




前言
学习机器学习的过程中,我逐渐意识到:
如果只有代码,而没有理论,就很难真正理解模型在做什么
如果只有概念,而缺少一个系统框架,又难以把知识串成体系
《统计学习方法》正好提供了这样一个结构清晰的入口——它把机器学习的核心思想和经典算法用统计学的语言表达出来,帮助我们理解算法背后的原理。

因此,我决定开启这个专栏,用自己的方式整理学习笔记。主要目标是:
- 用更直白的语言梳理书中的概念
- 把知识点整理成便于查阅和复习的形式
- 记录自己的理解和思考过程
这些笔记主要是我个人的学习记录,如果恰好对你也有帮助,那就更好了。希望通过这个过程,能让自己对机器学习的理论基础有更扎实的理解。
第6章——逻辑斯谛回归与最大熵模型
本章首先介绍逻辑斯谛回归模型,然后介绍最大熵模型,最后讲述逻辑斯谛回归与最大熵模型的学习算法,包括改进的迭代尺度算法、拟牛顿法和梯度下降法。
6.1 逻辑斯谛回归模型
6.1.1 逻辑斯谛分布
要理解逻辑斯谛回归,首先需要了解逻辑斯谛分布这个数学基础。逻辑斯谛分布描述了一种连续型随机变量的概率分布,它最显著的特点是其分布函数呈现出一条光滑的S形曲线(sigmoid curve)。
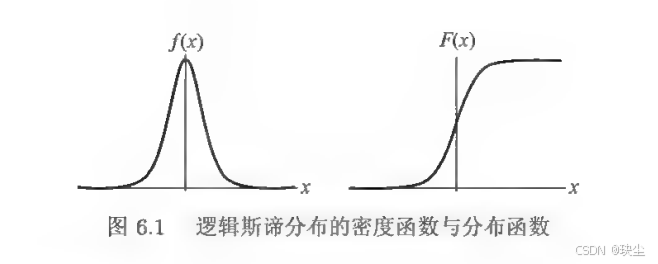
具体来说,设 XXX 是连续随机变量,如果 XXX 服从逻辑斯谛分布,那么它的分布函数为
F(x)=P(X≤x)=11+e−(x−μ)/γF(x) = P(X \leq x) = \frac{1}{1 + e^{-(x-\mu)/\gamma}}F(x)=P(X≤x)=1+e−(x−μ)/γ1
密度函数为
f(x)=F′(x)=e−(x−μ)/γγ(1+e−(x−μ)/γ)2f(x) = F'(x) = \frac{e^{-(x-\mu)/\gamma}}{\gamma(1 + e^{-(x-\mu)/\gamma})^2}f(x)=F′(x)=γ(1+e−(x−μ)/γ)2e−(x−μ)/γ
这里 μμμ 是位置参数,决定了曲线的中心位置;γγγ 是形状参数,控制着曲线的陡峭程度——γγγ 越小,曲线在中心附近上升得越快。
这条S形曲线的值域在0到1之间,恰好可以用来表示概率,这就为我们后续构建分类模型提供了理论基础。
6.1.2 二项逻辑斯谛回归模型
有了逻辑斯谛分布这个工具,我们就可以构建一个实用的分类模型了。二项逻辑斯谛回归就是用来解决二分类问题的——给定一个输入 xxx,我们要判断它属于类别0还是类别1。
模型定义:二项逻辑斯谛回归是一种分类模型,由条件概率分布 P(Y|X) 表示。
对于输入 x∈Rnx ∈ Rⁿx∈Rn,输出 Y∈0,1Y ∈ {0, 1}Y∈0,1,条件概率为:
P(Y=1∣x)=exp(w⋅x+b)1+exp(w⋅x+b)P(Y = 1|x) = \frac{\exp(w \cdot x + b)}{1 + \exp(w \cdot x + b)}P(Y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)
P(Y=0∣x)=11+exp(w⋅x+b)P(Y = 0|x) = \frac{1}{1 + \exp(w \cdot x + b)}P(Y=0∣x)=1+exp(w⋅x+b)1
这个公式有个重要的性质:取 对数几率(odds) 后:logP(Y=1∣x)1−P(Y=1∣x)=w⋅x\log \frac{P(Y = 1|x)}{1 - P(Y = 1|x)} = w \cdot xlog1−P(Y=1∣x)P(Y=1∣x)=w⋅x变成了线性关系。这就是说,在逻辑斯谛回归模型中,输出 Y = 1 的对数几率是输入 x 的线性函数,模型通过线性函数 w·x 对输入进行分类。
6.1.3 模型参数估计
模型的形式确定后,下一步自然是:如何从训练数据中学习参数w?这就需要用到参数估计方法。
给定训练数据集 T={(x1,y1),(x2,y2),...,(xn,yn)}T = \{(x₁, y₁), (x₂, y₂), ..., (xₙ, yₙ)\}T={(x1,y1),(x2,y2),...,(xn,yn)},我们的目标是找到最优的参数w,使得模型在这些数据上的表现最好。在统计学中,"最好"的标准通常是极大似然估计——找到让观测数据出现概率最大的参数。
对于逻辑斯谛回归,对数似然函数可以写成 L(w)=∑i=1N[yi(w⋅xi)−log(1+exp(w⋅xi))]L(w) = \sum_{i=1}^{N} [y_i(w \cdot x_i) - \log(1 + \exp(w \cdot x_i))]L(w)=i=1∑N[yi(w⋅xi)−log(1+exp(w⋅xi))]
这个函数的物理意义是:如果参数 www 越好,那么对于标签为1的样本,w⋅xiw \cdot x_iw⋅xi 应该越大(预测概率高);对于标签为0的样本,w⋅xiw \cdot x_iw⋅xi 应该越小(预测概率低)。
通过对 L(w)L(w)L(w) 求极大值(通常用梯度下降法或拟牛顿法),我们就能得到参数的估计值 w^ŵw^,进而得到训练好的模型 P(Y=1∣x)=exp(w^⋅x)1+exp(w^⋅x)P(Y = 1|x) = \frac{\exp(\hat{w} \cdot x)}{1 + \exp(\hat{w} \cdot x)}P(Y=1∣x)=1+exp(w^⋅x)exp(w^⋅x)这个过程本质上是一个优化问题,将机器学习的目标函数转化为可计算的数值问题。
6.1.4 多项逻辑斯谛回归
掌握了二分类的逻辑斯谛回归后,自然会想:如果有多个类别怎么办?多项逻辑斯谛回归就是对二项模型的推广。
假设我们有K个类别(K > 2),那么需要为前K-1个类别各自设定一个参数向量 wkwₖwk,并将第K类作为参照基准。
模型的形式变为:
P(Y=k∣x)=exp(wk⋅x)1+∑k=1K−1exp(wk⋅x)(k=1,2,...,K−1)P(Y = k|x) = \frac{\exp(w_k \cdot x)}{1 + \sum_{k=1}^{K-1} \exp(w_k \cdot x)}(k = 1, 2, ..., K-1)P(Y=k∣x)=1+∑k=1K−1exp(wk⋅x)exp(wk⋅x)(k=1,2,...,K−1)
而参照类的概率为
P(Y=K∣x)=11+∑k=1K−1exp(wk⋅x)P(Y = K|x) = \frac{1}{1 + \sum_{k=1}^{K-1} \exp(w_k \cdot x)}P(Y=K∣x)=1+∑k=1K−1exp(wk⋅x)1
这种设计保证了所有类别的概率之和为1。相比二分类只需要一个参数向量,多分类需要K-1个参数向量,每个向量独立地刻画了对应类别相对于参照类的偏好程度。参数估计的方法与二项情况类似,仍然使用极大似然估计。
6.2 最大熵模型
6.2.1 最大熵原理
熵(Entropy) 这个概念最早来源于热力学,后来被香农引入到信息论中,用来表示"随机变量的不确定性"。熵的数学定义是 H=−∑p(x)logp(x)H = -∑p(x)log p(x)H=−∑p(x)logp(x) ,其物理意义是:熵越大,不确定性就越强,包含的可能性就越多。
最重要的结论是:最大熵模型指的就是包含最多信息的条件概率分布。从公式可以看出,如果随机变量 xxx 是离散的,那么求和符号 ∑∑∑ 就变成了积分符号 ∫∫∫。
那么如何找到最大熵对应的条件概率分布呢?答案很简单:取最大值所对应的概率。
argmaxpiH=argmaxpi[−∑i=1kpilogpi] \arg\max_{p_i} H = \arg\max_{p_i} \left[ - \sum_{i=1}^{k} p_i \log p_i \right] argpimaxH=argpimax[−i=1∑kpilogpi]
但这里有一个限制条件,就是所有概率之和必须等于1,即 ∑i=1kpi=1\sum_{i=1}^{k} p_i = 1∑i=1kpi=1。
为了在满足约束条件的情况下求熵的最大值,可以使用拉格朗日乘子法。我们构造新的目标函数 Q(p1,p2,⋯ ,pk)=−∑i=1kpilogpi+λ(∑i=1kpi−1)Q(p_1, p_2, \cdots, p_k)=- \sum_{i=1}^{k} p_i \log p_i+ \lambda \left( \sum_{i=1}^{k} p_i - 1 \right)Q(p1,p2,⋯,pk)=−∑i=1kpilogpi+λ(∑i=1kpi−1),然后对每个概率pi求偏导,令偏导数等于0,就能找到最大值。
通过求解可以最终得到 pi=1kp_i = \frac{1}{k}pi=k1,代入求得最大熵为 maxH=logkmaxH = logkmaxH=logk。
离散情况:均匀分布的最大熵
让我们看一个具体例子。假设随机变量 XXX 有5个取值{A,B,C,D,E},根据最大熵原理估计每个取值的概率。
-
在常规约束下:根据最大熵原理,在等概率的时候(k = 5)取得熵的最大值,所以 pi=15p_i = \frac{1}{5}pi=51。此时 maxH=logk\max H = \log kmaxH=logk,这与古典概率中的等概率思维是一致的——等概率下包含的信息量是最多的。
-
增加1个约束条件:如果已知 p1+p2=310p_1 + p_2 = \frac{3}{10}p1+p2=103,那么概率就分成了两部分。剩余的 p3+p4+p5=710p_3 + p_4 + p_5 = \frac{7}{10}p3+p4+p5=107。在这种情况下,要使熵最大,每部分里面都应该是等概率的,即 p1=p2=320p_1 = p_2 = \frac{3}{20}p1=p2=203,p3=p4=p5=730p_3 = p_4 = p_5 = \frac{7}{30}p3=p4=p5=307。
-
再增加2个约束条件:如果同时有 p1+p2=310p_1 + p_2 = \frac{3}{10}p1+p2=103 和 p1+p3=12p_1 + p_3 = \frac{1}{2}p1+p3=21 两个约束,我们可以把所有的 pip_ipi 都用 p1p_1p1 表达出来。通过求解 H(p1)H(p_1)H(p1) 的最大值,可以找到对应的概率分布。
连续情况:正态分布的最大熵
对于连续分布,计算熵时使用自然对数(以 eee 为底),单位是纳特(nat)。一个重要的问题是:为什么正态分布是日常中最常用的分布假设?
答案在于最大熵原理。假设我们已知一个连续随机变量在整个实数轴上取值,其均值为 μ\muμ,方差为 σ2\sigma^2σ2,那么熵最大对应的概率分布是什么呢?
我们需要在三个约束条件下求解:
- 常规约束: ∫−∞+∞p(x)dx=1\int_{-\infty}^{+\infty} p(x)dx = 1∫−∞+∞p(x)dx=1 (概率密度积分为1)
- 均值约束: ∫−∞+∞xp(x)dx=μ\int_{-\infty}^{+\infty} xp(x)dx = \mu∫−∞+∞xp(x)dx=μ (期望值固定)
- 方差约束: ∫−∞+∞(x−μ)2p(x)dx=σ2\int_{-\infty}^{+\infty} (x-\mu)^2p(x)dx = \sigma^2∫−∞+∞(x−μ)2p(x)dx=σ2 (方差固定)
同样使用拉格朗日乘子法,构造目标函数 LLL,然后对 p(x)p(x)p(x) 求偏导并令其等于0。经过推导可以得到 p(x)p(x)p(x) 的指数形式。利用常用的指数积分结果 ∫e−x22dx=2π\int e^{-\frac{x^2}{2}}dx = \sqrt{2\pi}∫e−2x2dx=2π,我们可以求出归一化常数。
最终整理出来的 p(x)p(x)p(x) 就是:
p(x)=12πσ2e−(x−μ)22σ2p(x) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}p(x)=2πσ21e−2σ2(x−μ)2
这正是正态分布的表达式!这也解释了为什么正态分布是最常用的分布假设——因为在给定均值和方差的约束下,正态分布包含的信息量是最多的,它是最大熵分布。
6.2.2 最大熵模型的定义
先来一起看看最大熵模型的定义:
假设满足所有约束条件的模型集合为
C≡{P∈P∣EP(fi)=EP~(fi),i=1,2,⋯ ,n}(6.12)\mathcal{C} \equiv \{P \in \mathcal{P} | E_P(f_i) = E_{\tilde{P}}(f_i), \quad i = 1, 2, \cdots, n\} \tag{6.12}C≡{P∈P∣EP(fi)=EP~(fi),i=1,2,⋯,n}(6.12)
定义在条件概率分布 P(Y∣X)P(Y|X)P(Y∣X) 上的条件熵为
H(P)=−∑x,yP~(x)P(y∣x)logP(y∣x)(6.13)H(P) = -\sum_{x,y} \tilde{P}(x)P(y|x) \log P(y|x) \tag{6.13}H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)(6.13)
则模型集合 C\mathcal{C}C 中条件熵 H(P)H(P)H(P) 最大的模型称为最大熵模型。式中的对数为自然对数。
最大熵原理背后的想法其实很简单:
在所有“能解释训练数据”的模型里,选择那个最“均匀”、最“不偏不倚”的模型。
也就是说:该知道的必须知道,不该猜的坚决不乱猜。
我们要学习什么?
我们要学习一个分类模型,即条件概率分布:P(Y∣X)P(Y|X)P(Y∣X)
意思是:给定输入 XXX,模型给出每个可能的输出 YYY 的概率。
训练数据是:
T={(x1,y1),⋯ ,(xN,yN)} T=\{(x_1,y_1), \cdots, (x_N,y_N)\} T={(x1,y1),⋯,(xN,yN)}
目标:在这些数据的基础上,挑选一个最合适的概率模型。
我们有哪些“可靠信息”?
训练数据能告诉我们哪些事是“客观发生”的。
例如我们能数出:
- 某个输入 xxx 出现多少次
- 某个输入-输出组合 (x,y)(x,y)(x,y) 出现多少次
于是可以定义“经验分布”(就是样本频率):
P~(x,y)=ν(x,y)N,P~(x)=ν(x)N \tilde{P}(x,y)=\frac{\nu(x,y)}{N},\qquad \tilde{P}(x)=\frac{\nu(x)}{N} P~(x,y)=Nν(x,y),P~(x)=Nν(x)
这些经验分布是我们必须保留的信息。
用“特征函数”提取我们关心的事实
一个特征函数就是一个简单的判断式,比如:
“如果 x 的颜色是红色且 y=苹果,则 f(x,y)=1,否则为 0。”
形式是:
f(x,y)={1,x与y满足某一事实0,否则f(x, y) = \begin{cases} 1, & x与y满足某一事实 \\ 0, & 否则 \end{cases}f(x,y)={1,0,x与y满足某一事实否则
两个期望:数据的期望 vs 模型的期望
为了让模型“尊重”训练数据,我们要求:
- 数据告诉我们的平均事实(经验期望)
EP~(f)=∑x,yP~(x,y)f(x,y) E_{\tilde{P}}(f)=\sum_{x,y}\tilde{P}(x,y)f(x,y) EP~(f)=x,y∑P~(x,y)f(x,y)
- 模型预测的平均事实(模型期望)
EP(f)=∑x,yP~(x)P(y∣x)f(x,y) E_{P}(f)=\sum_{x,y}\tilde{P}(x)P(y|x)f(x,y) EP(f)=x,y∑P~(x)P(y∣x)f(x,y)
最大熵模型的核心要求:两者必须相等
EP(f)=EP~(f) E_{P}(f)=E_{\tilde{P}}(f) EP(f)=EP~(f)
意思是:
模型不但要看起来“合理”,还要在统计上重现训练数据里的特征事实。
如果有 nnn 个特征函数,那么就有 nnn 个这样的约束。
信息约束之上,“猜得最少”——最大熵原则的真正出场
现在,我们面对的是一个经典矛盾:
- 既要满足所有特征约束(不能违背训练数据)
- 又不能无缘无故偏向某种 P(y∣x)P(y|x)P(y∣x)(不能乱猜)
最大熵原则告诉我们:
在满足所有约束的前提下,选择熵最大的分布。
6.2.3 最大熵模型的学习
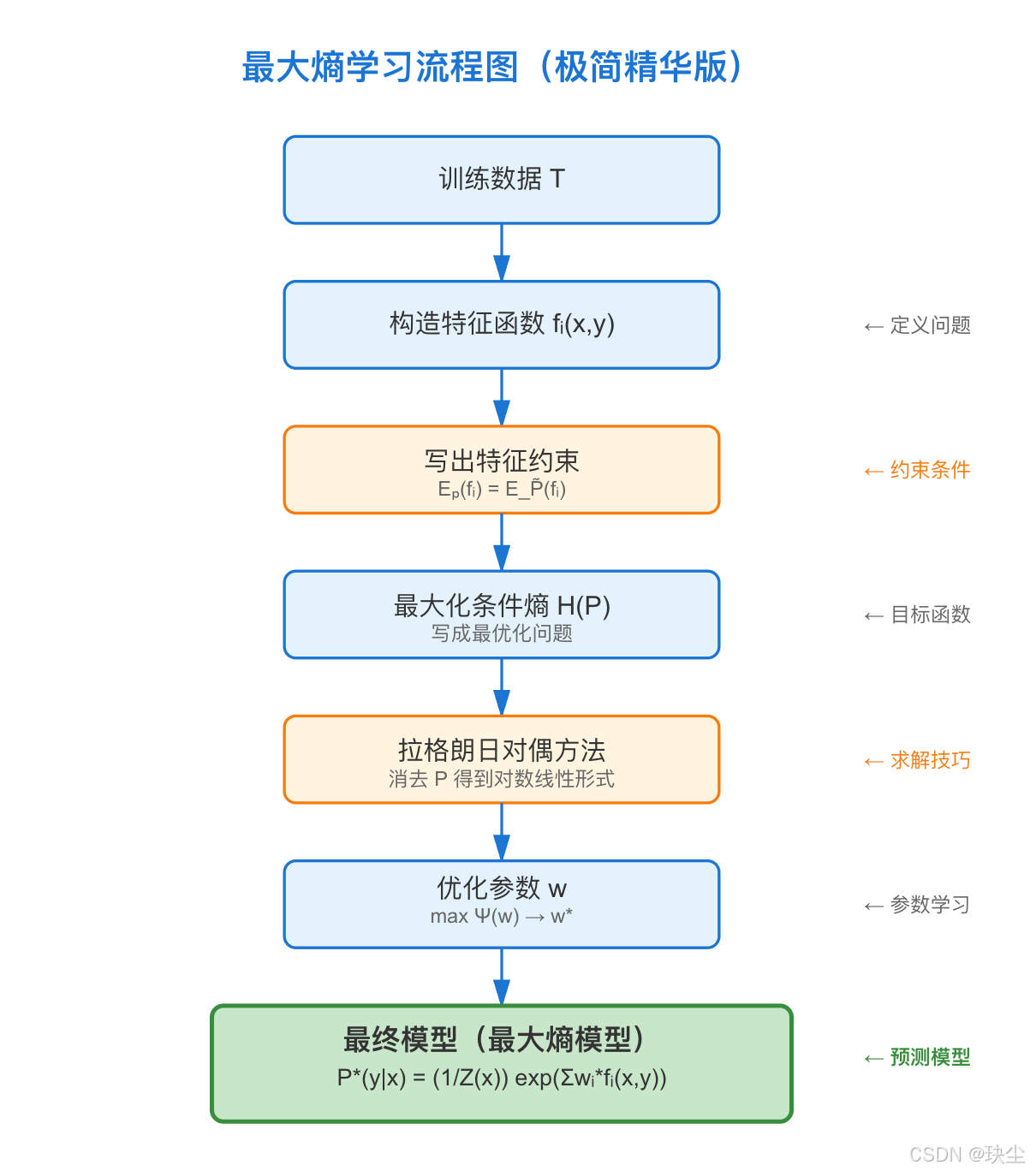
最大熵模型的学习,本质上就是:
在满足所有特征约束的条件下,找到熵最大的分布。
为了做到这一点,我们把问题写成一个带约束的最优化问题,然后再用拉格朗日对偶的方法把它转成无约束问题来求解。
把最大熵问题写成一个优化问题
我们希望模型的熵最大:
H(P)=−∑x,yP~(x)P(y∣x)logP(y∣x) H(P)= -\sum_{x,y}\tilde{P}(x)P(y|x)\log P(y|x) H(P)=−x,y∑P~(x)P(y∣x)logP(y∣x)
这是“最不偏不倚”的表现。
同时模型必须满足两个硬约束:
- 特征约束(重现数据特征)
EP(fi)=EP~(fi) E_P(f_i)=E_{\tilde P}(f_i) EP(fi)=EP~(fi)
- 概率约束(每个 x 下概率要和为 1)
∑yP(y∣x)=1 \sum_yP(y|x)=1 y∑P(y∣x)=1
这样,一个清晰的、标准的“最大化问题”就形成了。
为了符合最优化的书写习惯,我们把最大化熵换成最小化负熵:
min−H(P) \min -H(P) min−H(P)
至此,最大熵模型的学习就是一个典型的带等式约束的最优化问题。
约束太多,没办法直接求解,于是使用拉格朗日对偶方法:
把约束吸收到 Lagrange 函数里,让问题变成无约束的。
为每个约束加上一个拉格朗日乘子:
- w1,…,wnw_1,\dots,w_nw1,…,wn:对应每个特征约束
- w0w_0w0:对应概率归一化约束
构造拉格朗日函数:
L(P,w)=−H(P)+w0(1−∑yP(y∣x))+∑i=1nwi(EP~(fi)−EP(fi)) L(P,w)= -H(P)+ w_0\left(1-\sum_y P(y|x)\right) + \sum_{i=1}^n w_i \big(E_{\tilde P}(f_i)-E_P(f_i)\big)L(P,w)=−H(P)+w0(1−y∑P(y∣x))+i=1∑nwi(EP~(fi)−EP(fi))
此时,约束已经隐藏在拉格朗日函数中,问题变为:
对 PPP 做极小化,对 www 做极大化。
这就是典型的对偶结构。
现在关键一步:
把 LLL 对 P(y∣x)P(y|x)P(y∣x) 求偏导,令其为零。
这个步骤背后在做的事情是:
“在给定约束权重的情况下,最优的概率分布是什么样子?”
最终会得到一个非常漂亮的结果:
Pw(y∣x)=1Zw(x)exp(∑i=1nwifi(x,y)) P_w(y|x) = \frac{1}{Z_w(x)} \exp\left(\sum_{i=1}^n w_i f_i(x,y)\right) Pw(y∣x)=Zw(x)1exp(i=1∑nwifi(x,y))
其中:
Zw(x)=∑yexp(∑i=1nwifi(x,y)) Z_w(x)=\sum_y \exp\left(\sum_{i=1}^n w_i f_i(x,y)\right) Zw(x)=y∑exp(i=1∑nwifi(x,y))
这个形式非常重要,它说明:
最大熵模型就是一个对数线性模型(Log-linear Model)。
参数 wiw_iwi 控制每个特征的权重,Zw(x)Z_w(x)Zw(x) 保证概率归一化。
这一点也是为什么最大熵模型和逻辑回归、条件随机场本质上是一类模型。
学习的真正目标:求 w
到这里,我们已经知道:
最大熵模型的结构是对数线性的,关键就是参数 www。
那么学习的最终目标就变成:
maxwΨ(w) \max_w \Psi(w) wmaxΨ(w)
其中 Ψ(w)\Psi(w)Ψ(w) 是对偶函数,它来自:
- 把最优的 PwP_wPw 代回拉格朗日函数
- 消去 PPP,只剩下 www 的函数
最终优化得到参数:
w∗=argmaxwΨ(w) w^*=\arg\max_w \Psi(w) w∗=argwmaxΨ(w)
再把 w∗w^*w∗ 带回:
P∗(y∣x)=Pw∗(y∣x) P^*(y|x)=P_{w^*}(y|x) P∗(y∣x)=Pw∗(y∣x)
得到最终的最大熵模型。也就是说,最大熵模型的学习归结为对偶函数 Ψ(w)\Psi(w)Ψ(w) 的极大化。
6.2.4 极大似然估计
在上一节中,我们得到最大熵模型的最终形式:
Pw(y∣x)=1Zw(x)exp(∑iwifi(x,y)) P_w(y|x)=\frac{1}{Z_w(x)}\exp\left(\sum_i w_i f_i(x,y)\right) Pw(y∣x)=Zw(x)1exp(i∑wifi(x,y))
以及一个看似复杂的结论:
最大熵模型的参数要通过最大化对偶函数 Ψ(w)\Psi(w)Ψ(w) 来求。
给定训练数据的经验分布 P~(x,y)\tilde P(x,y)P~(x,y),模型的对数似然函数是:
LP~(Pw)=∑x,yP~(x,y)logPw(y∣x) L_{\tilde P}(P_w) = \sum_{x,y}\tilde P(x,y)\log P_w(y|x) LP~(Pw)=x,y∑P~(x,y)logPw(y∣x)
把最大熵模型的形式代入对偶函数,可以证明:
Ψ(w)=LP~(Pw) \Psi(w)=L_{\tilde P}(P_w) Ψ(w)=LP~(Pw)
非常重要!
这说明:
最大熵模型的学习最大化 Ψ(w)\Psi(w)Ψ(w) = 极大似然估计最大化 LP~(Pw)L_{\tilde P}(P_w)LP~(Pw)
换句话说:
- 看似“高大上”的最大熵学习
- 实际上就是“最大似然训练一个线性指数模型”
这样,最大熵模型的学习问题就转换为具体求解对数似然函数极大化或对偶函数极大化的问题。
同时最大熵模型的形式和逻辑回归几乎一模一样:
- 逻辑回归用于二分类
- 最大熵模型用于多分类
- 条件随机场(CRF)用于序列标注
它们都属于:对数线性模型(log-linear model)

















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









