



目录
4 深度学习范式在 EDM 中的总体框架:监督、无监督与强化学习如何落到教育任务
5.1 知识追踪(Knowledge Tracing):从“下一题对不对”到“知识状态如何演化”
5.2 学生行为检测(Student Behavior Detection):把“行为模式”从日志中识别出来
5.3 学习表现预测(Performance Prediction):从“成绩回归”到“过程驱动的能力估计”
5.4 个性化推荐(Personalized Recommendation):从打分预测到序列决策与可解释路径
7.1 评价指标的语义:AUC/ACC/F1 与 HR/NDCG/MRR 的差别不是“数学细节”
7.2 序列模型与注意力:何时用 LSTM,何时用 Transformer,不应只看流行度
7.3 图结构注入:KG/GNN 不是装饰品,而是解决“多技能与稀疏”的结构性工具
7.4 强化学习与可解释性:奖励、状态与动作空间的设计决定上限
参考文献:Lin, Y., Chen, H., Xia, W. et al. A Comprehensive Survey on Deep Learning Techniques in Educational Data Mining. Data Sci. Eng. (2025). https://doi.org/10.1007/s41019-025-00303-z
1 引言
教育活动天然会产生数据:课堂与作业中的答题轨迹、在线平台的点击与停留、视频观看与回看、作业提交与互评、讨论区的互动网络、甚至更细粒度的时间序列与行为事件流。教育数据挖掘(Educational Data Mining, EDM)试图把这些“行为痕迹”转化为可解释、可预测、可干预的学习画像,用于刻画掌握程度、发现风险、提升资源匹配与教学决策质量。传统机器学习在 EDM 中长期有效,但也暴露出两类典型瓶颈:其一,教育数据往往是强序列与强依赖的(学习行为的前后关系、知识点之间的先修结构、遗忘与巩固的动态过程);其二,数据形态高度异构(离散交互、文本、图结构、稀疏矩阵并存),靠手工特征很难把“学习过程”本身的结构完整表达出来。随着深度学习在序列建模、表示学习、图结构建模与端到端训练上的能力成熟,EDM 的方法论逐步从“特征工程驱动”推进到“表示学习驱动”,并在四类高频教育场景中形成相对稳定的研究主线:知识追踪、学生行为检测、学习表现预测、个性化推荐。这些场景与研究数量随年份变化的整体趋势,如图1所示(截至 2024 年末的按年统计分布)。
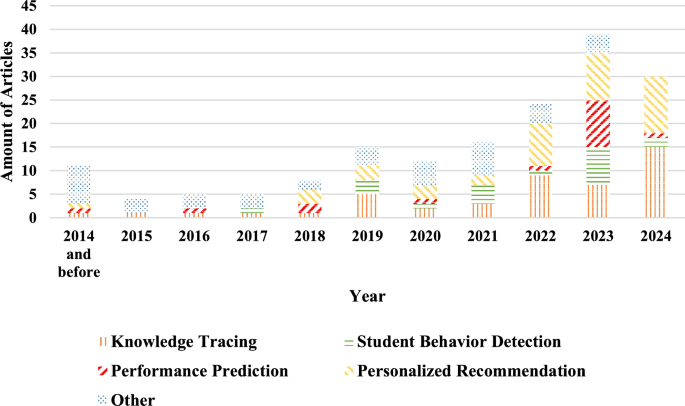
【图1 Distribution of year-wise publications——用于展示不同教育场景随年份的研究数量分布】
如果把 EDM 看作“把学习过程写成可计算的函数”,那么深度学习的意义并不止于提升 AUC/ACC;更关键的是,它提供了一组可复用的结构化工具:对离散符号交互做嵌入;对行为序列做递归或注意力建模;对资源与知识之间的关系做图传播;对偏好与反馈做强化学习优化;对缺少标注或标签稀缺的情形做生成式或自监督表征学习。为了让这些方法能在工程上落地、在理论上可解释,必须先把“教育任务”形式化,再把“深度模型”拆成输入、表示、结构、目标函数与评价指标几条线索逐一梳理。下文将以“理论基础—任务形式化—算法范式—四大场景方法族—数据与工具—建模要点”的顺序,做一篇更接近学位论文写法的系统总结(发布到博客时可自行删除文末链接与引用标记)。
2 理论知识与技术基础
2.1 教育数据的形式化:事件流、序列、图与稀疏矩阵
教育数据最常见的原子单位不是“静态样本”,而是“交互事件”。例如一次做题可被记作 (student, exercise, concept, correctness, timestamp),一次视频观看可被记作 (student, video, watch_time, seek, pause, timestamp)。当这些事件按时间排序,就形成学习行为序列;当事件按“学生—题目—知识点—课程—资源”连边,就形成异构关系图;当只保留“用户×资源”的偏好或交互强度,又回到稀疏矩阵。不同表示方式决定了模型结构:序列更适合 RNN/LSTM/Transformer,图更适合 GCN/GAT/异构图网络,稀疏矩阵更适合嵌入+交互函数(内积、MLP、因子分解型结构)。在教育任务中,很多“输入”本质上是离散符号(题目 ID、知识点 ID、课程 ID、行为类型),因此嵌入层几乎是标配,它把离散索引映射到连续向量空间,从而让“相似资源/相似行为”的几何邻近性可被学习出来。
2.2 监督学习的目标函数:从分类到排序
在答题正确率预测、风险预警、作业评分等任务中,监督学习最常见。其核心是定义一个从输入到输出的可微函数 f(x; θ),并最小化经验风险。对二分类(如下一题对/错、是否辍学)常用交叉熵;对多分类(如学习风格类别、知识状态分段)常用 softmax+交叉熵;对回归(如分数、得分区间的期望)常用 MSE/MAE。softmax 的标准形式在教育表现预测的相关讨论中经常出现:
$$\mathrm{softmax}(z_i)=\frac{e^{z_i}}{\sum_{j=1}^{K}e^{z_j}},\quad i=1,2,\ldots,K$$
其中 z_i 表示模型对第 i 类的未归一化打分(logit),K 为类别数;softmax 把这些打分归一化成概率分布,用于后续的交叉熵最小化。
当任务从“预测正确/错误”转向“推荐排序”(课程/资源推荐)时,目标函数常从点式损失扩展到 pairwise/listwise:例如希望正样本分数高于负样本分数,或者直接优化 NDCG/MAP 等排序指标的代理损失。教育推荐的特殊性在于:正反馈不只是点击/购买,还可能是“坚持学习、完成作业、成绩提升”等多阶段信号,因此很多框架会把推荐视为序列决策而非一次性打分,后文在强化学习部分展开。
2.3 表示学习与自编码器:从重构到迁移
在标注不足、标签昂贵或希望学到更通用表征时,表示学习与自编码器体系很常用。其思想是把输入 x 编码成潜变量 q,再从 q 重构出 x̂,使 q 捕获对任务有用的结构信息。教育场景中,自编码器常被用来把题干文本、行为片段或多模态特征压缩成更稳定的嵌入表示。一个典型的编码—解码形式可写为:
$$\text{Encoder: } q=\pi_e(x),\qquad \text{Decoder: } \hat{x}=\pi_d(q)$$
其中 x 可对应题目文本或其他输入特征,π_e 为编码函数,π_d 为解码函数;通过重构约束,模型在没有显式标签的情况下也能学习到可迁移的语义表示,并可把该表示接入后续预测头或序列模型中。
2.4 图神经网络与知识图谱:结构归纳偏置
教育里的“知识点—题目—课程—先修关系”天然适合图结构。知识图谱(Knowledge Graph, KG)把教育要素抽象成节点与边(如 pre-requisite、belongs-to、covers、similar-to),图神经网络(GNN)通过邻居聚合把局部结构信息传播到节点表示上,解决“仅用序列看不到结构关联”的缺陷。在知识追踪中,GNN 提供对“知识点关联”“多技能题目”的结构建模;在推荐中,GNN 提供对“课程—概念—资源—用户”的多跳关联推理;在行为检测中,图结构则可以来自社交互动或行为共现网络。GNN 的关键不是某一条公式,而是它提供的归纳偏置:相连即相关、结构可传播、局部可组合成全局。
2.5 生成模型与能量函数:RBM/DBN 的另一条线
在无监督或半监督场景中,一些方法会使用生成式思想学习潜在结构,例如受限玻尔兹曼机(RBM)与深度信念网络(DBN)。其核心是用能量函数刻画可见层与隐层的联合分布。典型 RBM 能量形式如下:
$$E_{\theta}=-\sum_{i=1}^{n_v} b_i v_i-\sum_{j=1}^{n_h} a_j h_j-\sum_{i=1}^{n_v}\sum_{j=1}^{n_h} v_i w_{ij} h_j$$
其中 v 为可见层状态向量,h 为隐层状态向量;a_j、b_i 分别是隐层与可见层偏置,w_{ij} 为连接权重;能量越低代表该配置越“可能”。在教育推荐或学习风格识别中,这类模型可在标签稀缺时学习用户/资源的潜在结构,但也往往面临训练稳定性与可扩展性挑战。
2.6 强化学习:把推荐与学习路径当作序列决策
当目标不只是“预测”,而是“在多步交互中逐步优化学习效果”,强化学习(RL)成为自然选择。它把学习路径推荐建模为马尔可夫决策过程(MDP):状态 s_t 表示学习者当前画像与上下文,动作 a_t 表示推荐的资源/下一步学习任务,奖励 R(s_{t+1}) 表示反馈(完成度、掌握提升、满意度等)。策略梯度或 actor-critic 常用于此类问题。一个策略相关的累计回报形式可写为:
$$G(\theta)=\frac{1}{m}\sum_{u=1}^{m}\sum_{t}\sum_{a}\pi\!\big(a\mid s_t, A(s_t)\big)\,\gamma^{t}\,R(s_{t+1})$$
其中 θ 为策略网络参数,m 为样本(或用户)数量,π(a|s_t, A(s_t)) 为在状态 s_t 下选择动作 a 的概率,γ 为折扣因子,R(s_{t+1}) 为下一状态的即时回报。直观上,这类目标推动策略在长期收益意义下选择更优的学习资源序列,而不是只优化短期点击或单次评分。
3 EDM 的典型任务与场景:问题定义、输入输出与评价方式
教育场景的任务看似众多,但在工程上,常被归并到若干“可监督/可排序/可决策”的问题模版中。为了避免概念漂浮,可先把四类主线场景用统一结构描述:数据从哪里来、核心要预测什么、特征长什么样、常用技术是什么。下表给出一份面向落地的“场景—用户行为—关键特征—技术主线”对应关系(译写自一份公开梳理的汇总表)。
| 场景 | 用户典型行为 | 常见关键特征(示例) | 主要技术主线(示例) |
|---|---|---|---|
| 知识追踪(Knowledge Tracing) | 做题、作业、测验、练习 | 题目/知识点 ID,答题正确性,时间间隔,题目难度,学习时长等 | LSTM/Transformer 序列建模,注意力机制,知识图谱/图神经网络,强化学习策略优化等 |
| 学生行为检测(Student Behavior Detection) | 课堂/在线学习行为、交互动作 | 视频观看行为特征、点击序列、互动网络、行为模式统计 | CNN/RNN/GCN 结合的多分支特征提取,注意力聚合,序列与图混合建模等 |
| 学习表现预测(Performance Prediction) | 课程学习、测验与作业提交 | 互动日志、学习路径、作业/测验历史成绩、课程与学生属性等 | MLP/CNN/RNN/LSTM,注意力机制,GAN 生成式辅助,部分情形引入 RL 做过程优化等 |
| 个性化推荐(Personalized Recommendation) | 选课、资源浏览、学习路径选择 | 用户—资源交互矩阵、序列行为、知识结构关联、冷启动辅助特征等 | DNN/序列模型、GNN+KG 关系推理、GAN 表征学习、RL 做序列推荐与可解释路径推理等 |
表中的“主要技术主线”并不意味着一招鲜吃遍天;恰恰相反,教育数据的一个典型难点是:同一任务在不同平台与人群上会呈现截然不同的数据分布与噪声形态,因此算法选择必须同时考虑数据粒度、序列长度、标注质量、结构信息是否可得,以及评价指标到底关心的是准确率、排序质量还是长期效果。
4 深度学习范式在 EDM 中的总体框架:监督、无监督与强化学习如何落到教育任务
4.1 监督学习:把“学习过程”映射到可预测目标
监督学习在 EDM 中最常见,因为平台往往能提供明确标签:答题对错、课程是否完成、是否辍学、期末成绩区间等。教育任务的关键在于“输入的结构化”:学习者的行为不是 IID 样本,而是随时间演化的序列;因此监督学习的主要差异不在损失函数,而在模型结构——是用 LSTM/GRU 表达遗忘与巩固,还是用 Transformer 表达长程依赖与多关系注意力,还是用 GNN 把知识结构显式注入。监督范式的优势是训练稳定、评价清晰,但也容易因为“平台策略导致的选择偏差”而把相关性当因果性;另外,过度追求指标可能牺牲可解释性,尤其在教育的高风险决策(预警与干预)场景中更敏感。
4.2 无监督/半监督:当标签稀缺时如何学到可用表征
教育平台不一定总能提供高质量标签。比如“学习风格”“学习投入度”“课堂专注”等,标注昂贵且主观。此时无监督与生成式方法通过重构、对比、生成来学习潜表征,往往先解决“把数据压缩成可学习表示”的问题,再把表示接给小样本监督头。以 GAN 为例,它可以在成绩预测等任务里通过生成器—判别器机制拟合数据分布,缓解小样本问题;以 RBM/DBN 为例,它可以用能量模型学习隐变量结构,用于分类或推荐的特征基础。无监督方法的代价通常是训练更难调、稳定性更依赖技巧,且结果解释更挑战。
4.3 强化学习:把“推荐—反馈—更新”变成闭环优化
在教育推荐与学习路径规划里,推荐系统不是静态打分器,而是与学习者持续交互的决策系统。一个典型闭环是:用用户数据与课程数据建模,推荐引擎给出资源,用户反馈(学习、完成、成绩变化)再反向更新模型,如图2所示。这类闭环天然适合 RL:策略需要在探索与利用之间权衡;奖励设计需要在短期与长期之间权衡;状态空间需要能表达“掌握程度随时间变化”的动态。RL 的吸引力在于它能直接对“序列推荐策略”做优化,并且在引入知识图谱路径推理后,还能提供一定程度的可解释推荐(例如展示从学习历史到推荐课程的连接路径)。
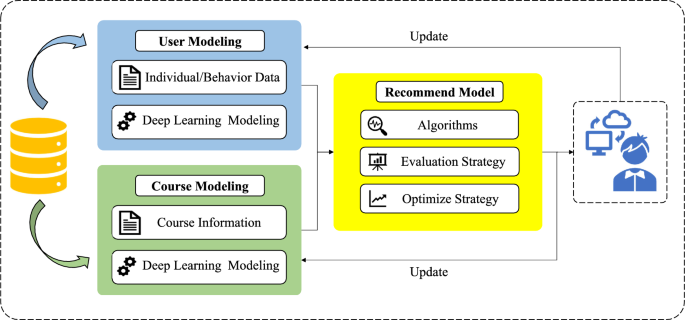
【图2(A general process framework for personalized recommendation in EDM)——展示推荐系统闭环:建模→推荐→反馈更新】
5 四大教育场景的理论总结:建模对象、代表性结构与方法族
5.1 知识追踪(Knowledge Tracing):从“下一题对不对”到“知识状态如何演化”
知识追踪的核心目标是:根据学习者历史交互序列,估计其对各知识点的掌握程度,并预测下一次交互(如下一题是否答对)。一个直观示意是:每道题可能涉及多个知识点,不同颜色对应不同概念;答题对错会改变对概念掌握的判断;掌握程度可被视作随时间变化的隐状态,如图3展示的简化框架。
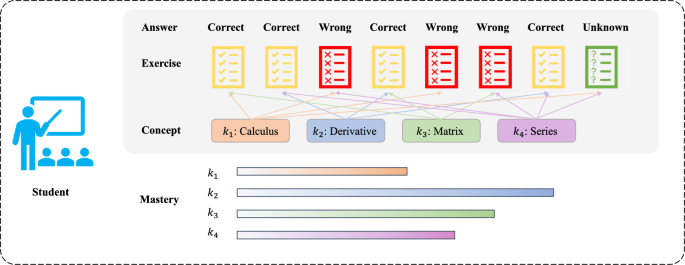
【图3 展示题目—概念—掌握度与对错反馈关系】
从理论上看,知识追踪可以被视作带隐状态的序列建模问题:输入是交互事件序列 X_1…X_t(题目、概念、作答结果、时间等),输出是下一步结果或知识点掌握向量。早期方法倾向用概率图模型表达“掌握/未掌握”的转移;深度学习路线则更多把隐状态 h_t 当作由网络递推得到的表示。LSTM/GRU 的价值在于它们用门控机制表达遗忘与信息保留;注意力机制的价值在于它能从历史序列中“挑选对当前预测更相关的片段”;Transformer 的价值在于它用多头注意力表达复杂关系并改善长序列依赖;图神经网络的价值在于它把知识点之间的结构显式注入,尤其当题目涉及多技能或知识点存在先修关系时,纯序列模型容易忽略结构约束。
为了让读者对“研究中到底怎么做”有更具体的把握,下表给出该场景中不同算法范式下的模型例、方法与常用指标/数据集配置(按公开汇总表译写并做了按场景拆分;模型名与指标缩写保持原样,便于对照)。
| 知识追踪场景中的模型例 | 算法范式 | 方法类型 | 常见评价指标 | 常用数据集 |
|---|---|---|---|---|
| DKT | 监督学习 | RNN | AUC/ACC | ASSISTments09/12 |
| DKT-STDRL | 监督学习 | CNN | AUC/ACC | ASSISTments12 |
| Deep-IRT | 监督学习 | DNN | AUC/ACC | ASSISTments09/12 |
| DKT-SST | 监督学习 | DNN | AUC | ASSISTments12 |
| QPPRI | 监督学习 | DNN | ACC/Precision/Recall/F1 | ASSISTments17 |
| SAKT | 监督学习 | Attention | AUC/ACC | ASSISTments09/12/EdNet |
| MRTKT | 监督学习 | Attention | AUC/ACC | ASSISTments09 |
| GIKT | 监督学习 | GCN | AUC | ASSISTments09/12 |
| FCKT | 监督学习 | GCN | AUC | ASSISTments12/EdNet |
| HHKST | 监督学习 | GNN | AUC/ACC | ASSISTments09/12 |
| AE-based DKT | 无监督学习 | AutoEncoder | AUC/ACC | ASSISTments09/12/EdNet |
| RL-KTNet / IEKT 等(示例) | 强化学习 | RL(Policy/ε-greedy 等) | AUC/ACC 等 | 多数据集 |
这一表格背后其实体现了知识追踪建模的三条“结构主线”。第一条是序列主线:把交互编码成向量序列,再用 RNN/LSTM/Transformer 得到上下文表示,预测下一步;第二条是关系主线:把题目—知识点—先修信息做成图,通过 GCN/GAT 把结构嵌入注入序列模型,解决多技能与概念关联;第三条是决策主线:把“下一步学什么”或“如何出题自适应测评”视作策略优化,把追踪与优化连接起来。真正的理论难点并不是结构名字,而是如何让隐状态具备合理语义:既能随时间演化,又能与知识结构对齐,还要能在评价指标上稳定提升而不靠数据泄漏或过拟合。
5.2 学生行为检测(Student Behavior Detection):把“行为模式”从日志中识别出来
学生行为检测关注的往往不是“掌握程度”,而是“正在发生什么样的学习行为与学习状态”。在线学习中,这可能对应观看行为是否投入、是否走神、是否存在异常绕过;线下课堂中,可能对应注意力、互动网络与合作模式。由于行为特征可能同时包含序列、统计特征与结构关系,很多方法会采用多分支结构:一支用 CNN 做局部模式提取,一支用 GCN 做结构传播,一支用 LSTM 表达时间依赖,再用注意力机制融合。在图4所示的简化结构里,可以看到卷积与池化、GCN、注意力机制、残差连接等组件共同构成对行为数据的多角度表征。
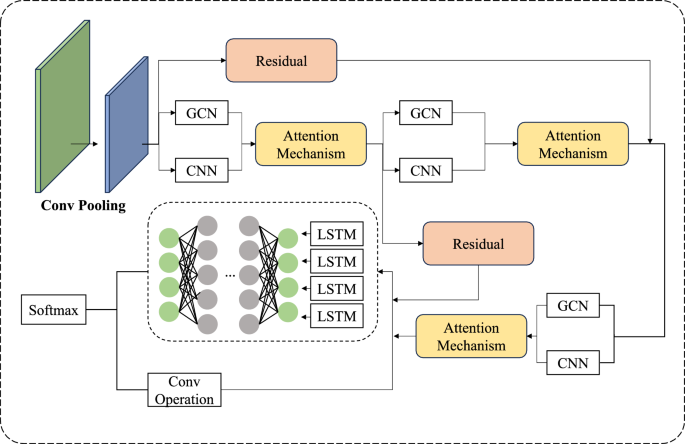
【图4(A simple structure of ATGCN model)——展示 CNN/GCN/LSTM/Attention 等的融合结构】
从理论角度理解这种融合结构,关键是把“行为检测”拆成两步:先做特征表示(从原始行为日志或行为片段中提取多尺度表示),再做证据聚合(把不同来源的表示通过注意力或门控融合成决策表征)。卷积擅长捕捉局部模式,适合对短窗口行为片段做“行为纹理”识别;RNN/LSTM 擅长表达时序演化,适合“行为阶段”迁移;GCN/GAT 擅长表达关系依赖,适合行为共现网络、社交互动或资源—行为的结构关联;注意力机制则提供可解释的“权重分配”,让模型在融合时更像“选择证据”而不是简单拼接。
同样给出该场景的一组汇总表条目,用于对照“常见模型—方法—指标—数据集”的组合方式(译写自公开汇总表的相应分段)。
| 学生行为检测场景中的模型例 | 算法范式 | 方法类型 | 常见评价指标 | 常用数据集 |
|---|---|---|---|---|
| MoNet | 监督学习 | CNN | AUC | Self-collected |
| SEFD | 监督学习 | CNN | AUC/Precision/Recall/F1 | Online classroom |
| FNO | 监督学习 | CNN | AUC/F1 | Online classroom |
| ATGCN | 监督学习 | CNN(融合结构) | ACC | N/A |
| Faster R-CNN | 监督学习 | CNN | ACC/Precision/DR/FDR | TCE Classroom |
| CFN | 监督学习 | CNN | AUC/F1 | KDD Cup2015/XuetangX |
在“行为检测”里,理论上的最大风险是把平台机制或采集偏差当作行为规律,例如不同课程资源布局造成的点击差异可能被模型误判为学习投入差异。因此解释性与稳健性变得更重要,尤其是当检测结果会触发干预时。工程上常见的缓解手段包括:加入上下文特征(课程结构、资源类型)、做域适配或分层建模、用注意力可视化或门控权重解释证据来源,但这些属于方法论层面,核心仍然是:行为检测必须对“什么是行为、行为如何被观测”保持敏感。
5.3 学习表现预测(Performance Prediction):从“成绩回归”到“过程驱动的能力估计”
学习表现预测通常以分数、等级、是否通过等为目标。它与知识追踪相近但不等价:知识追踪更强调细粒度掌握状态与下一步交互预测;表现预测更强调对总体表现的预测,输入可能是多源融合(历史成绩、互动日志、课程属性、学生属性、行为特征),输出可能是回归或分类。其理论难点在于:表现往往是多因素耦合的结果,行为日志对表现的影响不一定线性;同时教育数据稀疏、缺失与噪声普遍存在,容易产生过拟合或“用时间泄漏信息”的假提升。
一些结构会把视频观看行为做序列特征(LSTM),把课程与学生特征做嵌入或线性变换,再拼接给 DNN 预测头。图5给出了一个以辍学预测为目标的简化结构示例,体现了“多源特征→序列编码→全连接融合→预测”的典型套路。
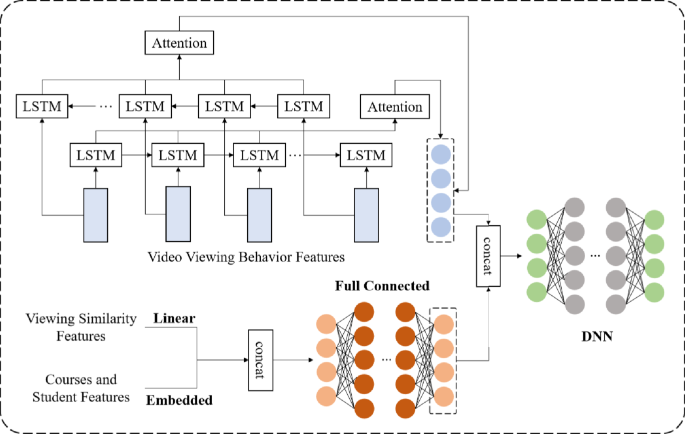
【图5 (A simple structure of LBDL model)——展示观看序列特征与课程/学生特征融合后进入 DNN 的结构】
为了更具体地呈现该场景常用的模型条目组合,下面给出汇总表中“表现预测”分段的一部分(同样保持模型名与指标缩写,便于检索对照)。
| 学习表现预测场景中的模型例 | 算法范式 | 方法类型 | 常见评价指标 | 常用数据集 | 年份 |
|---|---|---|---|---|---|
| LBDL | 监督学习 | LSTM | AUC/F1 | MOOCCube | 2023 |
| CDLSTM | 监督学习 | LSTM | AUC/Recall/Precision/F1 | 7WiseUp | 2023 |
| ECLSTM | 监督学习 | LSTM | AUC/Recall/Precision/F1 | KDD Cup2015 | 2024 |
| DL-MLP | 监督学习 | MLP | ACC | Pennsylvania School Performance Profile | 2023 |
| CRN | 监督学习 | CNN | FDR/Sens/FPR/MCC/F1/NPV/FNR | Kaggle | 2023 |
| UPC-Net | 监督学习 | CNN | Recall/Precision/F1 | Self-collected | 2024 |
| MLP-12Ns | 监督学习 | MLP | RMSE | Kaggle | 2023 |
| CGAN | 无监督学习 | GAN | AUC | Self-collected | 2022 |
表现预测里“GAN 也能用”的意义,不在于 GAN 魔法般提升分数,而在于它尝试用生成机制建模数据分布,从而在小样本或分布偏移时提供更稳健的表征;但代价就是训练更复杂、稳定性更敏感。至于强化学习在该场景中的角色,更多是用于优化相关过程(如自适应测验、学习策略调整)而非直接预测分数,这一点也与场景本身的目标函数结构有关:预测是静态目标,优化是动态目标。
5.4 个性化推荐(Personalized Recommendation):从打分预测到序列决策与可解释路径
教育推荐的“物品”不再是商品,而是课程、视频、练习、学习路径与知识点组合。推荐目标也往往比“点击率”更复杂:既要满足兴趣,又要匹配能力区间,还要避免过难挫败或过易无聊,并兼顾先修结构。一个标准形式化是:给定 M 个用户、N 个物品(此处可替换为课程/资源),交互矩阵为 R,预测矩阵为 R̂;用户 u 对物品 i 的偏好可记为 r_ui,预测为 r̂_ui,并存在用户向量 r(u) 与物品向量 r(i) 的部分观测。围绕这一形式化,推荐系统在教育中的典型流程框架与闭环更新机制如 Fig. 5 所示:用户与课程数据用于建模,推荐引擎产生建议,反馈更新模型以持续改进。
在方法族上,监督学习路线往往用 DNN/序列模型/注意力来融合异构特征与行为序列;图与知识图谱路线用 GNN 在 KG 上传播与推理,缓解稀疏并增强语义关联;无监督路线用 GAN/RBM/DBN 在缺少标签或偏好不完整时学习潜在结构;强化学习路线把推荐视为持续决策,优化长期收益,并在引入 KG 路径推理后可提供“为什么推荐”的解释线索。为了给出更具操作感的参考,下面把汇总表中“个性化推荐”相关条目做一段译写整理(再次强调:模型名、指标缩写保留,便于工程人员检索)。
| 个性化推荐场景中的模型例 | 算法范式 | 方法类型 | 常见评价指标 | 常用数据集 | 年份 |
|---|---|---|---|---|---|
| BERT(用于推荐表征) | 监督学习 | Attention | Recall/Precision/F1 | MOOCCube | 2023 |
| SODNN | 监督学习 | DNN | Precision | UBOB | 2023 |
| ARGE | 监督学习 | RNN | AUC | LastFM/Movielens-100K/Yelp | 2023 |
| KAUR | 监督学习 | GNN | Recall/NDCG | MovieLens-100K/Amazon-book/LFM-1B | 2023 |
| PCGNN | 监督学习 | GNN | HR/MRR | Udemy1/XueTangX | 2024 |
| CR-LCRP | 监督学习 | HIN | AUC/NCDG/MRR/HR/AP | MOOCCube/MOOC review | 2024 |
| RecGAN | 无监督学习 | GAN | NDCG/MRR/MAP | MPF | 2018 |
| DBNLS(学习风格/推荐相关) | 无监督学习 | DBN | Act/Ref/Sen/Int | StarC | 2020 |
| CSEAL | 强化学习 | Actor-Critic | AUC/Recall/F1/MAP | Junyi | 2019 |
| MEUR | 强化学习 | Q-Learning | IR/HR/NDCG/MRR | MOOCCube | 2023 |
| RPPR / HELAR / HRRL / HRL-NAIS / KRRL / UPGPR 等 | 强化学习 | REINFORCE / AC 等 | HR/NDCG 等 | MOOCcourse/MOOCCube 等 | 2019–2024 |
推荐场景里最值得强调的理论点是:教育推荐往往同时追求“兴趣匹配”和“学习适配”,这使得奖励设计非常关键。若只用点击/选择作为奖励,会把系统推向短期满意但长期无益的“轻量内容”;若奖励只看成绩提升,又会引入滞后与噪声。于是实际系统常把奖励拆成多项加权,或引入层级策略(先选难度段,再选资源),并以 KG 的路径推理作为解释层。也正是在这一层,RL 与 GNN/KG 的耦合具有更清晰的理论动机:RL 负责“决策”,KG 负责“语义与结构约束”,二者结合更像在做“带知识约束的策略优化”。
6 数据集与处理工具:公开资源如何支撑可复现研究
6.1 常用公开数据集(按名称、描述、应用场景整理)
教育研究中存在大量私有数据,这对复现与横向比较不友好。因此公开数据集成为方法验证的共同基座。下表给出一组常用公开数据集的名称、简述、典型应用场景与被使用情况
| 数据集 | 简述 | 典型应用场景 |
|---|---|---|
| ASSISTments | 基于知识分解理论的知识追踪数据集,包含大量做题记录 | 智能教育系统评估、知识追踪、个性化推荐等 |
| Junyi Academy Online Learning Activity Dataset | 覆盖中小学在线学习行为数据,含学习与答题记录、行为特征等 | 支撑数据挖掘任务,如知识追踪 |
| KDD Cup 2010 | 计算机辅导系统交互日志(problem、step、knowledge component 等) | 个性化推荐、知识追踪、智能系统评估 |
| MOOCCube | 大规模在线教育数据仓库,含课程、视频、概念与用户行为记录 | 学习行为模式研究、个性化推荐 |
| xAPI-Educational Mining Dataset | 480 名学生、16 项特征(人口统计、背景、行为指标等) | 学习分析、推荐、表现预测、行为检测 |
| Open University Learning Analytics Dataset(OULAD) | 含 30 万+ 学生人口统计、课程信息、交互与成绩数据 | 成功/辍学预测、行为模式分析、推荐与预测系统 |
| Canvas Network Dataset | Canvas 平台在线课程数据(元数据、选课、交互日志等) | 表现预测、推荐、行为检测与理解 |
| Learn Moodle | Moodle 课程中的活动日志、讨论、测验等集合 | 行为模式、学习效果、课程设计与平台功能研究 |
| XuetangX | 覆盖用户注册、访问、视频观看、作业提交、讨论参与等 | 行为分析、知识追踪、个性化推荐 |
| EdNet | 来自真实 AI 辅导平台的大规模交互数据,多变量且细粒度 | 推荐、知识追踪、教育优化 |
这些数据集的共同点是“交互记录丰富”,但差异也十分显著:ASSISTments/KDD 类更偏做题与知识组件序列,适合知识追踪;MOOC 类(MOOCCube、XuetangX、Canvas、Moodle)更偏课程/视频行为,适合推荐、辍学预测与行为检测;OULAD 更偏高等教育课程级别的成功/辍学预测。选择数据集不仅影响指标,还会影响模型结构:例如做题序列往往更短但概念结构更强;课程行为序列更长但噪声与冷启动更重;因此“同一模型在不同数据集上好不好”往往不只是超参问题,而是数据生成机制不同导致的归纳偏置匹配问题。
6.2 数据处理与分析工具(用于日志整理、可视化与分析)
在 EDM 管线里,训练模型之前的日志清洗、行为聚合、可视化与探索性分析同样重要。下表整理了一组常用工具与其作用描述。
| 工具 | 作用描述(译写) |
|---|---|
| GISMO | 面向 Moodle 的图形化交互式学习监控工具,可视化展示学习活动、参与度、成绩与进度等 |
| Meerkat-ED | 教育数据分析工具,可对讨论论坛参与度做深入分析,生成互动摘要,识别讨论核心与边缘参与者等 |
| DataShop | 教育挖掘数据集与工具集合,提供学习环境中的交互数据、轨迹、评测结果等,并提供处理分析工具与 API |
| SNAPP | 讨论区互动网络可视化工具,把发帖/回复构成的互动网络呈现出来,帮助教师快速识别行为模式 |
| LOCO-Analyst | 支持教师评估与改进在线学习环境的分析工具,覆盖学习过程各环节,辅助课程内容与结构优化 |
| StREAM | 学生投入度分析平台,为教师可视化学生投入度、识别需要帮助的学生;为学生提供学习进度与状态反馈 |
把这些工具放在同一张表里,意义不是“工具大全”,而是提醒:EDM 的成功高度依赖数据管线质量。一个看似强大的模型,若输入日志因为缺失、对齐错误、时间戳漂移或行为定义不一致导致噪声巨大,最终往往会变成“拟合数据采集偏差”的算法。尤其当任务是干预与预警时,数据处理环节的每一次规范化都直接影响模型结论是否可信。
7 建模与方法选择的关键理论要点:如何让模型既有效又不跑偏
7.1 评价指标的语义:AUC/ACC/F1 与 HR/NDCG/MRR 的差别不是“数学细节”
在做题对错预测或辍学预测中,AUC/ACC/F1 关注分类质量;在推荐中,HR/NDCG/MRR/MAP 关注排序质量与位置敏感性。指标背后隐含了“错误代价”的假设:例如 ACC 对类别不平衡很敏感,F1 强调精确率与召回率的折中;AUC 强调排序分离度;NDCG 强调高位排序更重要。教育场景里,如果把预警当作分类任务,漏报与误报的代价并不对称;如果把学习路径当作推荐任务,高位推荐错误可能导致学习挫败,其代价也远高于低位错误。因此指标选择应与干预策略一致,否则会出现“指标提升但实际体验变差”的悖论。
7.2 序列模型与注意力:何时用 LSTM,何时用 Transformer,不应只看流行度
LSTM/GRU 的优势在于对中短序列稳定、对噪声相对鲁棒、参数规模可控,适合资源受限且需要表达遗忘机制的场景;Transformer 的优势在于并行训练、长程依赖与多头注意力表达丰富关系,适合长序列且需要捕捉跨阶段关联的场景。教育数据的一个现实问题是“序列长但有效信号稀疏”:例如长时间观看日志中有效学习片段可能只占少数,这时注意力机制的“聚焦能力”才真正发挥作用;但如果数据本身噪声极高,过强的表达能力反而更容易过拟合,因此需要正则化、掩码策略与更谨慎的验证切分。
7.3 图结构注入:KG/GNN 不是装饰品,而是解决“多技能与稀疏”的结构性工具
知识追踪中的多技能题目、推荐中的稀疏交互、学习资源之间的语义关联,都可以用 KG 表达并由 GNN 做传播。其理论价值在于:它把“相邻即相关”的结构先验写进模型,使得即便某个用户交互稀疏,也能通过结构邻居获得信息;即便某个知识点样本少,也能通过先修/共现关系获得信号。但这也带来风险:图结构如果来自专家标注,可能存在主观偏差;如果来自共现统计,可能把“同时出现”误当“因果先修”。因此图结构构建本身需要被当作建模的一部分,而不是默认正确的输入。
7.4 强化学习与可解释性:奖励、状态与动作空间的设计决定上限
强化学习在教育推荐中常被寄予厚望,但其难点集中在三件事:状态如何表达学习者真实状态、动作空间如何覆盖资源选择、奖励如何反映长期学习收益。若状态仅是最近行为窗口,很可能忽略掌握度与先修结构;若动作空间太大,会导致探索困难;若奖励只看短期反馈,会退化成普通推荐。把 KG 路径推理引入 RL,可以在一定程度上缓解可解释性问题:策略不仅给出“推荐什么”,还能给出“通过哪些语义路径推到该推荐”。这类解释在教育里更有意义,因为教师与学习者需要理解推荐理由才能信任系统。
8 结语
深度学习进入 EDM 之后,真正改变的不是“能不能预测”,而是“能不能把学习过程用更贴近真实结构的方式表示出来”。从知识追踪的序列隐状态,到行为检测的多源融合表征,到表现预测的过程特征整合,再到推荐系统的闭环与强化学习优化,这条路线逐渐形成一套可复用的方法体系:嵌入层解决离散符号,序列模型解决时间依赖,注意力解决证据聚合,GNN/KG 解决结构关联,生成模型解决标签稀缺,RL 解决序列决策与长期收益。与此同时,教育场景也不断提醒我们:模型结构的选择必须尊重数据生成机制与教育语义,指标必须对齐真实目标,解释与稳健性必须被当作核心约束,否则“高分模型”可能只是把噪声与偏差拟合得更漂亮。


















 787
787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











