 Fast-SmartWay:端到端机器人导航新范式
Fast-SmartWay:端到端机器人导航新范式




导读
让机器人理解一句话并在现实世界中走对路,这件事看似简单,却一直是视觉语言导航(VLN)研究中最棘手的挑战。过去的做法往往要求机器人在原地转一圈,拍下12张全景照片,再由复杂的两阶段模型(waypoint预测 + 路径决策)推理出下一步动作。虽然准确,但代价是——慢、重、且不现实。来自阿德莱德大学与EPFL的研究团队提出了一个更“聪明”的新思路:Fast-SmartWay。它让机器人只靠三个前向视角的RGB-D图像和自然语言指令,就能一步到位地输出导航动作。更厉害的是,它还引入了一套“不确定性推理系统”,能在混乱场景中自动反思、重规划。
结果?导航成功率更高,延迟却几乎减半。这让“零样本导航”真正从实验室走向了现实。
相关阅读:前作https://mp.weixin.qq.com/s/E4zt7KbZdviuOLUfF2fH6Q
论文出处:arXiv2025
论文标题:Fast-SmartWay: Panoramic-Free End-to-End Zero-Shot Vision-and-Language Navigation
论文作者:Xiangyu Shi, Zerui Li, Yanyuan Qiao,Qi Wu
论文链接:https://arxiv.org/pdf/2511.00933

在以往的导航系统里,机器人要先用360°相机生成全景图,再由waypoint预测器挑出几个可能的候选点,最后交给大语言模型(LLM)来判断往哪走。这种两阶段流程不仅慢,而且各模块割裂:预测器只看RGB-D,根本不了解语言语义。
Fast-SmartWay 则直接打破了这种分工。它只看左、中、右三个前视角图像,把这些视觉信号与语言指令一同输入多模态大模型(MLLM),由模型一次性输出两个核心动作参数:转向角度与前进距离。
这意味着机器人不再需要候选点筛选,而是能“直接思考”该往哪走。
为了让模型理解空间结构,作者设计了一个 空间-语义文本描述模块:它将深度图中的障碍信息转成自然语言提示,比如“向左30°方向有障碍物2.5米”,再与识别出的语义物体(如“钟表”“厨房”“楼梯”)一并组成提示输入。
这样,大模型能在语言层面理解环境布局,像人一样“想清楚再走”。
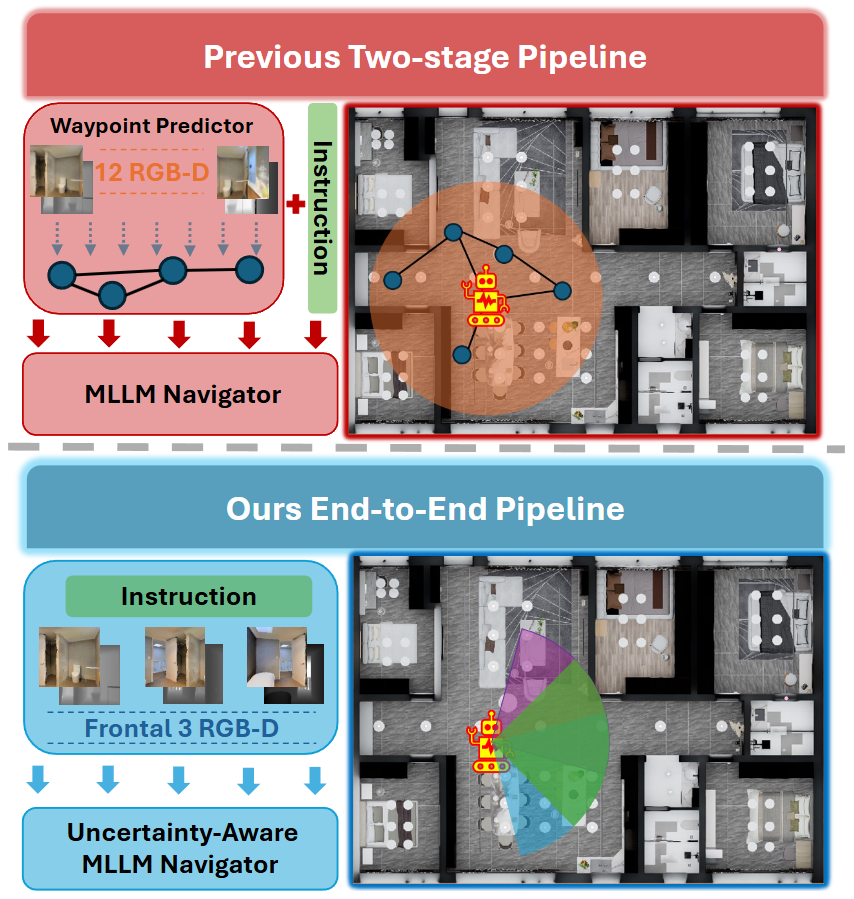
图1|上半部分展示了以往的VLN-CE流程:机器人需要收集12张全景RGB-D图像,通过waypoint预测器挑出可能的路径,再结合指令决定下一步动作。下半部分是Fast-SmartWay的设计:只需三张前向视图,模型就能在一次推理中直接输出导航决策,实现真正的端到端控制

不再依赖全景相机输入的端到端零样本导航
Fast-SmartWay取消了传统的“全景观察 + waypoint预测”两阶段结构,仅依靠三个前向RGB-D图像即可完成导航决策。
模型直接预测“转向角”和“前进距离”,不再生成离散候选点,从而实现视觉与语言的深度融合。
这种设计显著降低了系统延迟:在真实机器人上,平均每步总耗时仅12.39秒,仅为SmartWay的42.4%,并且减少视觉输入并不会削弱模型表现,反而使导航更快、更稳定、更易部署。
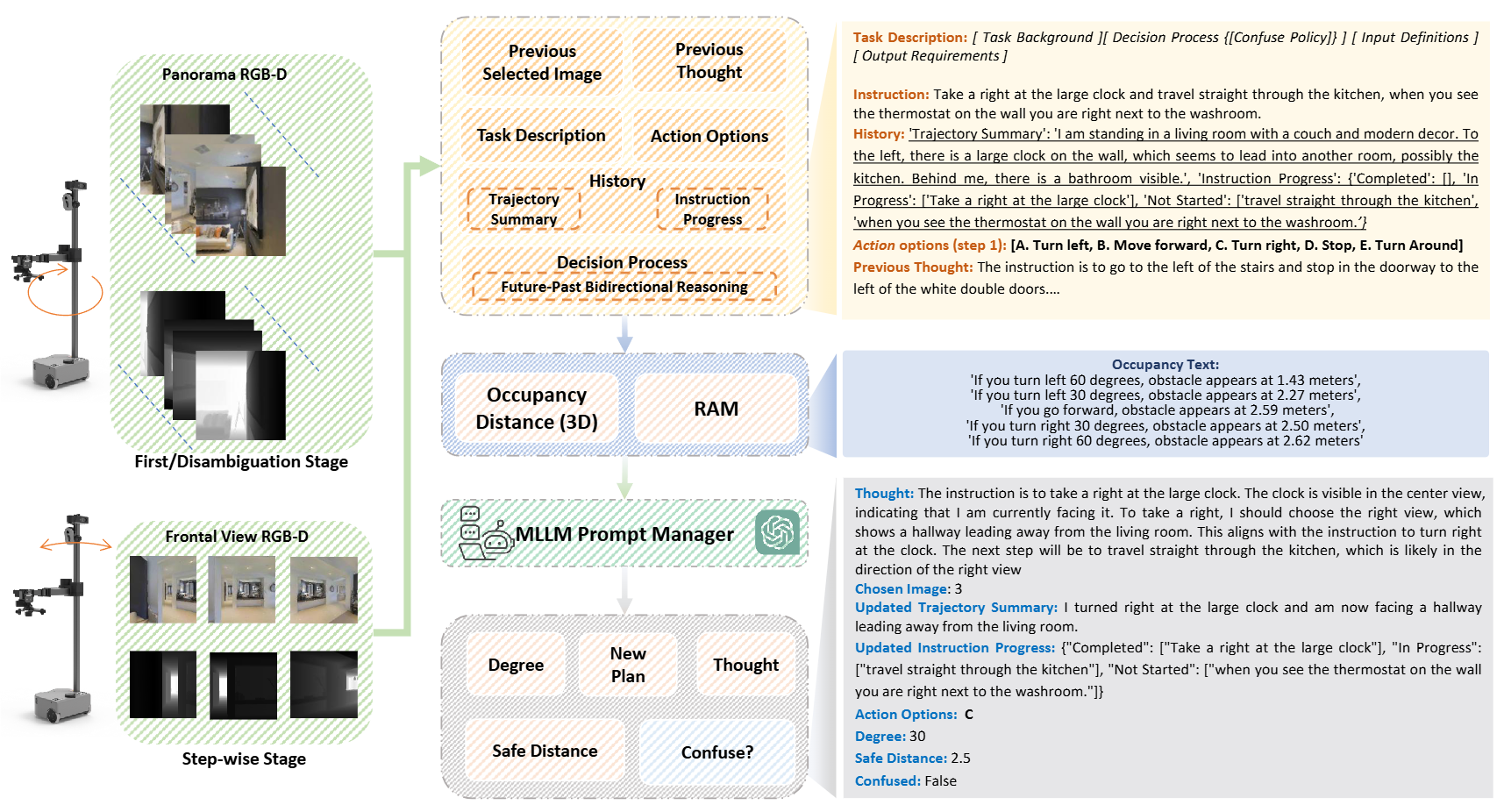
图2|展示了Fast-SmartWay的完整导航过程。在起始阶段,机器人先采集一次全景图建立环境认知;随后的导航仅依赖三张前向视图。系统会先生成结构化提示(prompt),提取空间与语义信息,再交由多模态大模型(MLLM)进行逐步推理。如果模型检测到“困惑”状态,就会触发Disambiguation模块重新扫描并规划路线。图中的平台为Hello Robot,搭载Intel RealSense相机,用于实地测试
不确定性感知推理
导航任务中常见的问题是歧义、局部最优或环境冲突。为此,作者引入了一个两层机制:
● Disambiguation模块负责检测“困惑状态”,当机器人发现指令模糊或目标不清时,会触发一次360°扫描,重新构建场景并更新轨迹摘要;
● Future-Past Bidirectional Reasoning (FPBR) 则让模型同时“预演未来”和“回顾过去”,比较预测与实际观测是否一致,以修正偏差。
这种机制让机器人具备了类似人类的“反思能力”——它能在执行中纠错,从而保持全局一致的路径规划。
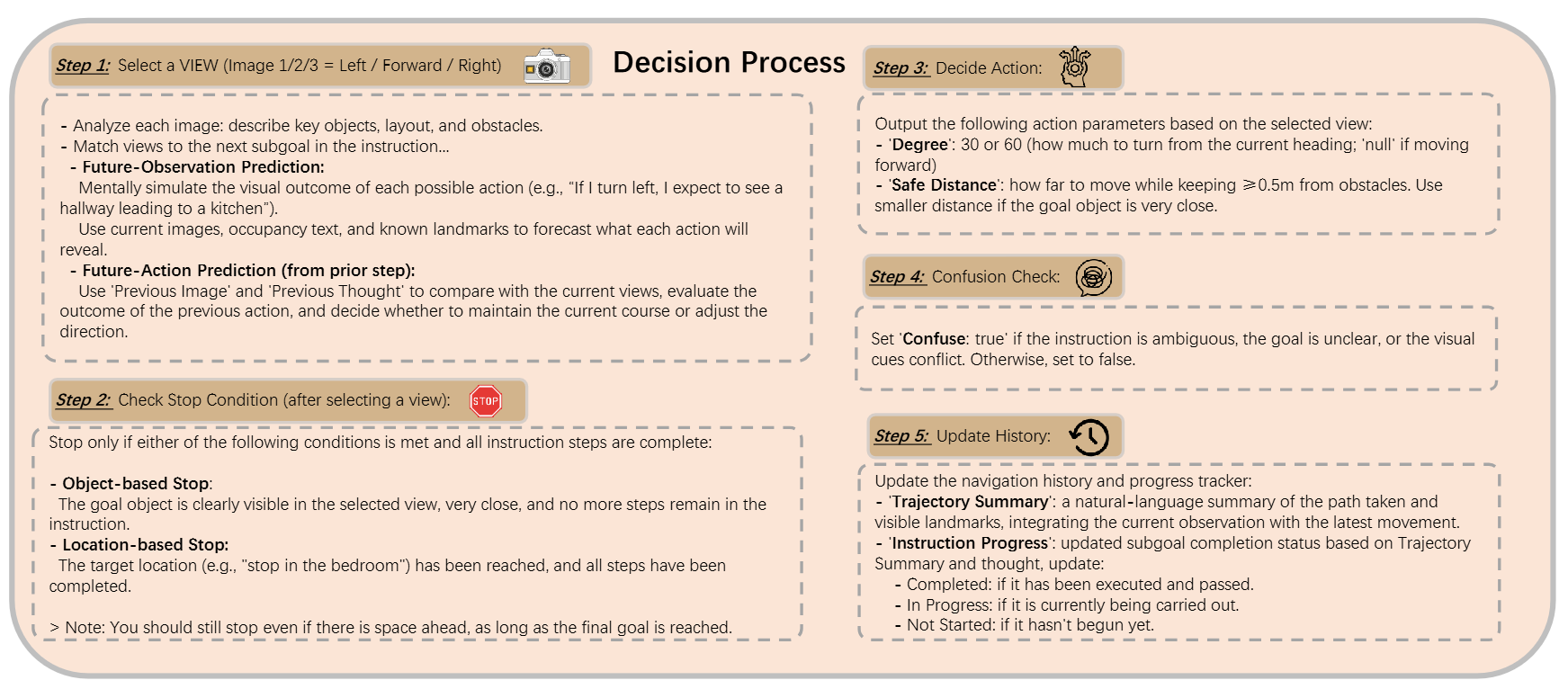
图3|这张图展示了Fast-SmartWay在每一步的决策流程。MLLM会综合当前三视图、历史轨迹和指令内容,依次评估候选方向、预测未来视野、分析上一步的动作结果,并判断是否需要停下或转向。最终输出包括“选定方向”“旋转角度”和“安全前进距离”等关键参数,让机器人实现思考式的逐步导航
空间-语义融合描述
为弥补缺少全景视觉带来的信息损失,Fast-SmartWay创新性地将三张深度图投影成局部点云,再提取出不同角度的最近障碍距离。
这些几何信息会被离散成五个方向区间(左60°到右60°),并转成自然语言描述,如:“若向右30°转,有障碍在2.6米处”。
同时,系统利用RAM模型识别出画面中的显著语义物体(如沙发、冰箱、时钟等),将其以文字形式加入提示,从而让大模型在语言层面理解空间几何与语义关联。
这种把视觉几何转译成语言表达的策略,使得MLLM能够在统一语言空间中进行推理,兼顾空间感知与语义对齐,在实际导航中保持高效且稳定的表现。

Fast-SmartWay 展示出惊人的效率:
在Hello Robot平台上,在减少了大部分观测输入的情况下,感知时间从20多秒提升到5秒左右,机器人平均每步耗时减少 58%,同时成功率提升。

图4|在Hello Robot实机测试中,Fast-SmartWay仅用前向三视图即可完成导航,每步延迟缩短近60%,同时成功率提升至36%,导航误差降至2.78。相比需要12张全景输入的SmartWay,它在速度与效果上实现了双重突破
在模拟环境 R2R-CE 中,它的 成功率 SR=27.75,SPL=24.95,与使用全景输入的前作SmartWay(SR=29,SPL=22.08)不相上下,超过了Open-Nav-GPT4(SR=19, SPL=16.1)。
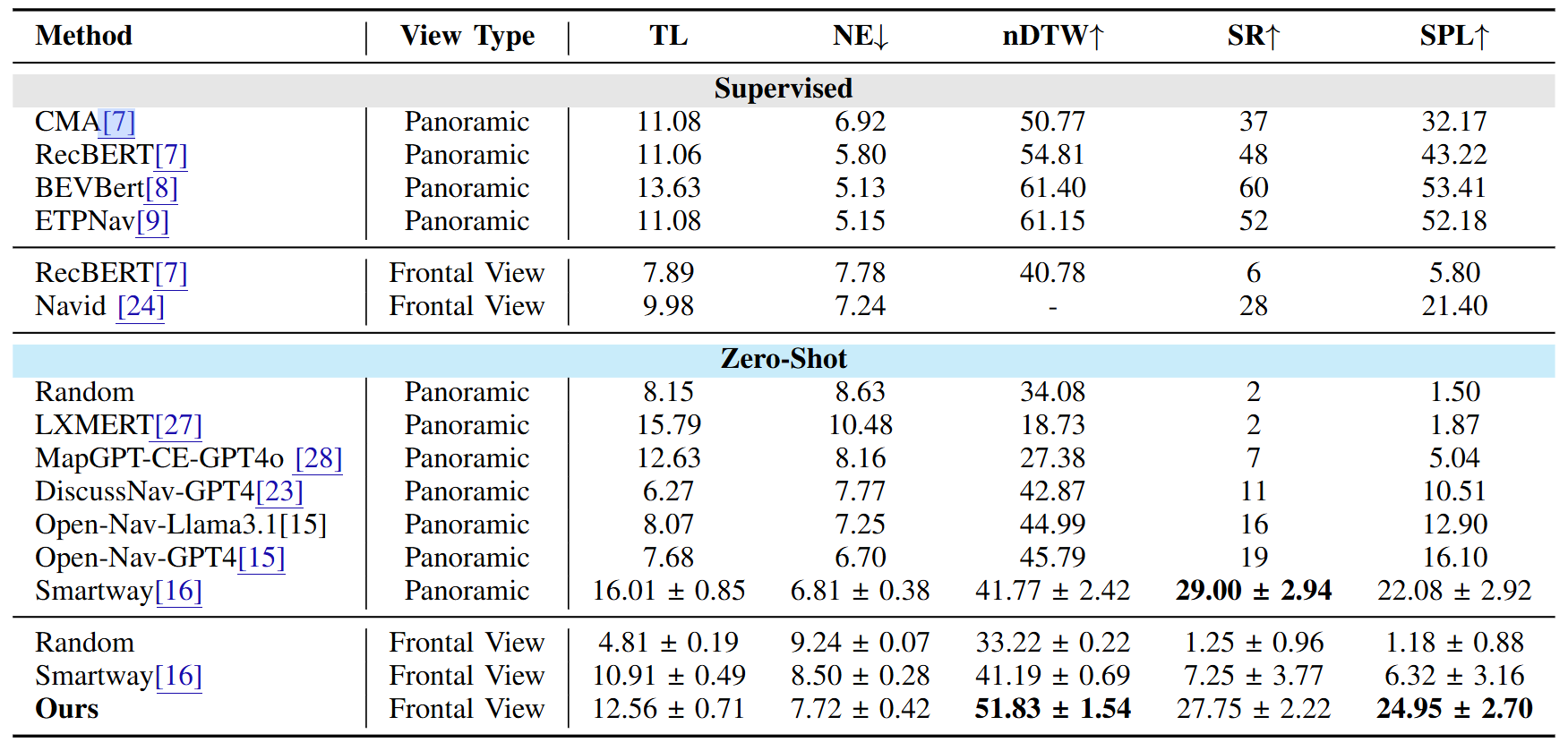
图5|在标准R2R-CE数据集上,Fast-SmartWay依然保持出色表现:它在仅使用前向视角的情况下,成功率(SR)达到27.75,超过Open-Nav-GPT4等方法。结果证明,少视图输入也能实现高效稳定的零样本导航
消融实验进一步验证了不确定性推理的价值:
● 去掉Disambiguation与FPBR → SR仅19.75;
● 加回Disambiguation → SR升至24.25;
● 同时启用两者 → SR提升至27.75。
这说明Fast-SmartWay的“反思系统”不仅让机器人更聪明,也让决策更稳健。

图6|消融实验结果

Fast-SmartWay 展示了一条现实可行的方向:让多模态大模型直接做导航决策,而不是层层转译。它用三张图像取代全景,靠语言化的空间理解完成端到端推理,让零样本导航真正走向“实用级”。
这背后反映的趋势是:
从数据堆叠到推理融合,机器人正逐步学会“带着不确定性思考”。

















 7319
7319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









