




“90%的VLA模型,永远走不出实验室…”
——被严重低估的转型
由于ICLR 2026会议上,VLA模型相关投稿量,从去年的个位数飙升至超过150篇,足足增长了近18倍之多。所以,不少媒体奔走相告:“你看,VLA有多火!”
不过,如果你常年追踪VLA(视觉-语言-动作)领域的前沿论文,想必对以下场景无比熟悉:
一个模型在复杂任务中展现出惊人的理解力,但论文的‘局限性’部分,总会不可避免地出现‘效率有待提升’与‘真实世界泛化能力需进一步验证’——
这类标准措辞。
久而久之,产业界开始流传各种不看好VLA的表达:“当前绝大多数VLA模型,从设计之初就未曾被赋予‘走出实验室’的使命…”、“VLA正在沦为纸上谈兵的‘学术游戏’”等种种戏谑说法。
面对质疑,行业正衍生出不同的突围路径——
追求架构颠覆的世界模型、探索性能极限的VLA+强化学习,以及我们今天聚焦的、或最务实也最紧迫的路径:高效VLA。
所以,今天我们不谈“风花雪月”的性能突破,而来尝试“捅捅”全球性VLA‘效率’这层窗户纸。
我们无意直接否定VLA的终极潜力。正相反,正因为它可能代表未来,我们才必须用最苛刻的目光审视它的当下,并围绕其展开讨论。
众所周知,当前VLA模型普遍存在参数庞大、计算成本高昂、部署困难的问题。
当功耗要求让嵌入式设备成为奢望——任何性能指标满分都失去了意义。
因而,效率优化(Efficiency)也就成为了VLA研究的趋势之一。
据综述《A Survey on Efficient Vision-Language-Action Models》所示,2023-2025 年间,在基础 VLA 模型持续迭代的同时,高效 VLA 从 2024 年底开始呈现爆发式增长,成为衔接模型能力与实际部署的关键赛道。
本文也将依托这篇综述的框架、结合180+研究成果,尝试揭示当前VLA的结构性困境以及或需完成的范式转移。
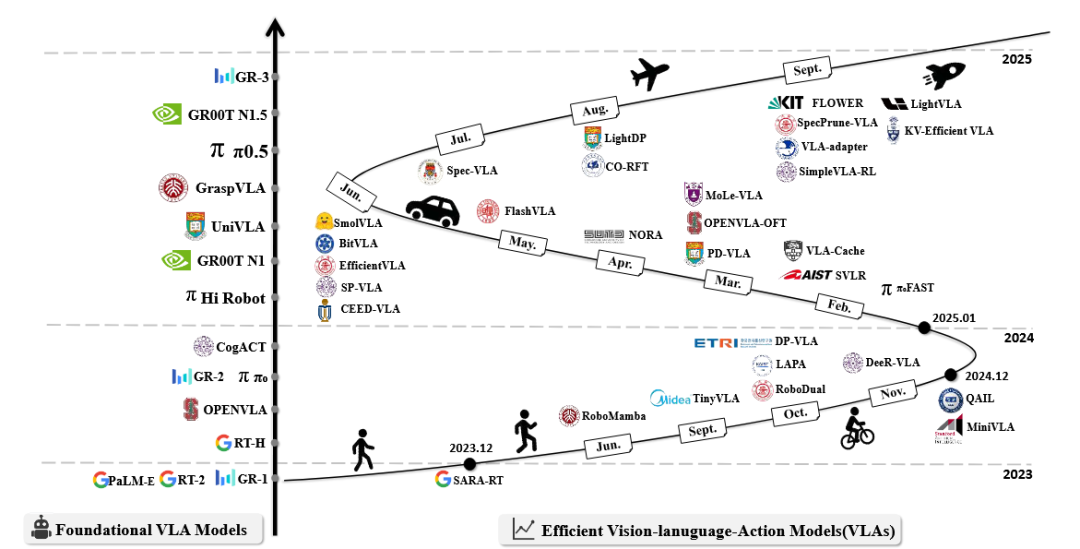
▲基础VLA模型和高效VLA的时间线。

效率瓶颈的量化分析
首先要想解决模型效率问题,我们必须先了解当前VLA模型的两大效率挑战:
-
挑战一:计算足迹(Computational Footprint)
VLA基础模型参数量从2.2B到55B不等,以OpenVLA (7B)为例,其推理延迟为166ms,控制频率仅6Hz,表现出高延迟。
对于需要50Hz以上控制频率的精细操作任务,这种延迟是不可接受的。
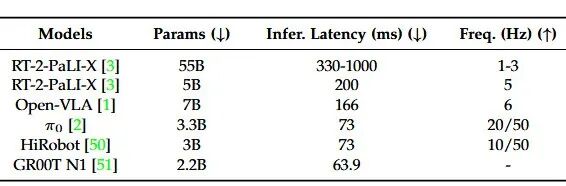
▲代表性VLA模型的效率相关指标。该表比较了各种代表性VLA的参数数量、推理延迟和运行频率,其中↓表示数值越低越好,↑表示数值越高越好。
-
挑战二:数据依赖(Data Dependency)
VLA预训练需要大规模、多样化的演示数据。
真实世界机器人演示数据的1:1时间比(演示时间等于数据时长),加上环境配置、任务重置和人为错误,使得数据收集效率远低于预期。
一定要追究“效率”么?
答案或许是:是的。
简单的佐证就是:高推理延迟会妨碍实时响应,巨大能耗会限制边缘部署,高昂成本则会阻碍大规模应用。
因此,通常认为追求效率不是可选的优化,而是VLA走向实际应用的根本前提。
接下来,我们将核心探讨2023-2025 年间高效 VLA 加速涌现,其在高效模型设计、高效训练、高效数据集收集这三大核心支柱层面的进展与细分路径。
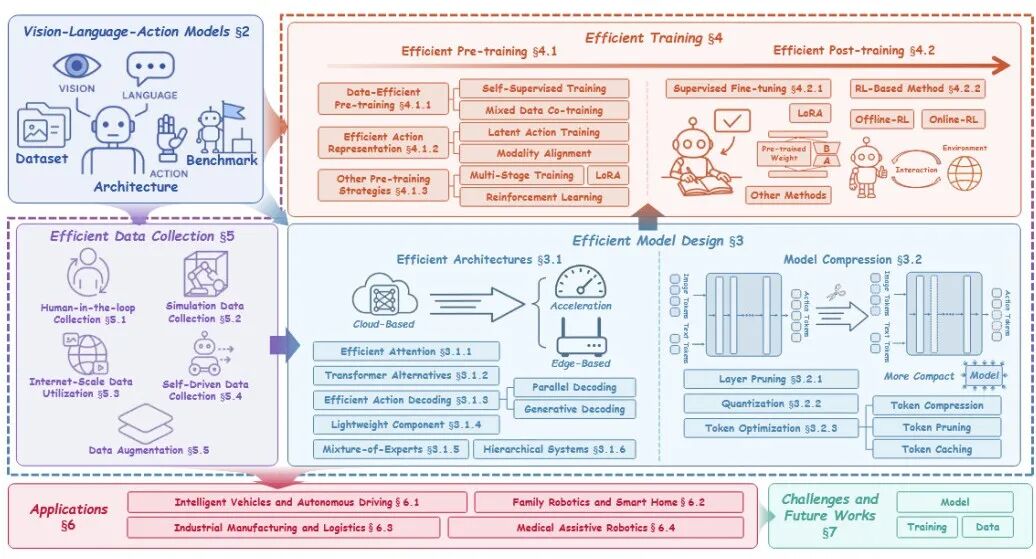
▲高效VLA的三个核心支柱:(1) 高效模型设计,包括高效架构和模型压缩技术;(2) 高效训练,涵盖高效预训练和后训练策略;(3) 高效数据收集,包括高效数据收集和增强方法。

首先,我们需要理解「高效模型设计」:
高效模型设计既通过架构创新和压缩技术,在保持多模态协同和动作精度的同时,大幅降低参数量和计算成本。
首先:高效架构(Efficient Architectures)
VLA中高效架构的关键策略,可以有六种主要方法,分别是:
高效注意力、Transformer替代方案、高效动作解码、轻量级组件、专家混合、分层系统。
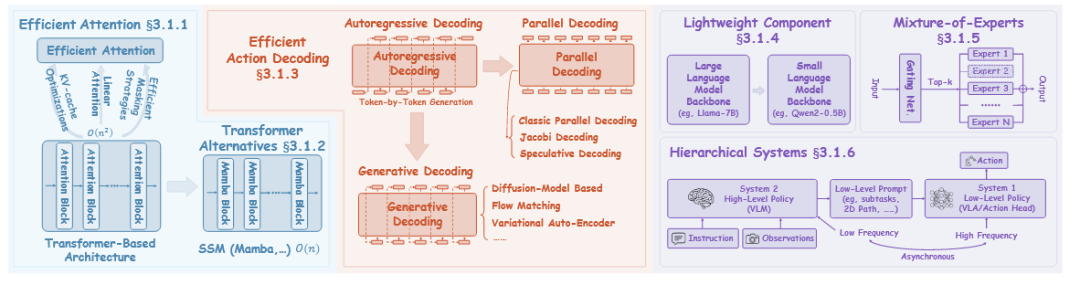
▲VLA中高效架构的关键策略的六种主要方法
-
高效注意力机制
由于Transformer的核心注意力机制存在O(n²)的复杂度瓶颈,因此针对此问题,目前研究者们普遍提出了三类优化方向:
1.线性时间架构:通过上训练(up-training)将Transformer转换为线性注意力模型,将复杂度从O(n²)降至O(n),在保持表征能力的同时,实现实时控制。
典型研究如:由 Google DeepMind 机器人研究团队提出的SARA-RT(ICRA 2024 最佳论文奖)。
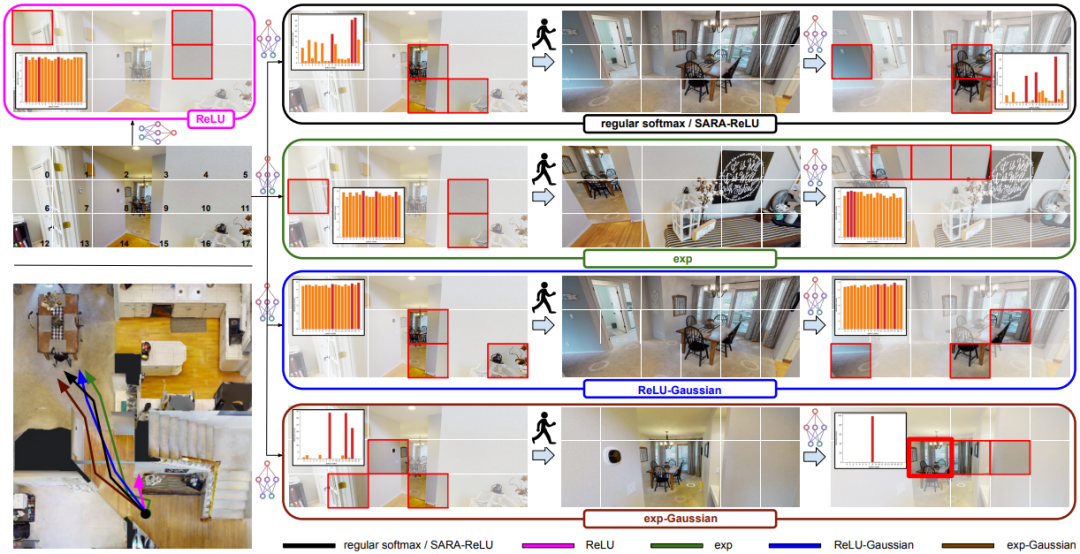
▲SARA-RT
2.高效掩码策略:用阶段感知输入掩码,在运动阶段关注静态相机token,在交互阶段关注夹爪token,构建了长时操作的高效机制。
典型研究如:由西湖大学、浙江大学等联合开发的 Long-VLA 模型。
3.KV缓存优化:通过轻量循环门控将历史KV缓存压缩为信息丰富的分块表示,自适应保留显著上下文以优化自回归流程。
如:多伦多大学、清华大学联合研究的KV-Efficient VLA。
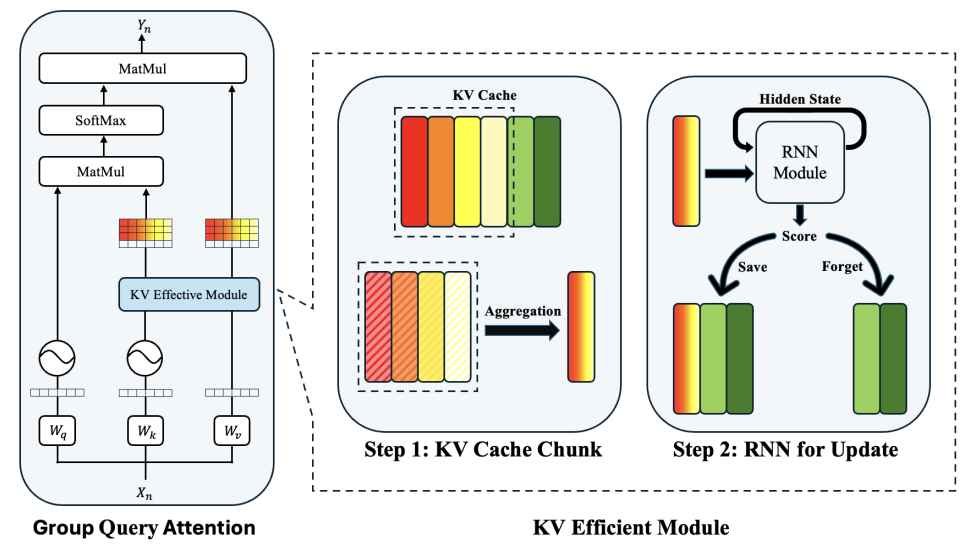
▲KV-Efficient VLA
-
Transformer替代方案
针对Transformer的典型瓶颈,除了优化注意力机制,近年来部分工作也探索了全新的架构范式。
例如北京大学联合多家机构发布的 RoboMamba,它首次在VLA中采用Mamba作为语言骨干网,利用状态空间模型(SSM)的线性计算复杂度,彻底避免了Transformer的二次瓶颈。
FlowRAM 则在此基础上将Mamba与条件流匹配和动态半径调度结合,进一步提升高精度操作任务的效率和精度。

▲RoboMamba
-
高效动作解码
另外,传统VLA采用自回归方式逐token生成动作,因而存在累积推理延迟。高效动作解码又分为并行解码和生成式解码两类范式。
下图为高效动作解码的相关代表性工作:
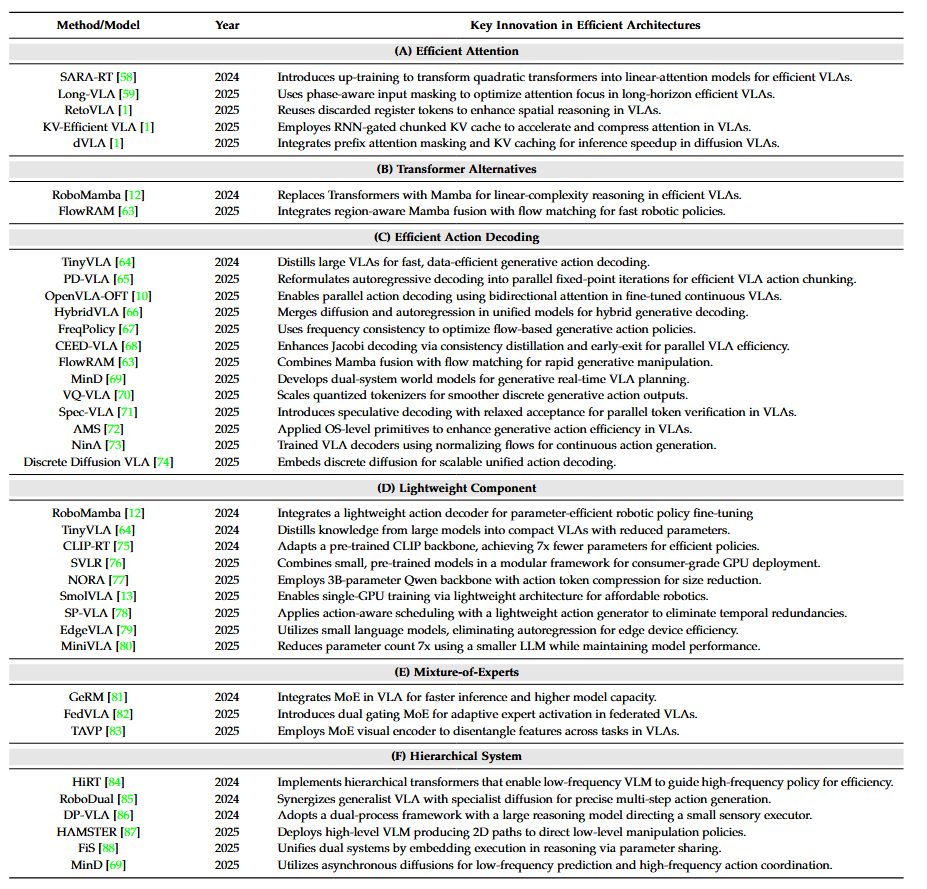
▲高效架构的代表性工作。
-
轻量化组件
轻量化组件则提供了最直接的效率提升路径。
RoboMamba 就充分体现了这一理念,使用仅3.7M参数的MLP策略头(占总参数0.1%)精准预测6自由度末端执行器位姿。
再如 TinyVLA 开创性地将预训练轻量VLM(<1.4B参数)与基于扩散的策略解码器配对,实现前所未有的推理速度和数据节俭性。
-
混合专家(Mixture-of-Experts)
这个想必大家也很熟悉。MoE架构,既通过将token路由到专门子网络,仅激活部分参数,在不增加推理成本的情况下扩大模型容量。
如西湖大学 MiLAB 实验室提出的 GeRM,首次将稀疏MoE集成到四足强化学习中,证明选择性参数激活可在保持推理节俭性的同时扩展多任务泛化的模型表达能力。后来FedVLA 、TAVP则进一步完善发展。
▲GeRM
-
分层系统
分层系统也是近年来广受热议的一类架构,受心理学双过程理论启发,研究者们将认知分为深思熟虑的语义丰富推理和直觉快速执行,模拟类人具身代理。
这些范式主要将计算密集型视觉-语言模型(VLM)推理(system 2)与延迟敏感动作生成(system 1)解耦,以协调深刻语义理解与即时控制需求。
典型如:上海交通大学联合香港大学、智元机器人提出的 RoboDual 架构。
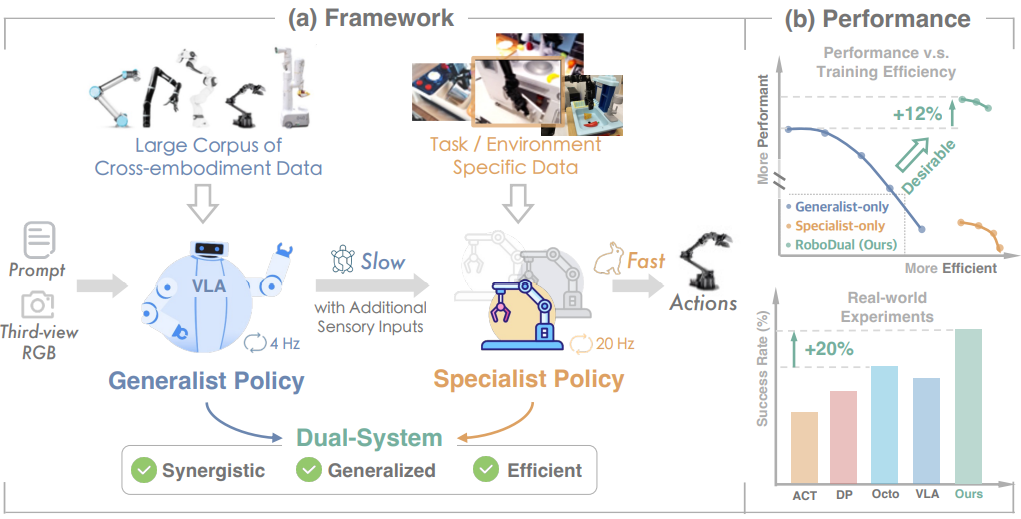
▲RoboDual
模型压缩(Model Compression)
模型压缩通过系统化技术蒸馏参数集合,在保持多模态协同的同时增强推理效率。
这一方向包括层剪枝、量化和token优化三大主要方法。
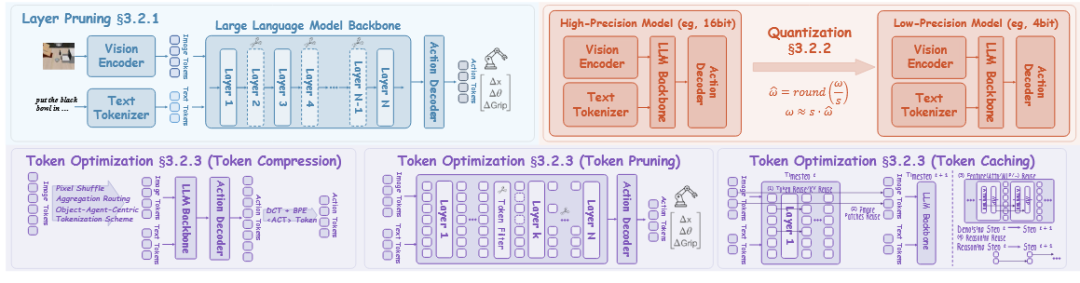
▲VLA中模型压缩的关键策略。三种主要方法:(a) 层剪枝;(b) 量化;(c) token优化。
-
层剪枝
层剪枝利用大语言模型中层间的高度冗余(相邻层呈现高层间余弦相似度),通过动态早退或选择性层跳过精确切除冗余层,显著降低参数量和推理延迟。
其中有分为:免训练方法(如DeeR-VLA)和基于训练方法(如MoLe-VLA)。
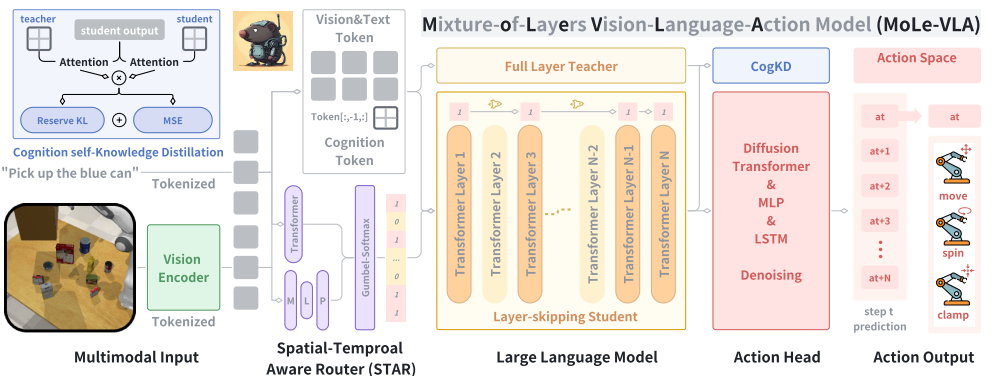
▲南京大学、香港理工大学、北京大学等团队提出的MoLe-VLA
-
量化
量化将连续权重和激活离散化为低位表示,削减内存占用并加速VLA推理。
-
Token优化
Token优化通过压缩、剪枝和缓存策略精炼VLA中的表示token序列,减轻Transformer计算的二次增长。
下图为模型压缩的相关代表性工作:
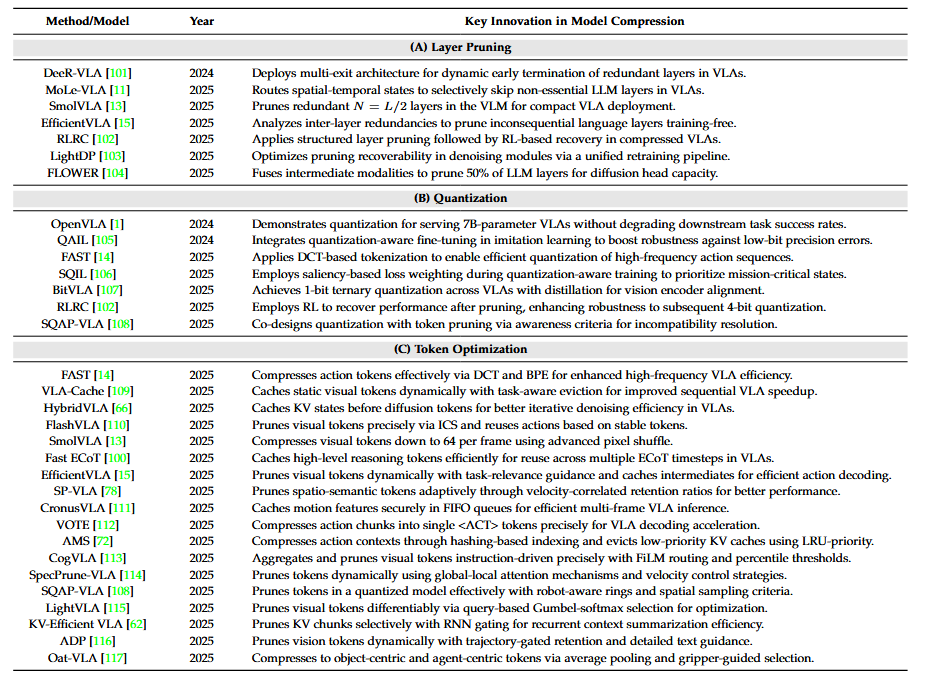
▲模型压缩的代表性工作。

VLA模型从大规模预训练VLM骨干网继承强大视觉理解和常识推理能力,但这种继承本身带来巨大负担,使训练计算密集、耗时且高度依赖海量高质量数据集。
高效训练方法的两大阶段:高效预训练、高效后训练。
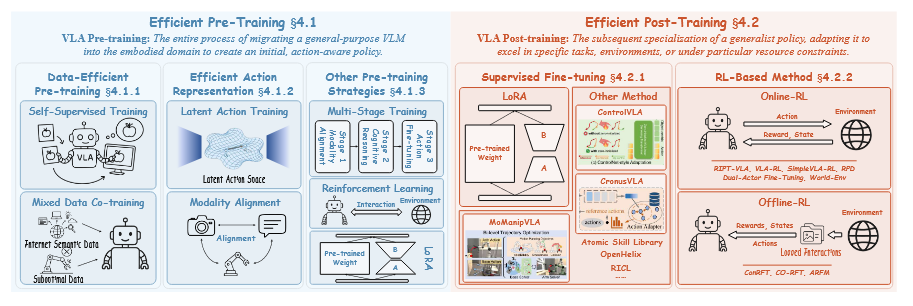
▲VLA高效训练的关键策略,分为两个主要阶段。(a) 高效预训练将通用VLM迁移到具身领域以创建初始的、动作感知的策略,包括数据高效预训练、高效动作表示和其他预训练策略。(b) 高效后训练随后将该策略专门化用于特定任务,利用监督微调和基于RL的方法。
高效预训练(Efficient Pre-Training)
高效预训练:将VLA模型性能提升与大规模基础骨干网和海量多模态数据集的高昂计算足迹解耦。
本文从VLA中心视角定义:预训练是将通用VLM迁移到具身领域以创建初始、动作感知策略的整个过程。
-
自监督训练:
第一类方法专注于最大化现有机器人数据的效用。
▲由北京航空航天大学等团队提出的Diffusion Trajectory-guided Policyfor Long-horizon Robot Manipulation(DTP)
第二类集中于利用海量、无标注互联网规模的自我中心视频。
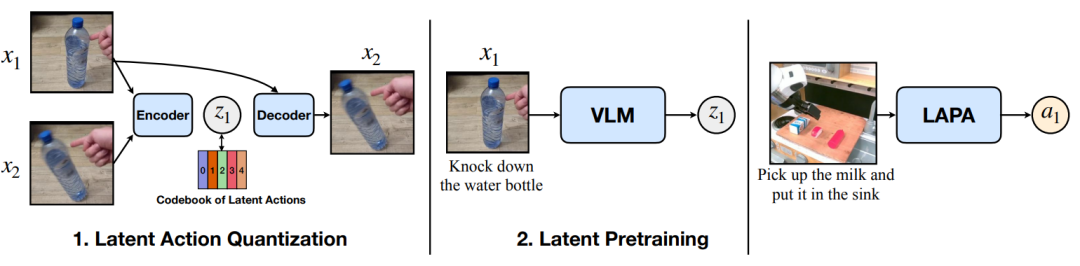
▲由韩国科学技术院、华盛顿大学等团队提出的LATENT ACTION PRETRAINING FROM VIDEOS(LAPA)
下图为高效预训练的代表性工作:
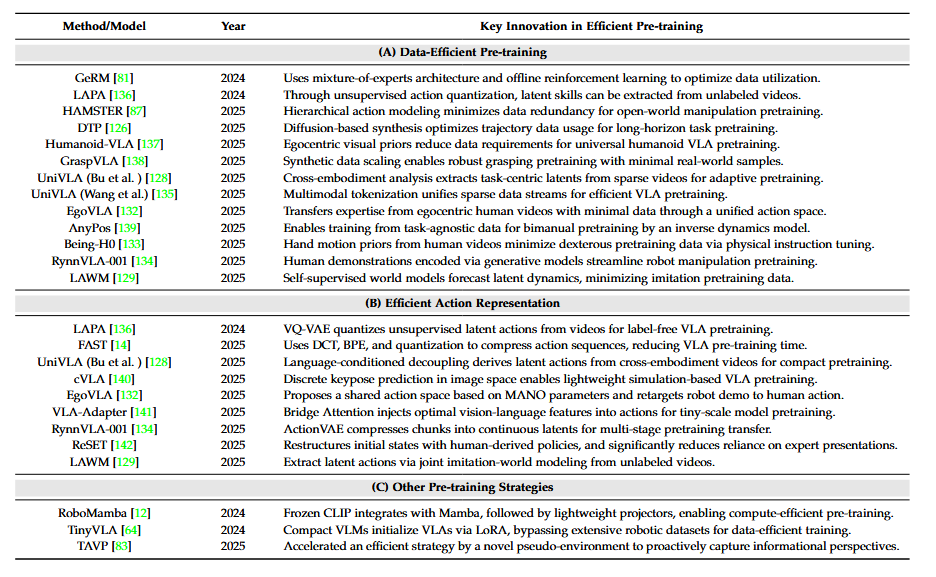
▲高效预训练的代表性工作。
-
高效动作表示
动作作为独特的具身模态,通常高维、连续且嘈杂,显著阻碍VLA训练效率和泛化。
动作空间压缩:RynnVLA-001在标准VAE架构上提出ActionVAE。
推荐延展阅读RynnVLA-001:阿里达摩院用 1200 万第一视角视频打底,新成果 RynnVLA-001 大幅碾压主流模型!

▲RynnVLA-001
创新动作建模:EgoVLA通过基于MANO参数的共享动作空间桥接人类演示到机器人动作表示。

▲由UC San Diego、UIUC等团队提出的EgoVLA
高效后训练(Efficient Post-Training)
在基础预训练阶段之后,高效后训练技术将VLA细化以与下游任务对齐,同时最小化计算需求。
这些方法包括监督微调和基于强化学习的方法。
-
监督微调
在参数高效微调方面,OpenVLA开创性系统探索五种策略——全微调、仅最后层、冻结视觉、三明治微调和LoRA。
-
基于强化学习的方法
尽管监督微调擅长利用高质量任务特定数据,但其效能依赖数据丰度和质量。
分为在线RL(如RIPT-VLA)、离线RL(如ConRFT)两类。
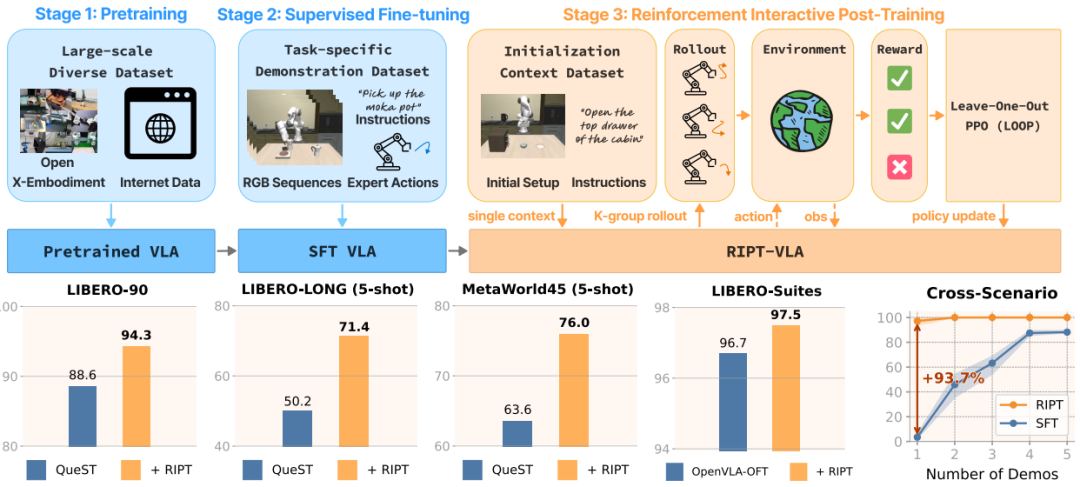
▲由UT Austin等团队提出的RIPT-VLA
下图为高效后训练的代表性工作:
▲高效后训练的代表性工作

接着,我们自然无可避免的要聊到「数据」问题。
尤其是VLA性能极其依赖演示数据集,在具身形态和任务变化上的规模、质量和多样性。
与规模训练数据的LLM和VLM不同,VLA无法直接利用此类资源。

▲VLA中高效数据收集策略的分类法
人在回路数据收集
传统数据收集可能需要人类全程手动操控机器人完成任务(1:1 时间投入),而人在回路模式下,人类仅在关键节点介入,大幅提升效率
如CLIP-RT则通过自然语言界面收集机器人演示,用户与LLM对话交互,LLM将语言命令转化为低级末端执行器动作。

▲由首尔国立大学等团队提出的CLIP-RT
仿真数据收集
仿真环境允许通过自动化、并行过程在广泛设置、对象类型等条件上扩展数据生成,从而以极少时间和费用策划具有更大多样性的大规模数据集。
如GraspVLA引入了SynGrasp-1B,通过光照真实仿真并行生成的十亿帧合成抓取数据集。
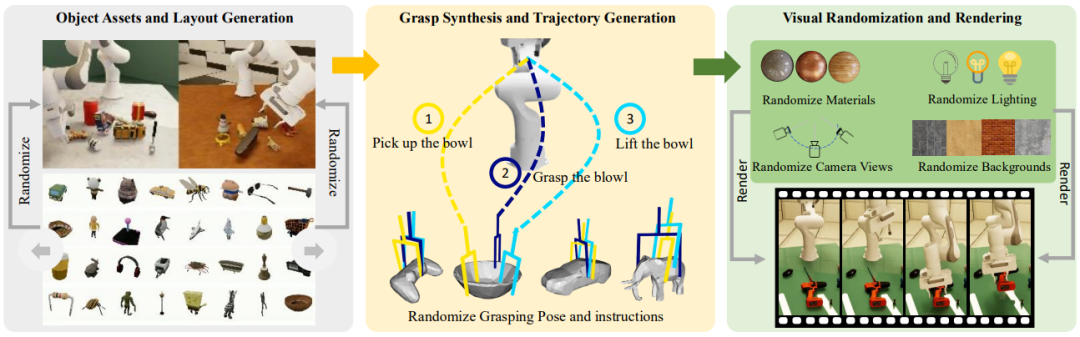
▲银河通用、北京大学、香港大学等团队提出的GraspVLA
然而,过度简化的仿真环境可能无法捕获真实世界复杂性。
通常则通过视觉和物理参数的域随机化、光线追踪的光照真实渲染、涵盖照明条件、相机视点、背景纹理和对象外观的系统增强,以及结合大规模仿真数据与最少真实演示的混合训练来解决。
典型研究如 R2R2R 从真实世界输入合成大规模、光照真实机器人演示:对象的智能手机扫描和单个人类操作视频。关于R2R2R的延展阅读推荐:不碰真机也不仿真?(伪代码)伯克利最新:仅用一部手机,生成大规模高质量机器人训练数据!
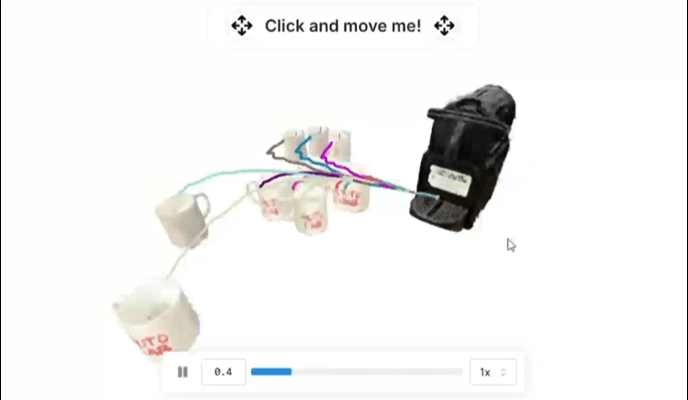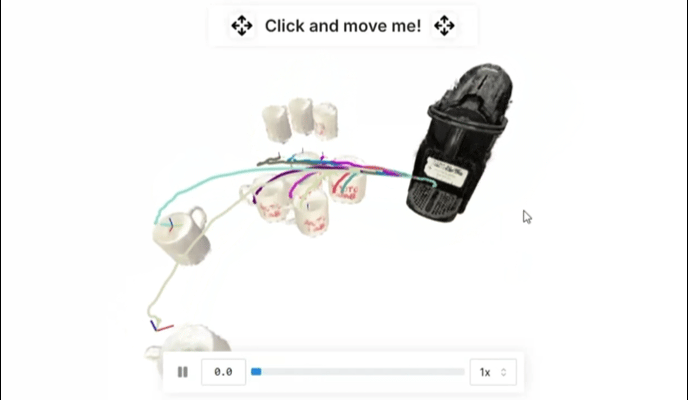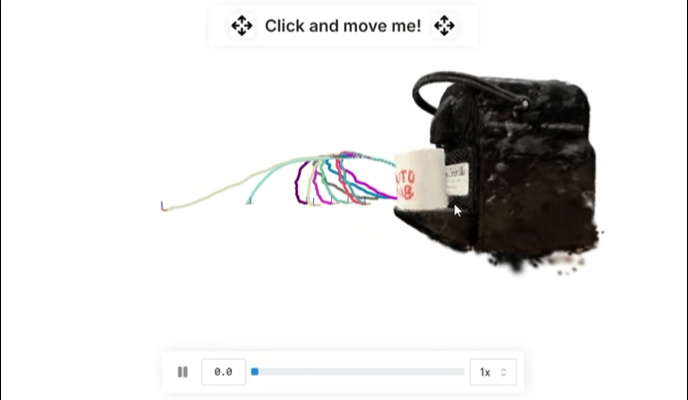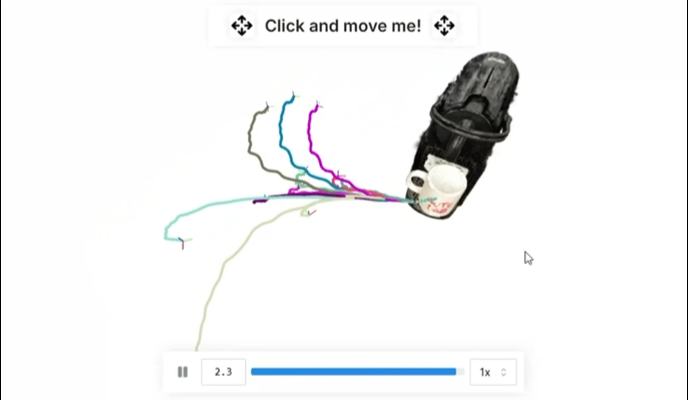
▲R2R2R
下图为高效数据集收集的代表性工作:
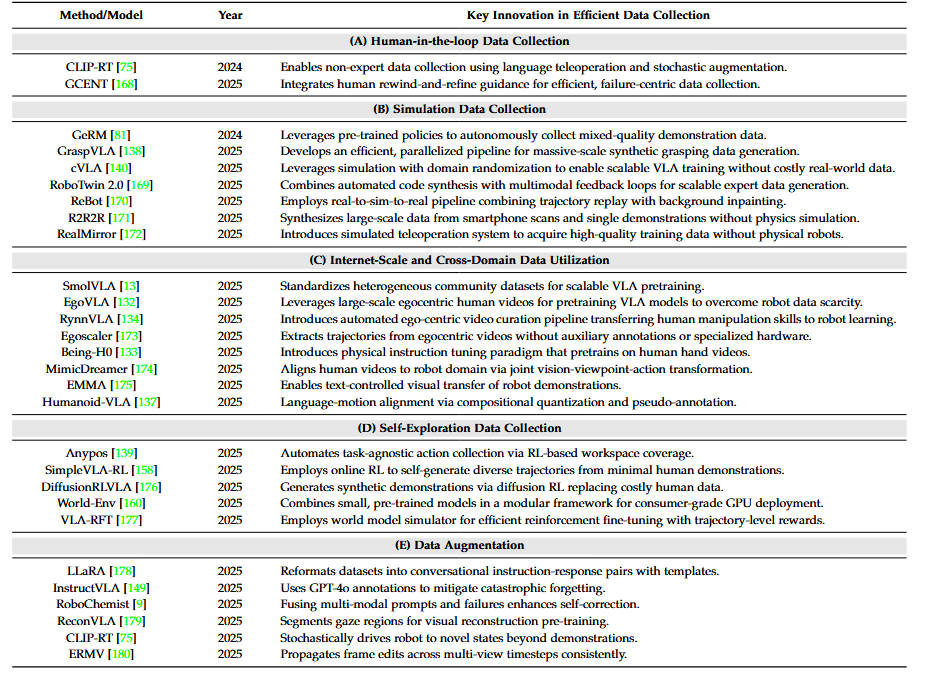
▲高效数据收集的代表性工作。
互联网规模和跨域数据利用
尽管仿真数据收集,有效解决人工远程操作演示的可扩展性限制,但该方法需要从头构建数据集并受Sim-to-Real鸿沟约束。
于是焦点转向:利用互联网规模和其他现有数据源。
-
社区数据集策展:
通过从Hugging Face等平台汇聚众多小规模数据集示例这种社区驱动方法。

▲由Hugging Face、索邦大学等联合提出的SmolVLA
-
自我中心视频利用:
EgoVLA 开创了这一自我中心范式,引入将人类视为一种机器人形式的基础概念,确立自我中心人类视频作为VLA可行训练模态。
自我探索数据收集
在线强化学习作为主要途径使代理能够通过直接环境交互"边学边收集"。
例如SimpleVLA-RL开创了通过仅最少人类演示作为"种子"的在线RL展示自驱动数据收集。
数据增强
数据增强通过最大化现有数据的效用和多样性,将收集轨迹转换为更丰富、更多样的训练信号。
-
语言和语义标注增强:如LLaRA、ReconVLA;
-
轨迹和状态增强:如CLIP-RT;
-
视觉模态增强:如ERMV。
▲香港科技大学(广州)等团队提出的ReconVLA

《A Survey on Efficient Vision-Language-Action Models》这篇综述系统梳理了高效视觉-语言-动作模型(Efficient VLA)——首个覆盖"数据-模型-训练"全流程的统一分类体系。
但,伟大的技术从来不是诞生于真空/按图索骥的线性规划中,而是存活于现实挤压下的顽强适配。
结语:
行文至此,分享一个此前年轻的朋友们与我交流时,偶有提及的一个问题:
“在VLA、端到端、世界模型等多条技术路线并存的今天,我们究竟该如何选择,才不至于重蹈当年自动驾驶领域“模块化工程师”被技术浪潮冲刷的覆辙?”
我个人认为在技术尚未收敛的当下,冰山之下更加重要。无论上层技术如何演变,强化学习、仿生机械设计、仿真平台、数据工程等底层能力永远是稀缺的有用的。
因此,或许构建这些“硬核”能力,能让你在技术路线切换时保持从容。
且短期内,这场“路线”技术竞赛大概率并非一场“你死我活”的淘汰赛,而更像是一场在不同赛道上、针对不同目标(产业场景)的马拉松。
祝好。
受限于文章篇幅,更多细分技术细节与前沿成果,请您阅读各研究原文,鸣谢。
Ref
论文标题:A Survey on Efficient Vision-Language-Action Models
论文作者:Zhaoshu Yu, Bo Wang, Pengpeng Zeng, Haonan Zhang, Ji Zhang, Lianli Gao, Jingkuan Song, Nicu Sebe, and Heng Tao Shen
论文地址:https://arxiv.org/pdf/2510.24795
项目主页:https://evla-survey.github.io/


















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









