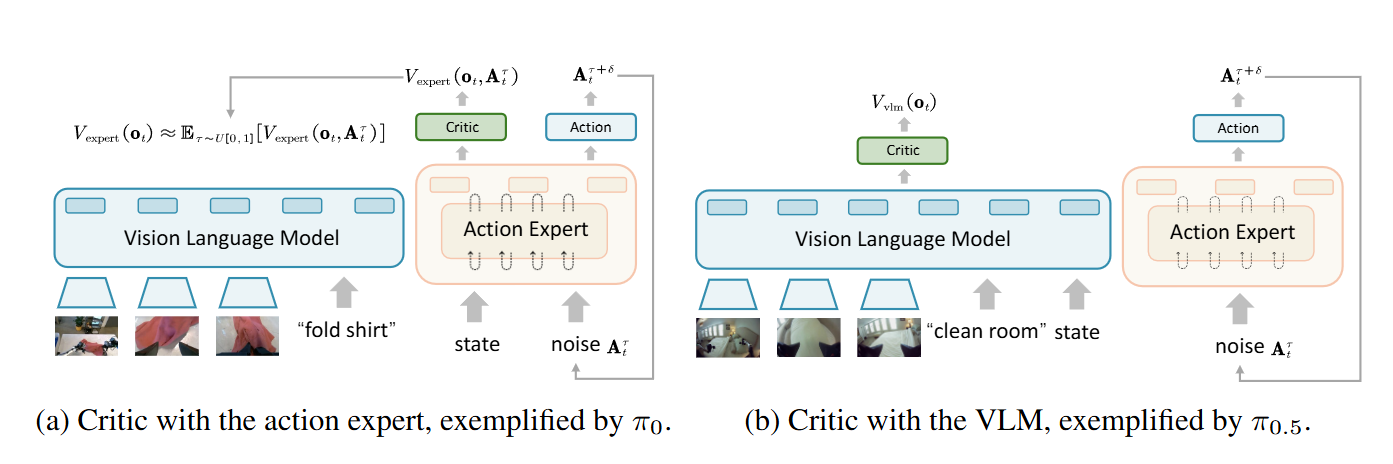
▲图4|研究者分别在动作专家层(Action Expert)和视觉语言模型层(VLM)后放置评论器,用于评估状态价值。结果显示,连接在 VLM 输出后的评论器在训练稳定性与数值拟合上略优,体现出感知层价值预测的潜力
并行仿真与开放源代码推动规模化具身训练
πRL 支持在 320 个并行环境中训练,涵盖 4352 种操作组合。在 LIBERO 与 ManiSkill 基准中,它让 π0 的平均成功率从 57.6% 提升到 97.6%,π0.5 从 77.1% 提升到 98.3%。所有代码与模型已开源(https://github.com/RLinf/RLinf),为具身智能社区提供了首个可复现的流式强化学习范例,标志着具身模型从“演示学习”向“自我改进”的重要一步。

▲图5|作者已在 HuggingFace 上开源全部模型与代码,并提供了详尽的中英文文档(甚至建立了微信群答疑),为开发者与研究者的复现提供了极大便利

在 LIBERO 基准上,πRL 展现出惊人的性能提升:
● 对 π0 模型,平均成功率从 57.6% 飙升至 97.6%;
● 对 π0.5 模型,从 77.1% 提升至 98.3%;
● 尤其在最具挑战的 LIBERO-Long 任务中,单轨迹 SFT 模型仅 43.9%,经过 πRL 训练后达到 94.0%,甚至超越全数据模型(92.4%)。
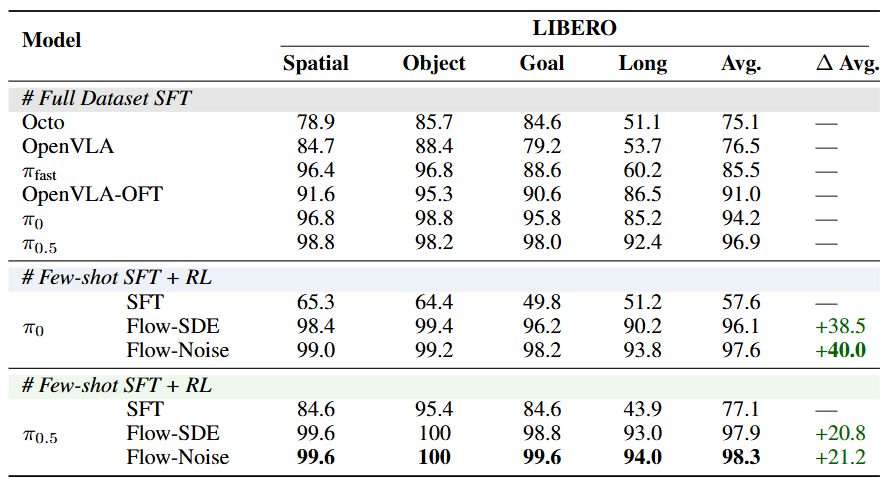
▲图6|LIBERO 基准结果:少量示范也能学会泛化:πRL 在四个任务套件中全面超越传统 SFT。π0 模型成功率从 57.6% 飙升至 97.6%,π0.5 从 77.1% 提升至 98.3%,其中单轨迹版本在长时任务 LIBERO-Long 上提升超过 50 个百分点
在高保真仿真环境 ManiSkill 中,πRL 同样取得突破:
● 在 4,352 种多任务场景下,π0 的成功率由 41.6% 提升到 85.7%,π0.5 从 40.0% 提升到 84.8%;
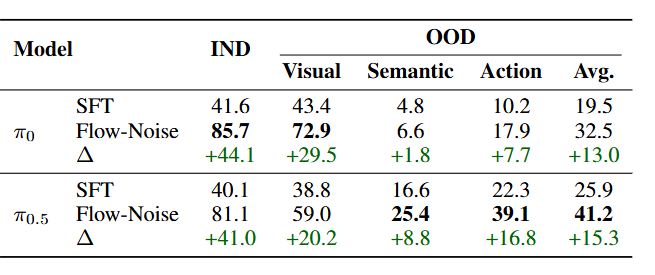
▲图7|ManiSkill 多任务结果:在 4,352 种多物体–多场景组合中,πRL 显著提升了模型的综合表现。π0 平均成功率由 41.6% 提高到 85.7%,π0.5 从 40.1% 提升至 84.8%,证明该框架能在复杂、多样的具身环境中稳定扩展
● 在 SIMPLER 子任务中,四类操作(carrot、spoon、cube、eggplant)平均提升近 20%。
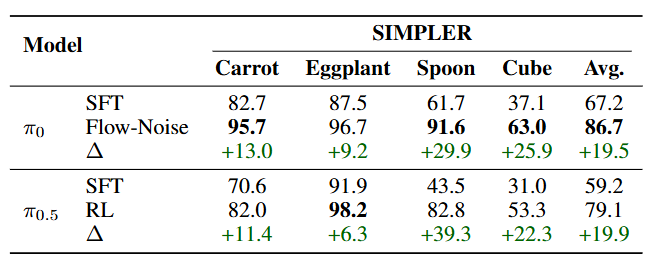
▲图8|SIMPLER 基准结果:在四项高精度操控任务(如放置勺子、胡萝卜、积木等)中,πRL 让 π0 的平均成功率从 67.2% 提升至 86.7%,π0.5 则从 59.2% 提升至 79.1%,展现出持续的自我强化效果
这些结果表明,πRL 不仅能让模型在小样本条件下自我强化,还能在复杂、多任务环境中保持高效泛化。更重要的是,它将 RL 能力真正带入了流式具身模型,为机器人提供了“边行动边进化”的基础。

πRL 的意义,不仅在于它提升了 π 系列模型的成绩,更在于它打通了“生成模型”与“强化学习”的边界。
在这项工作中,流匹配模型不再只是被动生成动作的工具,而变成能主动探索、反馈与改进的智能体。
这让具身智能的学习方式从“模仿”迈向“自我进化”。未来的机器人,不仅能理解指令、执行任务,还能像生命体一样——在真实环境中感知偏差、调整策略、持续成长。
当模型能在连续的行动流中找到学习信号,我们或许离“自我驱动”的通用具身智能,又近了一步。
标题:πRL: Online RL Fine-tuning for Flow-based Vision-Language-Action Models
作者:Kang Chen, Zhihao Liu, Tonghe Zhang, Si Xu, Hao Lin, Hongzhi Zang,Quanlu Zhang, Zhaofei Yu, Guoliang Fan, Tiejun Huang, Yu Wang, Chao Yu

















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









