



导读
作为机器学习领域最顶级的学术会议之一,NeurIPS 每年都会释放出下一阶段研究与应用的风向。相比只看单点“模型刷新 SOTA”,系统层面的范式变化更值得关注:表示的选择、优化的思路、数据与评价的演进,最终会落到产业与具身智能的落地能力上。
2025年的NeurIPS的论文list刚刚公布,我们一起来尝尝鲜,本次盘点聚焦 3D Rendering & Reconstruction(3D 渲染与重建)的相关工作,原因很简单:
● 它是从感知到行动的桥梁。要让机器人“做事”,就得先把世界对齐、对准、对清楚。
● 它正处在技术范式更替的临界点:从 NeRF 到 3D/4D Gaussian Splatting(3DGS/4DGS),从静态重建到时序/生成,效率与可用性显著提升。
● 它正在与语义、物理、生成深度融合,服务真实场景(AR/VR、机器人、数字资产管线)。
今年该方向投稿很多,我们筛选出 9 篇工作,按三类组织:
1. 动态场景与时序重建(让世界“动”起来)
2. Gaussian Splatting 的结构革新(把“高斯世界”打磨成工程可用)
3. 生成式与可编辑 3D(从“还原世界”到“创造世界”)

这类研究是什么?
不仅重建静态几何与外观,还要表达、压缩和实时渲染时间维度的变化(4D)。
为什么重要?
机器人、AR/VR、影视与体育自由视角视频(FVV)都需要在线、稳定、可扩展的动态重建与渲染能力。
ReCon-GS: Continuum-Preserved Guassian Streaming for Fast and Compact Reconstruction of Dynamic Scenes【连续体高斯流的在线重建与实时渲染】
链接:https://arxiv.org/pdf/2509.24325
痛点:在线 FVV 常见三难:逐帧优化慢、运动估计不稳、模型/缓存暴涨。
核心做法:
● 密度自适应的多级 Anchor Gaussians 表达几何形变,粗到细分解运动;
● 层级可重配置:按需“重排”层次,局部保持表达力,层内变形继承保时间一致;
● 存储感知优化:不同层密度可调,质量↔内存可控权衡。
效果(文中报告):训练效率约 +15%;在同等画质下内存减半;FVV 合成更稳、更鲁棒。
看点:把“快、稳、省”放进同一框架,工程可用性跃升
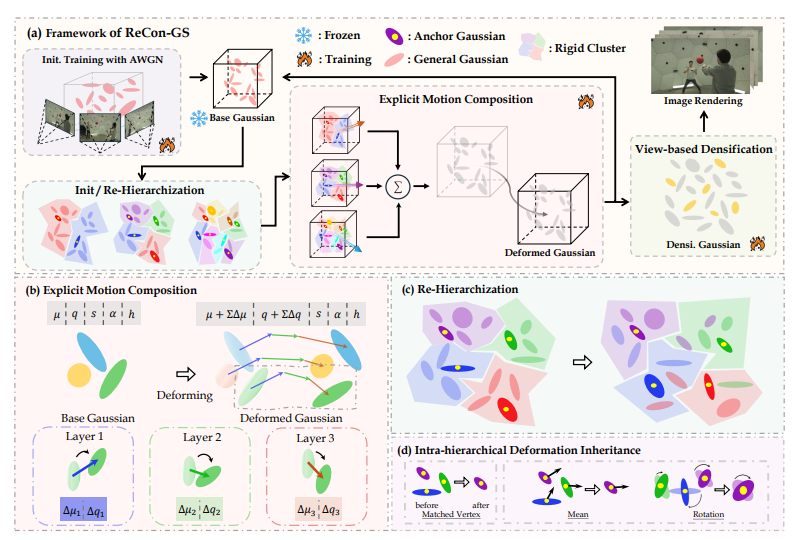
图1|ReCon-GS 框架流程。(a) 首帧先生成高质量的高斯渲染(3DGS)表示,并用基于网格的最远点采样嵌入到自适应分层的运动表示中;(b) 通过显式运动合成,在后续帧上持续更新这份基座 3DGS;(c)(d) 定期执行层级重构,用层内形变继承来应对复杂物体运动,同时保持时间一致性;最后再做基于视角的点密度加密(densification),进一步细化,得到高质量渲染
ProDyG:ProDyG: Progressive Dynamic Scene Reconstruction via Gaussian Splatting from Monocular Videos【把 SLAM 思路引回动态重建闭环】
链接:https://arxiv.org/pdf/2509.17864
痛点:离线方法不扩展;在线系统要同时兼顾位姿/地图一致性与外观细节。
核心做法:
● 静-动态解耦:用运动掩码稳健跟踪位姿;
● 动态部分用Motion Scaffolds 渐进适配;
● 同时支持 RGB / RGB-D,在线运行。
效果(文中报告):新视角质量接近离线方法;相机跟踪达到动态 SLAM 级别;长序列更稳。
看点:把“跟踪—建图—渲染”做成闭环,离真实机器人/AR 实时应用更近一步
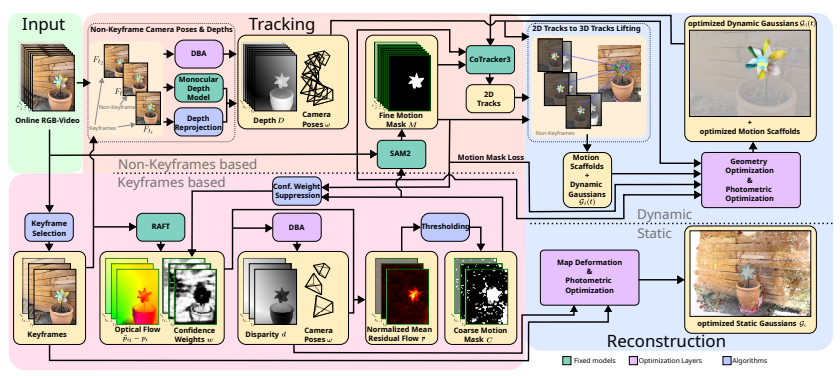
图2|该图展示了 ProDyG 的整体架构。方法首先生成基于关键帧的粗运动掩码,并以此作为提示输入 SAM2,以获得逐帧的细粒度掩码。随后,系统采用关键帧选择策略,对视频帧进行批次化的增量处理。对于静态部分,通过代理深度图优化静态高斯集合以重建背景;对于动态部分,将高斯绑定到由二维轨迹升至三维的运动脚手架上,用于编码稠密的运动场。在完成几何与光度的联合优化后,当新的图像批次到达时,运动脚手架与动态高斯会在时间轴上继续扩展,从而实现在线的动态场景重建
Temporal Smoothness-Aware Rate-Distortion Optimized 4D Gaussian Splatting【面向 4D 重建的高效压缩】
痛点:4DGS 点数庞大、时间冗余高,缺少熵感知的端到端压缩;存储与传输成瓶颈。
核心做法:
● 以 Ex4DGS 为底座,结合已有 3DGS 压缩思路;
● 引入时间平滑先验 + 小波变换编码运动轨迹,端到端 RD(Rate-Distortion)优化;
● 用户可调质量-体积档位,适配不同算力平台。
效果(文中报告):最高 91× 压缩且保持高保真;面向边缘设备/在线分发更友好。
看点:把 4D 内容的“可存可传可播”系统性补齐

图3|重建结果对比,可以看到应用提出的框架之后,可以将4DGS的重建大小进行极大地压缩(216.17MB VS 2.32MB)但是精度上的损失极小
动态 3D 的研究Motivation如何变化?
这三篇给的信号很直接:动态重建不再是“把视频变成3D”那么简单。ReCon-GS像给运动装了可调齿轮,把形变拆小块、随用随调;4D 压缩让结果既好看又省内存、好传输;ProDyG把“跟踪—建图—渲染”装回同一条生产线,在线跑、更稳定。整体上,这是从“能做个 Demo”迈向“真能上线用”的拐点。

这类研究是什么?
把 3DGS 从“能渲染得快”升级为“可部署、可维护”:大场景不爆显存、移动端也能跑、几何更准确、语义更稳定。
为什么重要?
真实业务看四件事:省资源、跑得稳、几何准、能接任务。这一类工作正是在补这些“临门一脚。
LODGE: Level-of-Detail Large-Scale Gaussian Splatting with Efficient Rendering【搞定大场景3DGS渲染】
链接:https://arxiv.org/pdf/2505.23158
痛点:大规模室内/室外场景渲染慢、显存吃紧,设备一换就掉帧。
核心做法:
● 做分层细节(LOD):按相机距离自适应选择高斯子集;
● 用深度感知平滑 + 重要性剪枝 + 细化微调构建每一层 LOD;
● 空间分块 + 动态加载,并以不透明度混合消除块边界伪影。
效果(文中报告):在室外(Hierarchical 3DGS)与室内(Zip-NeRF)基准上取得高质量、更低延迟与更低内存占用,可在内存受限设备上实时渲染。
看点:把游戏引擎式的 LOD 思路“移植”到 3DGS,大场景可用性显著提升。
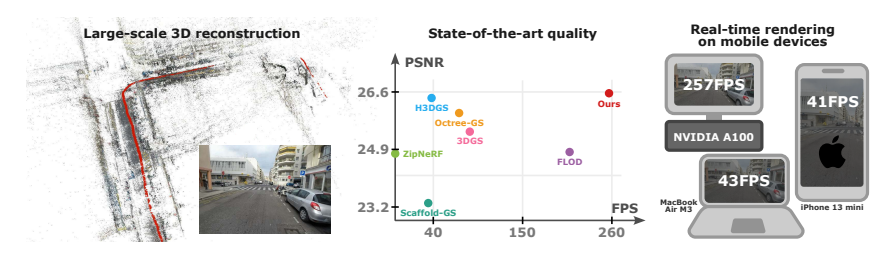
图4|该图展示了 LODGE 在大规模三维场景中的应用效果。方法在保持出色渲染速度的同时,仍能生成高质量的重建结果,并且能够在移动设备上实现实时渲染
Gaussian Herding across Pens: An Optimal Transport Perspective on Global Gaussian Reduction for 3DGS【最优传输视角的全局高斯“瘦身”】
链接:https://arxiv.org/pdf/2506.09534
痛点:原始 3DGS 常含百万级冗余高斯;传统启发式压缩(分裂/裁剪)缺乏全局质量保证。
核心做法:
● 把压缩视作高斯混合的全局规约,最小化复合传输散度;
● 基于 KD-tree 分区做几何聚合;
● 外观与几何解耦:几何压缩后,再微调颜色/不透明度以保真。
效果(文中报告):在仅保留约 10% 高斯的情况下,PSNR/SSIM/LPIPS 近乎无损,并优于现有压缩方法;可插到任意 3DGS 流水线阶段使用。
看点:从“拍脑袋剪点”升级为有数学依据的全局压缩,速度/内存收益可预期。
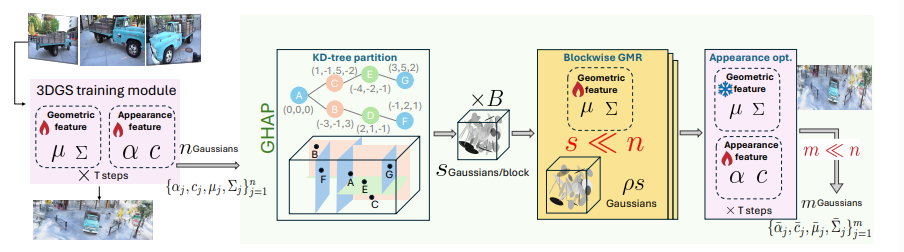
图5|该图展示了 GHAP 方法的整体流程。首先,对完整分辨率的 3DGS 进行训练,以获取初始的几何与外观特征;随后利用 KD-tree 进行空间划分,将高斯划分为若干“块”(类似围栏分区)。接着,在每个块内执行高斯混合归约(GMR),用更少的高斯近似原有几何结构,这一过程类似于“核驱赶”策略。最后,通过轻量化的外观精修进一步优化归约后的特征。整个多阶段流程逐步引导各分块内的高斯朝着更紧凑且高保真的表示收敛
VA-GS: Enhancing the Geometric Representation of Gaussian Splatting via View Alignment【通过“视图对齐”增强几何一致性】
链接:https://neurips.cc/virtual/2025/poster/117322
痛点:只靠像素重投影的监督,几何容易飘、跨视对不齐,光照变化也会干扰。
核心做法:
● 边缘感知渲染损失,强调物体边界;
● 可见性感知的跨视光度对齐,显式建模遮挡关系;
● 加入法线约束与深特征一致性,稳固局部表面。
效果(文中报告):在标准基准上达成表面重建 + 新视角合成的双向提升,报告为SOTA水平,代码将开源。
看点:把“好看”进一步做成“好看且对”,利于下游测量/交互等需要可信几何的场景。

图6|该图展示了VAGS方法的重建对比。观察细节部分,可以看到对于表面纹理的重建区域一致性更高,并且物体的边界区域重建效果分明,几何结构还原的非常准确
FHGS: Feature-Homogenized Gaussian Splatting【让 CLIP/SAM 等 2D 语义在 3D 里“稳起来”】
痛点:高斯颜色表示各向异性,而语义特征要求各向同性与跨视一致,直接嵌入容易“语义飘”。
核心做法:
● 提出通用特征融合架构,把大规模预训练 2D 语义(CLIP、SAM 等)稳健映射到 3D;
● 设计不可导的特征融合机制,使 3D 语义呈各向同性分布;
● 以“电位场”启发的双驱动优化,结合外部语义监督与内部原语聚类。
效果(文中报告):在多基准上表现出更好的特征融合、降噪与几何精度,并提出了适于实时语义建图/风格化/交互的新型 GS 数据结构。
看点:让“会说话的 2D 语义”真正住进 3D,为具身交互和语义检索打基础。
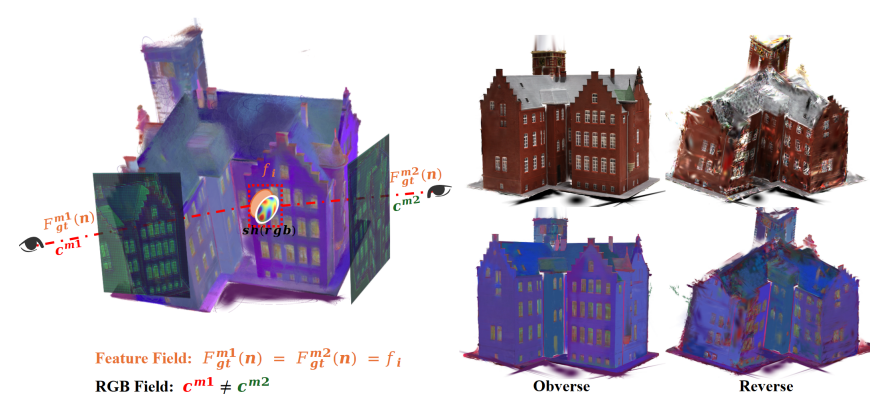
图7|该图左侧展示了高斯原语在 RGB 颜色空间中的各向异性表示与语义特征所需的各向同性表达之间的固有矛盾;右侧为正反视角下的实验结果,对比可见 FHGS 在特征融合、噪声抑制和几何精度方面均表现出更优的重建性能
这一类在补3DGS的哪四件事?
● 能省:LOD + 全局压缩 → 大场景、低显存、移动端都能扛;
● 更稳:分块加载与对齐机制 → 连续浏览与切换不出戏;
● 更准:边界/可见性/法线 → 新视角也几何可信;
● 能接任务:语义稳固进 3D → 语义建图、检索、编辑、交互都能接上;

这类研究是什么?
不只把真实场景还原出来,还要能生成新资产、拆分部件、上骨骼、做动画、改材质,让 3D 资产从“静态模型”升级为“可编辑、可复用”的生产资料。
为什么重要?
内容管线(游戏/影视/AR)、数字孪生与具身智能,都需要可编辑 + 可物理推理的 3D 世界。会“长得像”不够,还要好改、好动、讲道理(物理)。
PhysX-3D: Physical-Grounded 3D Asset Generation【物理先行的三维生成】
链接:https://arxiv.org/pdf/2507.12465
痛点:传统 3D 生成关注几何/纹理,忽略尺度、材质、可供性、运动学、功能等物理属性,落地到仿真/机器人时“不好用”。
核心做法:
● 构建首个物理标注的 3D 数据集(五维:绝对尺度、材质、可供性、运动学、功能描述),基于 VLM 的人机协同完成规模化标注;
● 提出 PhysXGen 双分支框架,在预训练 3D 结构空间中显式注入物理知识,联合建模“几何–物理”的潜在相关性。
效果(文中报告):生成的资产在物理属性预测上更合理,同时保持几何质量;具备良好的泛化能力。代码/数据/模型将开源。
看点:把“好看”变成“能用”——为物理仿真与具身智能直接产出可用 3D 资产。
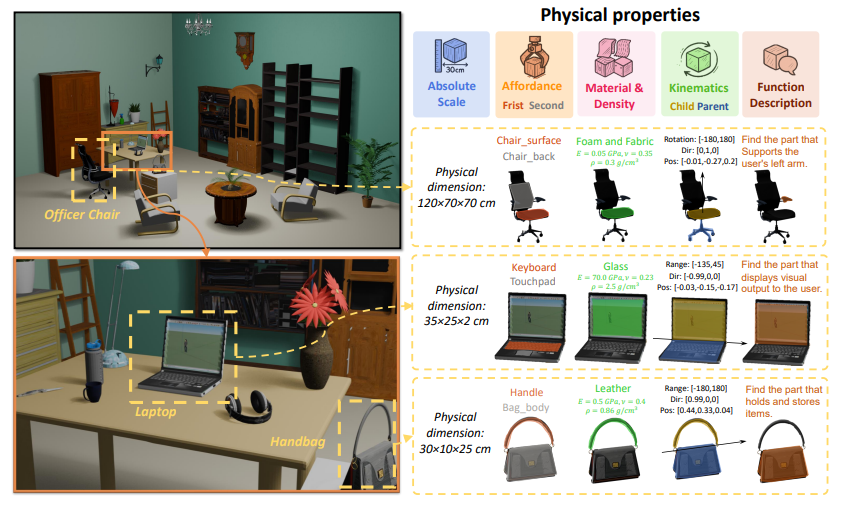
图8|该图展示了 PhysXNet 在物理属性驱动的三维生成中的可视化效果。数据集中包含带有细粒度物理标注的 3D 资产,涵盖五个维度:绝对尺度、材质属性、可供性、运动学特征以及功能描述(包括基础功能、用途功能和运动功能)
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers【3D整体的模块化生成】
链接:https://arxiv.org/pdf/2506.05573
痛点:多数方法生成一整块形体,要“拆零件再编辑”很费劲;两阶段流程(先分割再重建)易累积误差。
核心做法:
● 从单张图像同时去噪出多个语义部件的 3D 网格;
● 设计可组合的潜空间(每个部件一组解耦 token)+ 层级注意(部件内细节、部件间协调),保证全局一致又保留局部可编辑性;
● 继承预训练 3D Mesh DiT 的编码/解码权重,端到端生成可分解网格。
效果(文中报告):可生成可拆解、可重排的多部件网格,对遮挡部件也能合理补全,指标与视觉质量优于现有方法。代码与数据将开放。
看点:从“整体生成”迈向“零件先行”,天然适配参数化编辑、装配变体与机器人部件级理解。

图9|该图展示了 PartCrafter 的生成效果。该模型能够从单张 RGB 图像中一次性生成多个语义部件与完整物体,无需依赖预先分割的输入图像,实现端到端的结构化三维生成
KaRF: Weakly-Supervised Kolmogorov-Arnold Networks-based Radiance Fields for Local Color Editing【弱监督的三维“局部换色”】
链接:https://neurips.cc/virtual/2025/poster/116573
痛点:给 3D 场景做局部颜色编辑,常见问题是边界不准、多视角不一致,还容易依赖大量标注,实际落地门槛高。
核心做法:
● 提出两阶段框架:先做弱监督分割,再进行局部重着色;
● 用 KAN(Kolmogorov-Arnold Networks) 做辐射场建模,并设计残差自适应门控 KAN,更好刻画局部区域;
● 引入基于色盘的颜色自适应损失,在不破坏几何的前提下,让颜色迁移更准确、自然;
● 充分利用 NeRF 的几何先验,在低标注/弱监督下也能稳定学习。
效果(文中报告):在多套数据集上边界更准确、多视一致性更好,整体优于多种现有方法;弱监督设定降低了人工成本。
看点:这是最贴近大众创作需求的一类功能——“选区域→改颜色”的三维版:做产品外观迭代、电商多配色、数字资产风格化,都能快速、可控地落地,而且不需要重训大模型或重做高成本标注。
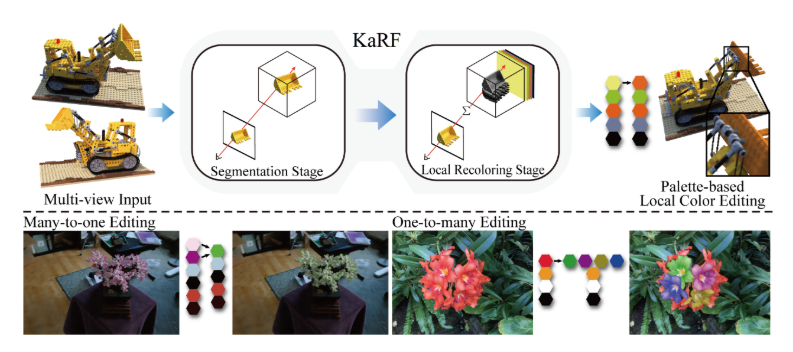
图10|该图展示了 KaRF 方法的整体流程与编辑效果。方法基于KANS构建了包含分割阶段与局部重着色阶段的两阶段辐射场框架,通过弱监督方式实现三维场景任意区域的高保真色彩编辑。上半部分展示了模型从多视角输入到分割与局部重着色,再到基于调色板的色彩自适应编辑的完整流程;下半部分展示了多对一与一对多的编辑结果,体现了 KaRF 在保持几何一致性的同时实现灵活多样的外观修改能力
生成与可编辑 3D 的研究现状
当前该领域的研究已经从“长得像”走到“好改、好用”。PartCrafter把生成粒度切到“零件级”,天生可拆装、可复用;KaRF解决“选一块就能换色”的刚需,边界更准、跨视角不翻车;PhysX把尺度、材质、可供性、运动学、功能这些物理常识补上,让3D生成结果不仅能看还能用于仿真与具身任务。合在一起,就是更低门槛的创作、更稳定的编辑,以及更贴近真实世界的三维结果。

看完这一次NIPS小领域的盘点,我们能够得到一些小结论:首先,方向更清楚了,今年的成果基本落在三条主线:让世界“动”起来(动态/时序重建更在线、更省、更稳);把高斯做成“工程件”(更轻、更准、更好用);从“还原”走向“创造+编辑”(部件级生成、低门槛编辑、物理更合理)。三条线互相咬合:前者产出可流式的数据,中间这一条把系统打磨到能部署,后者把资产真正用起来。其次,评价标准在升级,不再只看清晰度或分数,更看时延、带宽、能耗、稳定性、可编辑性,以及对下游任务(导航、交互、仿真)的实际帮助——也就是“能不能上线、值不值得用”。最后,研究的Motivation更务实,往前走会更强调语义+物理的一致性、长时序/大场景的流式更新和跨模态鲁棒性。对内容生产、AR/VR、机器人和数字孪生而言,意味着成本更可控、复用更顺手、落地更简单。本次盘点的 9 篇,只是通往这个方向的代表路标,如果各位读者感兴趣,小编在这里贴上了NIPS的paper list,供大家自由阅览~
https://neurips.cc/virtual/2025/papers.html?filter=topic&search=Computer+Vision-%3EVision+Models+&+Multimodal=&layout=detail

















 2861
2861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









