 吴恩达AI落地的五大方向
吴恩达AI落地的五大方向




导读
在全球人工智能的版图上,吴恩达始终是一位极具“方向感”的科学家。他既是深度学习早期浪潮的关键推动者,也是推动 AI 走向产业、教育与公共科学的标志性人物。从斯坦福机器学习课程,到 Google Brain 的奠基,再到百度大脑的工程化实践与 Coursera 的在线教育革命,再到 Landing.ai 引领的工业 AI 现代化,吴恩达的职业轨迹几乎对应了过去二十年 AI 的几次关键跃迁。
进入 2025 年,这位“AI 教父”依然在跨越学术、产业与教育三个维度保持着独特影响力:一方面推动基础模型的普及化与工程落地,另一方面通过基金、平台与课程体系培养下一代具身智能与大模型时代的实践者。他的研究不再局限于某项技术突破,而是在回答一个更根本的问题——如何让 AI 更快走进真实世界,更公平地被大众使用,并真正成为社会的生产力与创新源泉?
回顾过去二十年的技术演进,吴恩达几乎参与了深度学习每一次关键基础设施升级:从早期的大规模分布式训练,到 Google Brain、百度大脑,再到在线教育推动的知识普及,让“深度学习时代”真正发生。然而在最近几年,他的关注点正在发生显著变化——从学术驱动,转向解决真实世界的工程难题。
如今的他,更像是一位站在行业一线的 “AI 工程化布道者”。他不再只讨论某种模型结构有多先进,而是思考:
● 大模型如何才能让企业真正用得起?
● 如何通过工程体系降低成本、提升可控性?
● 合成数据、代理系统、自动化标注等手段,是否能够缩短 AI 落地路径?
● 如何让 AI 在医疗、环境监测、能源基础设施等任务里真正解决问题?
也正因此,他团队近期的研究呈现出强烈的应用导向:医疗智能体评测、超大规模现实世界 benchmark、卫星影像自动识别、合成数据增强、环境监测、任务级 AI 代理……这些看似 task-specific 的工作,其实共同指向一个更大的命题——让大模型从“能做 demo”走向“能做生产”。
值得注意的是,吴恩达近年来还有大量成果以专利(US Patent)形式发布而非论文,这本身就是他向 AI 工程化、产业化 转向的直接信号。由于专利内容往往涉及具体商业实现,本次盘点主要聚焦论文成果;如读者有兴趣,可以进一步查阅相关专利。
下面,我们将系统盘点吴恩达团队过去一年最重要的研究工作,看看这位深度学习时代的重要推动者,如何在 2024–2025 年继续重塑 AI 的落地方式。
参考:
https://scholar.google.com/citations?hl=en&user=mG4imMEAAAAJ&view_op=list_works&sortby=pubdate
MANY-SHOT IN-CONTEXT LEARNING IN MULTIMODAL FOUNDATION MODELS
地址:https://arxiv.org/pdf/2405.09798?
主要内容:
这篇工作聚焦一个正在快速升温的新趋势:大模型能不能在推理阶段,通过“看更多例子”而变得更聪明?
过去我们说的 few-shot 学习通常只给模型几十个示例,而如今多模态基础模型(例如 GPT-4o、Gemini 1.5 Pro)已经拥有超长上下文能力,让“many-shot”成为可能——一次输入几百乃至几千个示例。研究团队于是做了一件非常系统的事情:
让这些模型在 14 个跨领域数据集上测试,从 few-shot 扩展到接近 2000 个示例,观察性能变化。
他们的发现很直观,也很有启发性:
● 示例越多,模型确实越强——多模态领域同样成立,不仅语言大模型才能做到这种“推理时学习”。
● Gemini 的提升尤其明显,随着示例数量增加,性能几乎呈线性增长。
● 但开源模型提升有限,说明开放权重的多模态模型在“即时学习”上仍落后不少。
● 一个很实用的额外发现是:把多个任务一起 batch 给模型,反而能提升效果并降低成本,对 API 场景特别友好。
整体来看,这项研究给出了一个清晰信号:
Many-shot ICL 很可能成为未来适配新任务的新方式,不用训练,只需“给例子”,模型就能快速进入状态。
风格轻量、想法直接,但对大模型实际落地很有参考价值。
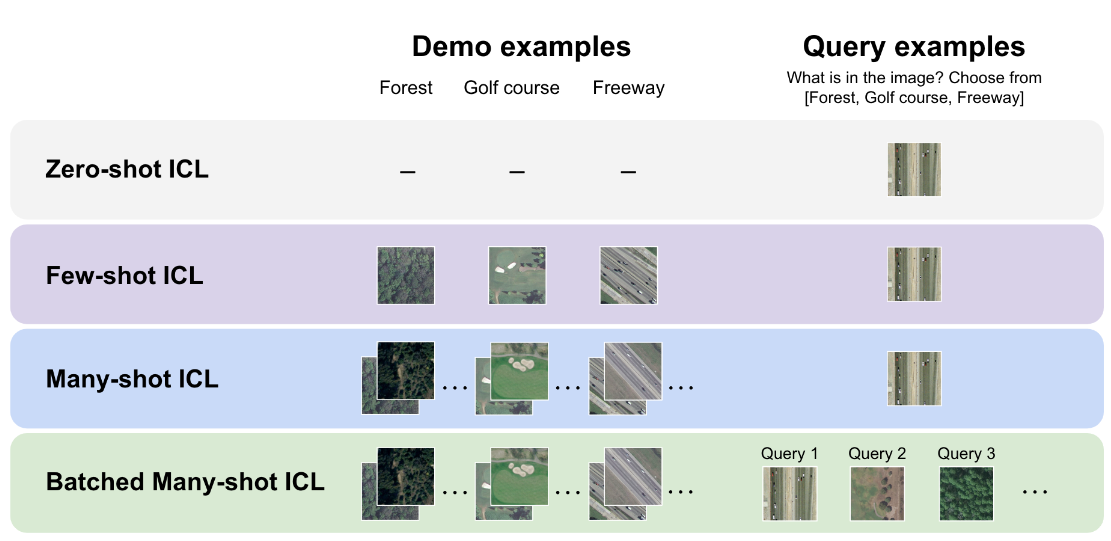
图1|这张图展示了模型在不同“示例量”下的工作方式:Zero-shot:模型完全没有看到示例,直接回答。Few-shot:上下文里只有极少量示范。Many-shot:一次输入大量示例,让模型在推理前“快速补一节课”。Batched many-shot:把多个查询一起塞进同一大 prompt,让模型同时参考大量示例并批量回答。随着示例数量的增加,模型的表现不断提升,也让 many-shot ICL 成为一种轻量但强大的任务适配方式
UQ:Assessing Language Models on Unsolved Questions
地址:https://arxiv.org/pdf/2508.17580
主要内容:
在大模型评测被刷榜、套路化的今天,吴恩达团队选择了一条完全不同的路:让模型去回答那些连人类也没有标准答案的问题。这听起来像是“刁难模型”,但实际上正击中了当前评测体系的一大痛点——大多数 benchmark 要么脱离真实场景(太像考试),要么过度依赖用户行为(问题太浅),都无法真正衡量大模型的“开放世界能力”。
UQ(Unsolved Questions)提出的核心思想非常直接:
既然真实世界里充满尚未解决的复杂问题,那评测也应该围绕这些问题来进行。
研究团队从 StackExchange 等社区精挑细选了 500 个“人类也难以给出统一答案”的高难度问题,覆盖计算机科学、数学、科幻、历史、逻辑推理等多个领域。更关键的是,UQ 并不是一次性的静态测试,而是:
● 模型可以随时提交答案
● 由验证器和社区共同评审
● 评测结果持续更新、长期有效
这种模式让 benchmark 本身变成了一个“活的系统”,更能反映真实应用中模型需要面对的情况:不确定、无标准答案、上下文不断变化。
实验结果也很有意思:
目前最强模型只有 15% 的答案能够通过 UQ 的严格验证。这不仅说明任务本身难度高,也揭示了大模型在应对开放式、非结构化问题时的巨大提升空间。
从方法到平台,UQ 提供了一种全新的思路:评测模型不再靠背答案,而是靠推理深度与解决问题的能力。这是大模型从“会答题”迈向“能解决问题”的关键一步。
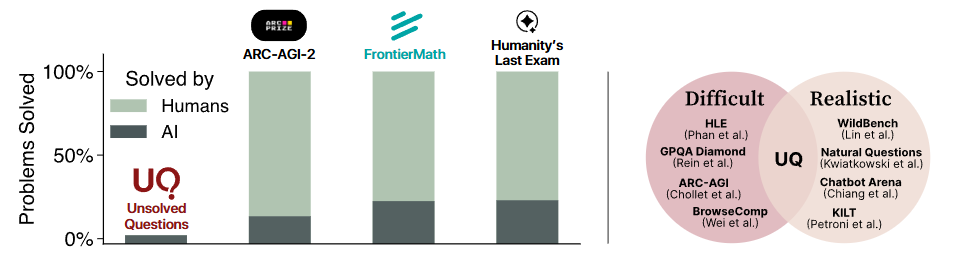
图2|左图展示了一个核心问题:许多现有 benchmark 测试的都是“人类早已解决”的老问题,无法真正推动前沿模型的进步。而 UQ 则专注于那些仍待攻克的、开放式的高难度问题,更贴近真实世界的需求。右图强调了传统评测的矛盾——越难的题越不现实、越现实的题又不够难——而 UQ 正是在解决这种“难度与真实度的拉扯”中诞生的新范式
MedAgentBench: A Realistic Virtual EHR Environment to Benchmark Medical LLM Agents
地址:https://arxiv.org/pdf/2505.13447?
主要内容:
这篇论文在回答一个更根本的问题:
当大模型具备 agent 能力后,我们该如何真正评测它们的“行动能力”?
随着 LLM 从“聊天模型”迈向“智能体模型”,它们被期望能够理解长程任务、调用工具、做计划、处理结构化信息……但现实是:
我们缺乏一个足够真实、足够复杂、足以暴露模型短板的测试环境。
MedAgentBench 正是在这个背景下提出的。它不是简单的问答 benchmark,而是:一个完整的虚拟“环境级”测试框架,专门用于检验 LLM 智能体的真实行动能力。
框架里包含:
● 真实世界级别的数据规模与异质性(对应 agent 的“信息混乱”处理能力)
● 结构化工具与 API 的使用(对应 agent 的“工具调用”能力)
● 长程、细粒度、多步骤任务(对应 agent 的“规划”与“执行一致性”)
● 接近真实系统的交互流程(对应 agent 的“可部署性”)
实验结果也给出了一个健康的信号:
即便是 Claude 3.5 这样的最强模型,成功率也只有 69.67%——说明智能体能力仍然远未饱和。
这恰好证明了:
● 该 benchmark 能够真正暴露智能体系统的瓶颈
● 未来模型仍有巨大提升空间
● 测评智能体的重点正在从“答案”走向“过程”因此
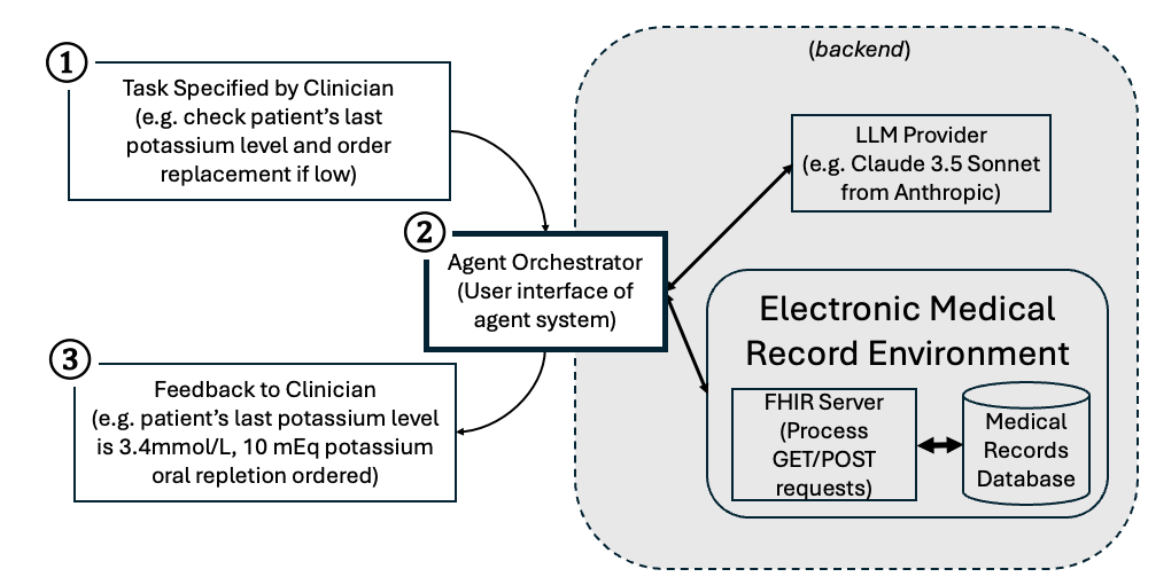
图3|MedAgentBench 智能体框架示意图。整个流程从用户给出一个高层任务开始,智能体调度器便会驱动大模型与系统环境进行多轮交互,实现任务拆解、工具调用与状态更新,并最终返回结构化结果。它更像是在模拟一个真实的“智能体工作流”,用来全面评估大模型在复杂系统中的规划、执行与反馈能力
Evaluating and Improving the Effectiveness of Synthetic Chest X-Rays for Medical Image Analysis
地址:
主要内容:
这篇论文关注的是一个越来越重要的方向:如何用合成数据提升深度学习模型的表现。虽然研究的实验场景是医学影像,但背后的问题在所有数据稀缺的领域都有共性——真实数据昂贵、难获取、且标注成本高,而生成式模型是否能成为新的“数据增压器”?
作者使用 扩散模型(latent diffusion) 生成不同条件下的图像,例如基于文本描述或基于结构化掩码。更关键的是,团队还测试了多种“让合成数据更有用”的方式,包括引入代理模型(proxy model)来筛选样本、加入专家反馈等,最终形成一套生成—过滤—增强的完整流程。
研究的核心发现非常明确:
高质量的合成数据可以显著提升下游模型性能,幅度不小且具有统计显著性。
无论是分类还是分割,合成数据都能稳定提升指标,最高能带来 0.14–0.15 的改进。这说明,只要生成策略合理,合成数据不仅不是噪声,反而可以成为模型性能的关键来源。这类研究对于整个 AI 社区具有更大的启示意义:
未来的数据集构建不再只依赖人工采集,而可能逐渐演变为“真实数据 + 自动生成的数据工厂”的混合模式。
生成模型正在从“做图”走向“造数据”,并成为深度学习训练流程的一部分。
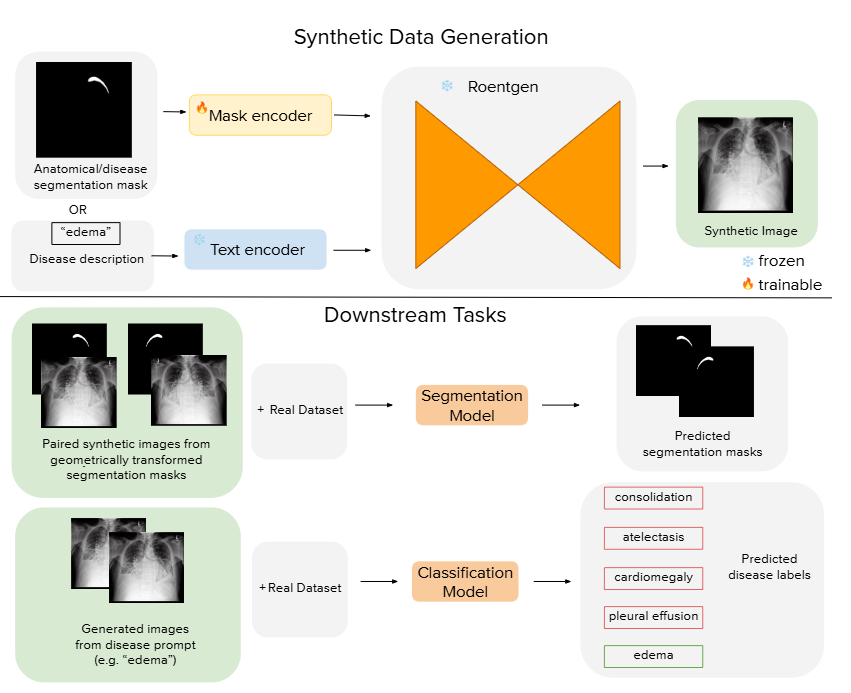
图4|合成数据生成与下游任务提升的整体流程:研究团队利用扩散模型结构(基于 ControlNet)从文本提示或结构化掩码中生成一批高质量的合成图像,这些图像随后被加入到原始训练集中,用于进一步提升模型在分类或分割等任务上的表现。整体流程本质上是一条“生成 → 增强 → 训练”的数据管线,用生成模型为下游学习注入更多有效样本,从而提高模型对结构与语义的理解能力
Regional mapping of natural gas compressor stations in the United States and Canada using deep learning on satellite imagery
地址:
https://www.sciencedirect.com/science/article/pii/S0301479725027045
主要内容:
这项工作展示了深度学习在大尺度空间分析中的一个典型应用:利用卫星图像自动识别难以人工统计的基础设施。虽然论文聚焦于天然气压缩站这种特定设施,但其核心思想具有普适性——通过训练视觉模型,让 AI 从遥感图像中自动定位关键结构,弥补传统数据库的缺口,并为环境监测、资源管理等更大范围的问题提供更加可靠的数据基础。
研究团队系统评估了多种神经网络架构、不同分辨率的卫星图像以及多种输入区域设置,最终模型在保持 0.95 的高召回率下,实现了 0.81 的精确率。同时,他们还探索了多模态特征融合:当模型同时考虑“与管道是否靠近”等结构化信息后,精度进一步提升。这种“图像 + 结构属性”的结合方式,对于提升复杂场景下的识别准确率具有普遍意义。
当模型被大规模部署到 20 万平方公里的区域进行自动检索后,它不仅发现了大量数据库中缺失的基础设施,还揭示了依赖传统上报数据会造成严重误判的问题——例如对人群暴露风险的低估。这说明 AI 驱动的遥感识别有潜力成为未来环境管理、资源规划和公共安全评估中的关键工具。
整体来看,这项研究并不只是“找到更多设施”,而是展示了深度学习如何帮助我们构建更完整、更真实的世界数据图谱,为数据匮乏的领域带来结构化、可扩展的检测能力。
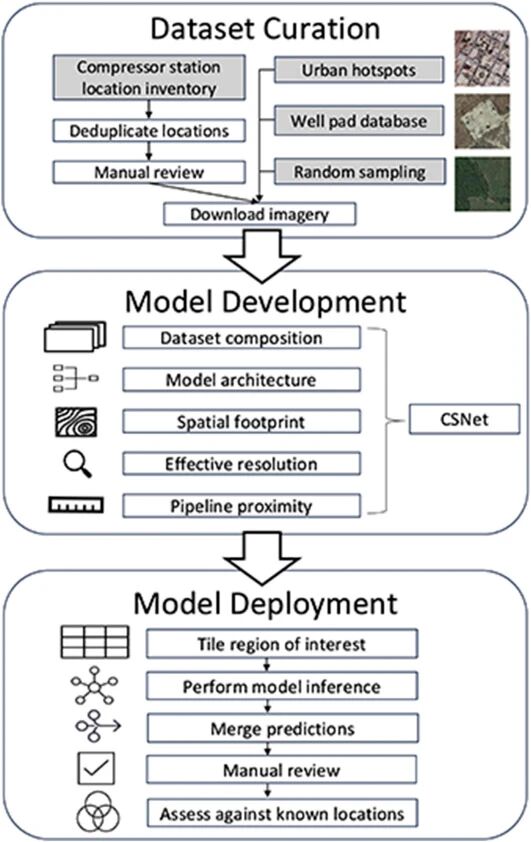
图5|分形生成模型结构示意。 左图展示生成器的层级结构,右图展示模型生成的“分形式”结果。研究者通过在自回归模型中递归调用自回归模块,构建出具有多层自相似特征的生成体系,实现了跨层结构的统一表达。该机制不仅增强了模型的可扩展性,也揭示了生成网络在不同层级间共享结构规律的可能
STARC-9: A Large-scale Dataset for Multi-Class Tissue Classification for CRC Histopathology
地址:https://openreview.net/pdf?id=rGWjTlK6Ev
主要内容:
在医学影像这样的高风险场景里,模型能不能「看得准」,往往取决于训练数据够不够多、够不够丰富。而现实情况是:公开的医学数据通常规模有限、类别不平衡、形态单一,还常常夹杂大量低质量样本——这让下游 AI 模型很难真正具备泛化能力。
吴恩达团队提出的 STARC-9 正是在解决这个基础却关键的问题。
这是一套 63 万张、涵盖 9 类组织类型的大规模医学视觉数据集,来自 200 名真实病例,并经过严格、系统的筛选与验证。更重要的是,它背后不是靠大量人工逐张挑选,而是使用了团队提出的 DeepCluster++ 自动化数据构建框架:
● 先用自监督模型提取图像表征,确保能识别组织形态的细微差异;
● 再用聚类与均匀采样技术,从成千上万张影像中挑出最具“代表性”的样本,保证每个类别的多样性;
● 最后由病理专家确认标签,确保整个数据集的可靠性。
这种 “AI 预筛 + 专家校准” 的流程,既大幅降低人工成本,也确保数据够多样、够干净。
团队还在多个任务上验证了其价值:无论是 CNN、Transformer,还是医学领域的大模型,在 STARC-9 上训练后,其泛化性能都明显优于使用现有公开数据集的模型。
STARC-9 的意义远不止医学本身——
它展示了如何 用自动化方法高效构建高质量数据集,这是任何需要大规模标注、且领域知识昂贵的场景(如化工材料、遥感、工业视觉)都能够借鉴的思路。
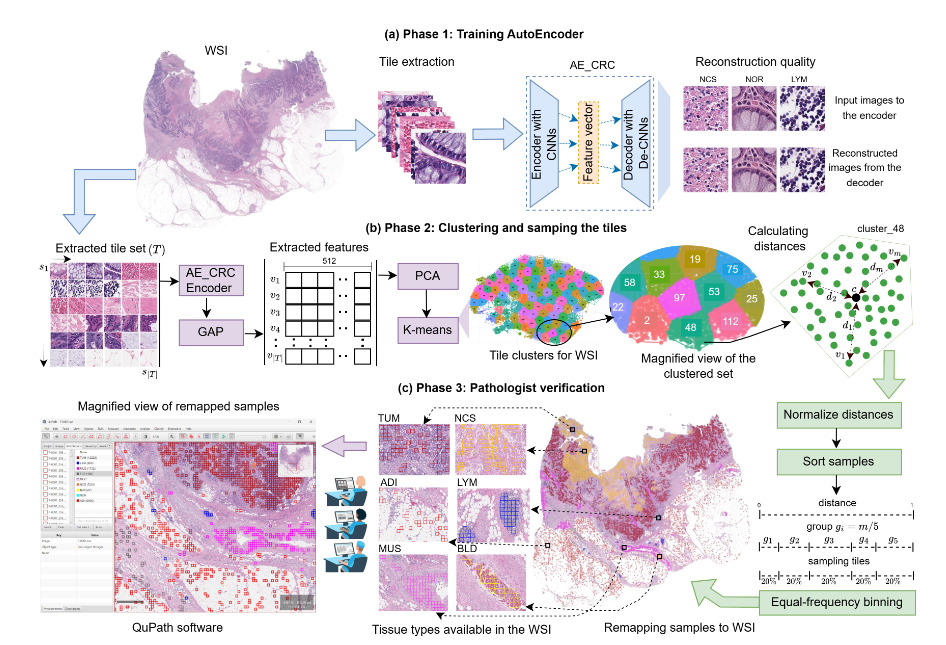
图6|DeepCluster++ 数据构建框架示意。整个流程分为三阶段:前两阶段由模型自动完成,最后由专家进行验证。首先,系统使用自监督自动编码器提取图像特征,并通过全局平均池化与 PCA 降维,获得更紧凑的表示;随后利用聚类与均匀采样策略,从海量图像中挑选出多样化的代表样本;最终,再由领域专家进行人工审核,确保数据标注的准确性与可靠性。这个“模型筛选 + 专家把关”的混合流程,让大规模高质量数据构建更加高效、可控
Deep learning for detecting and characterizing oil and gas well pads in satellite imagery
地址:https://www.nature.com/articles/s41467-024-50334-9
主要内容:
这项工作本质上展示了一个越来越重要的 AI 能力:利用深度学习从遥感影像中自动构建大规模空间基础设施数据库。虽然论文以油气行业为应用场景,但其核心思想对更广泛的 AI 领域都具有代表性——在缺乏完备人工数据的场景,通过机器学习来自动填补地理信息的巨大缺口。
作者使用公开的高分辨率卫星影像,并构建了一个端到端的检测模型,用于识别大片区域中的井场及其附属设施。技术上,这项研究体现了三个关键价值点:
● 大范围自动检测能力:模型在专家标注集上取得非常高的精度与召回率,证明深度学习可以在遥感影像这种噪声复杂、类别稀疏的场景中实现稳定识别。
● 发现"未被记录的实体":真正令人惊讶的是,当模型部署到整个盆地后,它识别出了数以万计的“数据库里不存在”的井场和储罐——这说明深度学习不仅能模仿人工标注,还能主动发现新的结构,体现了自动化地图构建的潜力。
● 走向全球尺度的基础设施映射框架:虽然应用于油气行业,但方法可以迁移到电网、道路、建筑物、农业设施等众多场景,为 AI 参与构建全球高质量地理空间数据库提供了方向。
整体来看,这项研究展示了 AI + 遥感的一条现实路径:让深度学习成为“全球基础设施地图”的构建者,在数据缺乏与规模巨大并存的领域带来真正的突破。
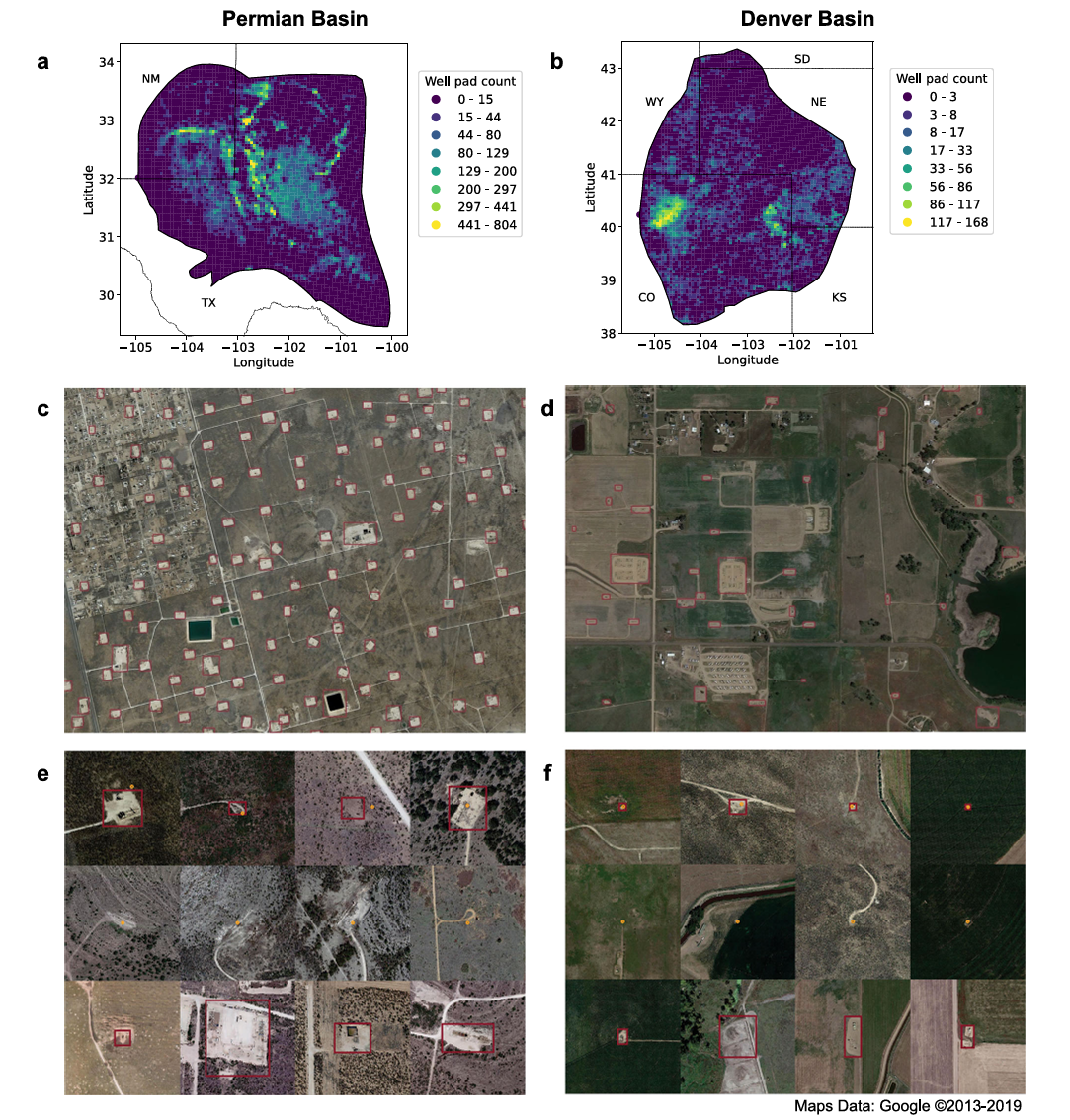
图7|基于深度学习的大范围井场自动识别示意(a–b) 模型在两个大型盆地上的部署结果,以 5 km² 为网格生成密度热力图,展示 AI 自动检测到的井场分布。(c–d) 放大后的局部区域中,模型给出的井场预测以洋红色框标注。(e–f) 展示了模型识别出的三类典型结果:成功捕捉的井场、未能识别的井场、以及现有数据库中从未记录过的新井场(均以洋红色框显示)。橙色圆点代表已有的人工或官方数据,用于对比模型的自动检测能力
总结
回顾吴恩达在过去一年的研究与实践,可以看到一个十分鲜明的趋势:他正在推动 AI 从“实验室能力”迈向“真实世界能力”。无论是面向医疗场景的智能体评测、用于工业流程的自动化视觉系统,还是针对环境监测与公共安全的卫星影像识别,再到合成数据、长上下文模型、多模态多任务学习,这些工作虽覆盖不同领域,却指向同一个核心变化——AI 不再是学术问题,而是工程问题;不再是模型能否更强,而是能否真正解决现实世界的复杂性、不确定性与规模化挑战。
在吴恩达的最新研究轨迹中,我们看到他持续强调三个理念:
让 AI 更可用,让数据更可靠,让系统更工程化。
因此,他的论文常常围绕大规模数据构建、自动化标注、场景级模型评测、多模态推理一致性、代理系统可控性等展开——这些都是大模型进入真实应用不可绕开的“硬问题”。这些研究不仅推动特定行业的 AI 升级,也为整个社区提供了“如何构建可信赖的 AI 系统”的实践模板。如果说早期的吴恩达帮助世界理解了深度学习的潜力,那么当下的他,正在帮助世界理解怎样把 AI 真正用起来。他的研究逐渐从算法创新转向系统能力建设,从模型精度转向部署可靠性,从理论突破转向产业落地——这也让他的最新成果呈现出“更务实、更系统、更贴近真实需求”的特点。
关键词总结:工程化、可用性、可控性、多模态、长程推理、数据构建、真实场景落地。
可以预见,随着他持续推动 AI 的普惠化与产业化,吴恩达未来几年的研究将越来越聚焦“让 AI 真正融入社会”的那部分关键能力,而这或许将成为深度学习时代的下一段主线

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









