



导读
过去几年,“World Model(世界模型)”的热度迅速攀升。它不仅是学术界的研究焦点,也是产业落地的关键支撑。特斯拉在自动驾驶 FSD 中采用基于世界模型的训练方式,国内华为和蔚来也在推进相关方案,而宇树在最新的人形机器人系统中同样以 World Model 作为核心支撑。
World Model 的价值,在于为具身智能提供了一种“理解空间”的能力。如果说 VLM 是赋予机器人语义理解的工具,那么 World Model 就是帮助机器人建立“世界观”的基石。特别是在 3D 与 4D 的层面,世界模型不仅仅是图像或视频的生成,而是通过原生三维和时序四维数据(RGB-D、占据网格、LiDAR 点云等)来表示和预测动态环境。
随着这类研究的快速发展,已经逐渐形成了较为清晰的技术脉络:从视频生成(VideoGen)到占据建模(OccGen),再到激光雷达点云生成(LiDARGen),不同方法对应不同的场景和需求;同时,数据集与评测体系也在逐步完善,但仍存在碎片化和标准缺失的问题。
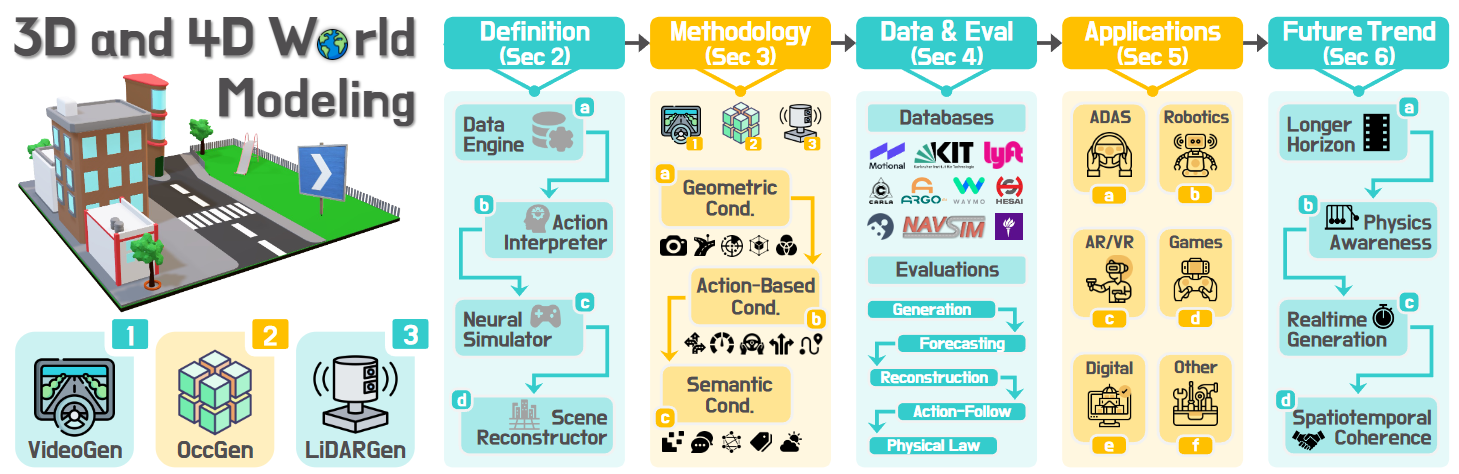
▲图1|这次盘点主要聚焦在3D/4D世界建模的几条主线:用视频建模动态场景的VideoGen、用占据网格刻画空间的OccGen,以及基于点云生成与预测的LiDARGen。我们首先定义3D\4D师姐模型,随后介绍技术路线和评价体系,最后聊聊当前的应用和产业落地。在结尾,我们讨论当前技术上的挑战与趋势,并展望未来的发展方向

核心目标
3D/4D 世界模型的任务,是让智能体能够理解、表示并预测动态环境。与以往依赖 2D 图像或视频的模型不同,它直接利用 原生的 3D/4D 表达,例如 RGB-D 图像、体素化占据网格、LiDAR 点云及其时序序列。这些模态具备几何和物理上的约束,是实现具身智能和安全关键系统(如自动驾驶、机器人)的基础。
为什么是 3D/4D 而不是 2D?
2D 数据只能提供平面投影,而 3D/4D 信号能编码度量几何、可见性、运动等信息,天然符合物理规律。它们能支撑多视角一致性、刚体与非刚体运动建模、遮挡推理、地图/拓扑一致性等关键需求。对机器人来说,不仅要生成逼真的画面,还要遵循几何、因果和可控性原则。
输入条件(Conditions)
要进行 3D/4D 世界建模,通常需要结合额外的条件信号:
● 几何条件 Cgeo:如相机位姿、深度图、占据体素,用于约束空间结构;
● 动作条件 Cact:描述智能体运动,例如轨迹、控制命令、导航目标;
● 语义条件 Csem:提供高层语义意图,如文本提示、场景图、环境属性。
两大范式
● 生成式世界模型(Generative World Models):从零或部分观测生成完整的 3D/4D 场景,强调多样性与可控性。
● 预测式世界模型(Predictive World Models):基于历史观测和动作条件预测未来场景的演化,强调时序一致性与因果合理性。
这两类方法共同赋予模型“双重能力”:既能“想象”多样的世界,也能“预见”世界的未来演化。
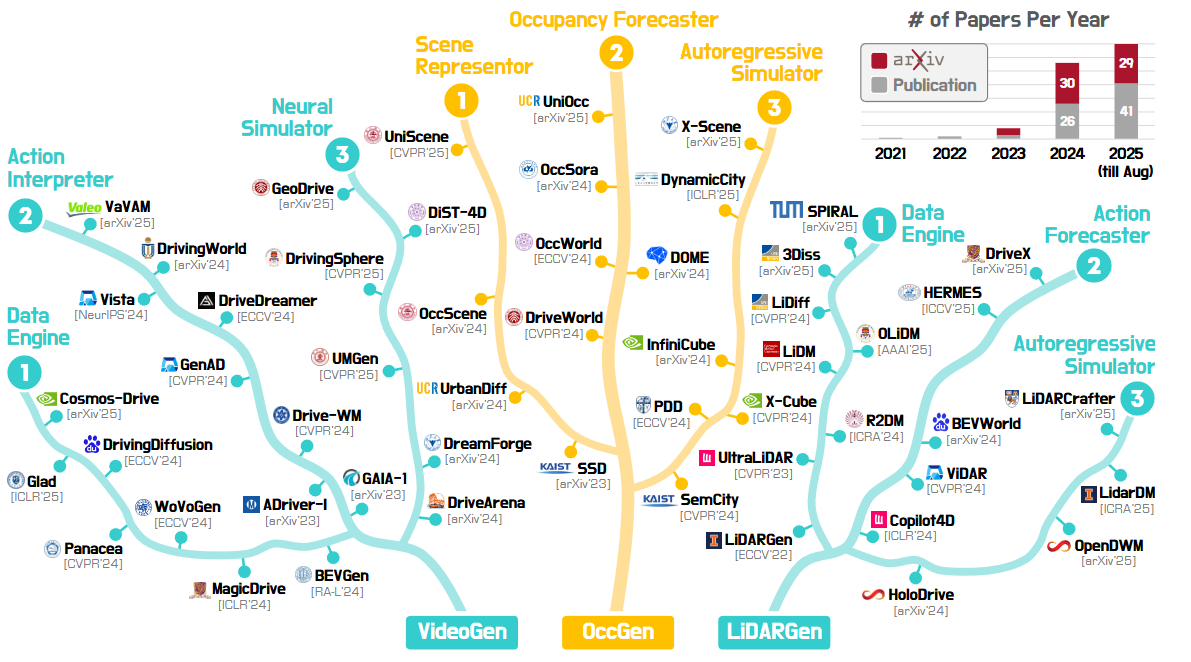
▲图2|开枝散叶的World Model研究,从图中可以看到从2021到2025,关于World Model的研究呈现跳跃式增长,并且逐步成为各大计算机视觉及人工智能学术顶会的热门研究话题

当前 3D/4D 世界建模的研究大体可以分为三类:基于视频的 VideoGen、基于占据的 OccGen、基于点云的 LiDARGen。三条路线对应不同的数据模态和任务重点,也逐渐形成了各自的应用场景。
1. VideoGen:时序驱动的世界建模
● 思路:直接以视频序列作为输入/输出,强调捕捉时间维度上的动态变化。
● 典型功能:
○ 数据引擎:生成可控的场景视频片段,扩充训练样本(如 BEVGen、DriveDreamer)。
○ 动作解释器:根据历史帧+控制信号预测未来画面(DriveArena)。
○ 神经模拟器:和策略闭环结合,构建交互式仿真。
● 优劣:视频模态直观,容易结合视觉大模型,但缺乏明确的几何约束;生成的未来轨迹在外观上逼真,却可能与物理规律不符。
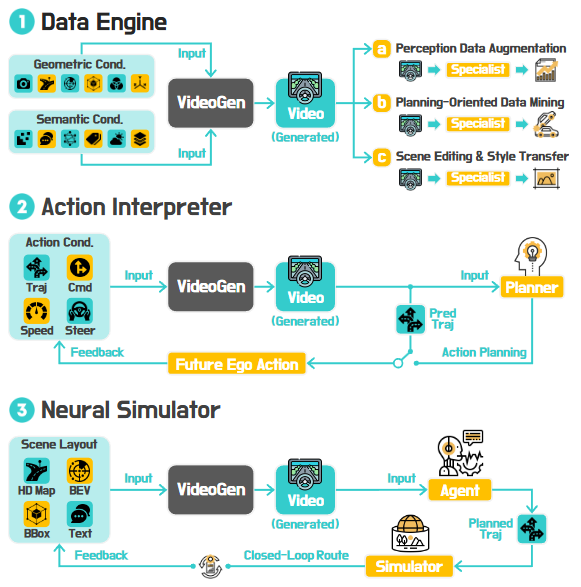
▲图3|Video Gen的技术路线图示

▲图4|不同Video Gen方法的世界建模效果示例
2. OccGen:占据驱动的世界建模
● 思路:用体素占据网格表示环境,3D/4D 扩展能同时建模空间和时间。
● 典型功能:
○ 场景表示器:把输入感知转为稠密/稀疏体素,天然满足几何一致性(OccWorld、OccSora)。
○ 占据预测器:在给定动作条件下,预测未来的占据状态。
○ 自回归模拟器:生成长时间尺度的占据序列,直接用于导航与规划。
● 优劣:几何约束强,被认为是“统一世界模型表示”的候选方案,非常适合自动驾驶;但数据量和计算开销大,训练难度高。
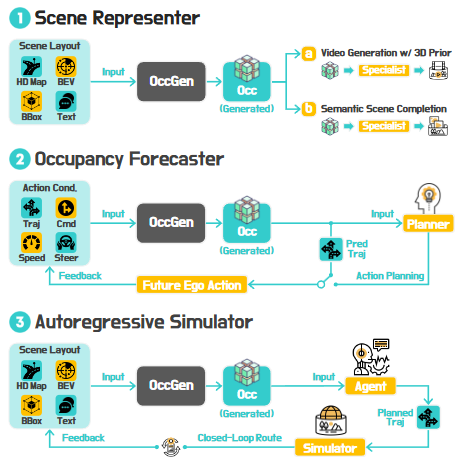
▲图5|Occ Gen的技术路线图示
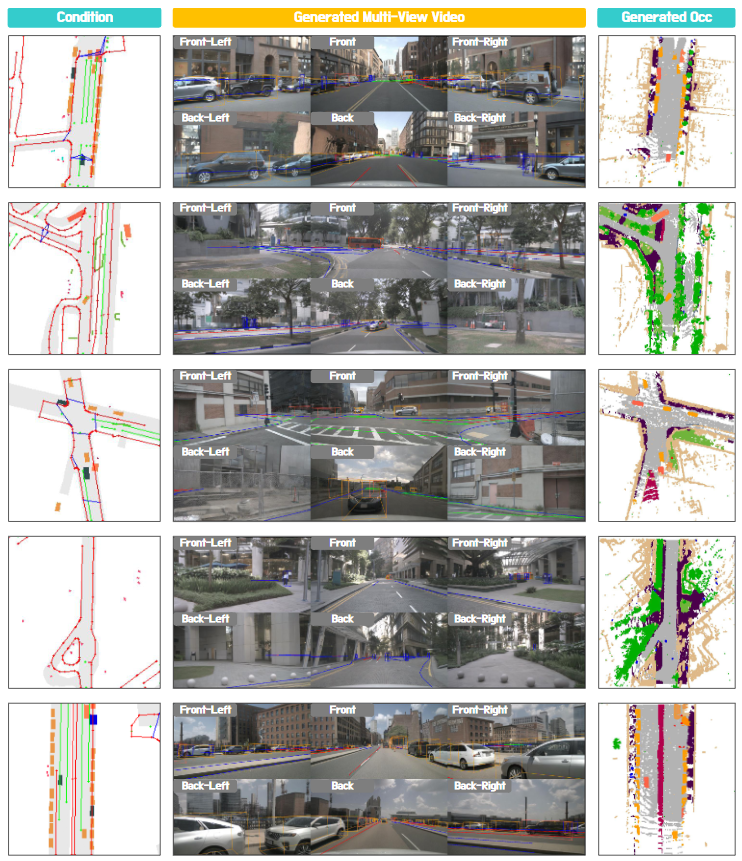
▲图6|Occ Gen方法的世界建模效果示例
3. LiDARGen:点云驱动的世界建模
● 思路:直接在 LiDAR 点云上进行生成与预测。
● 典型功能:
○ 数据引擎:合成点云用于数据增强(DUSty、LiDARGen、LiDM)。
○ 动作预测器:条件生成未来点云,结合规划与控制。
○ 自回归模拟器:逐帧生成点云序列,确保几何一致性。
● 优劣:在光照和纹理变化下鲁棒性好,能直接反映环境几何;但点云稀疏,学习时需要额外结构约束。
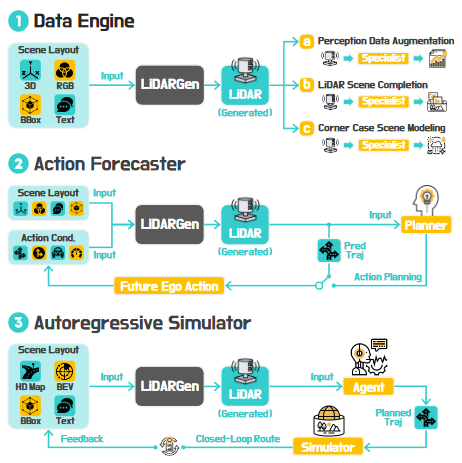
▲图7|LiDAR Gen的技术路线图示

▲图8|不同LiDAR Gen方法的世界建模效果示例
评价体系
不同路线的研究都有对应的评测方式:
● 生成质量:如 FID/FVD,衡量生成结果的逼真度。
● 预测能力:IoU、Chamfer 距离等,检验未来场景预测的准确性。
● 重建一致性:PSNR、SSIM 等,用于视角合成与重建任务。
● 下游表现:检测、分割、规划的指标(mAP、mIoU、碰撞率等)。
整体来看,缺乏统一评测标准仍是制约该领域的瓶颈,导致不同方法结果难以横向比较
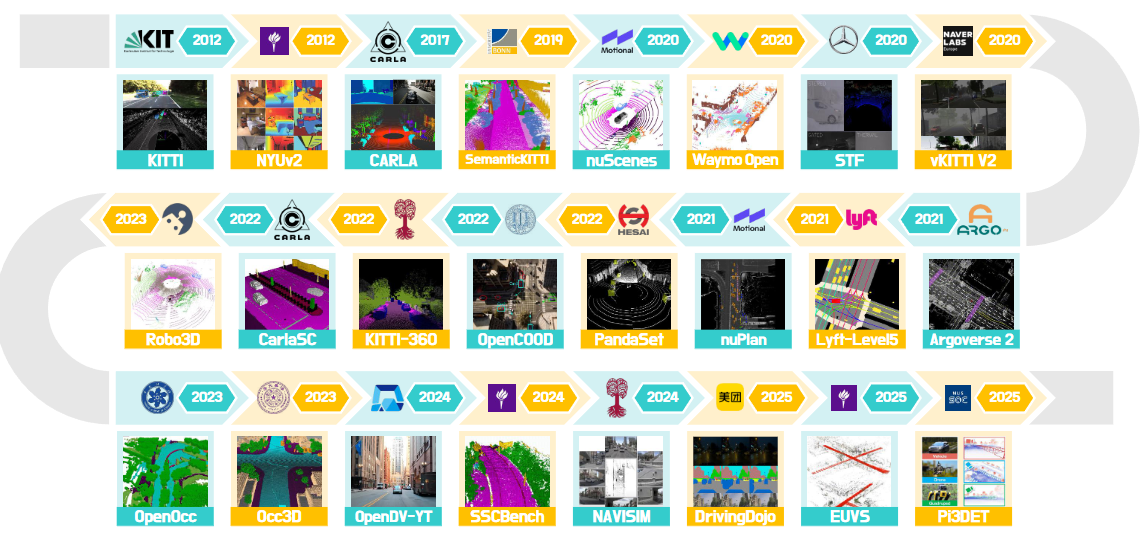
▲图9|当前常用于World Model训练及评价的数据集

3D/4D 世界建模并不仅停留在学术探索,而是已经在多个领域展现出落地潜力:
1. 自动驾驶
这是当前最主要的应用方向。世界模型可以作为 数据引擎 生成大规模合成场景,降低真实采集成本;也能作为 神经模拟器 支撑闭环仿真,提升自动驾驶策略的泛化和安全性。
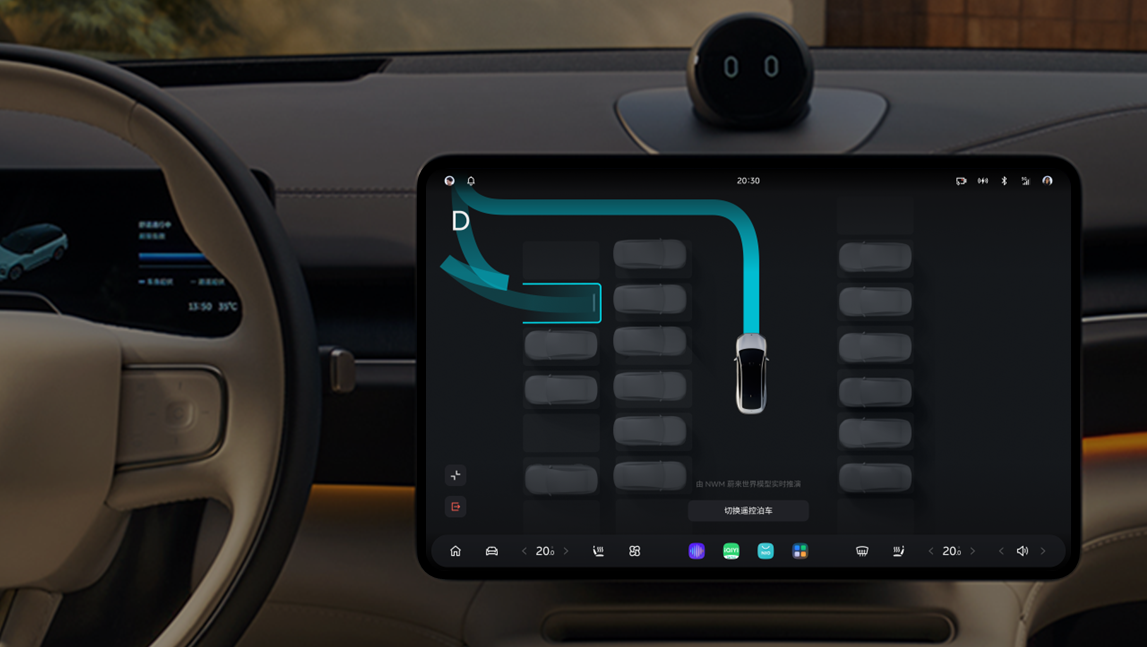
▲图10|蔚来汽车的NWM(蔚来世界模型)能够支持车辆在停车场自主漫游寻找车位停车等强大的辅助驾驶功能
2. 机器人与具身智能
在机器人场景中,世界模型同样扮演“世界观”的角色。它能够基于部分观测重建完整环境,并支持交互式任务(导航、操作),尤其在大规模和复杂环境下展现出优势。
它不仅能预测未来环境演化,还能作为场景修复与重建工具,用于数字孪生和后事件分析。

▲图11|宇树科技最近提出的开源模型UnifoLM-WMA-0就是在世界模型(World Model)中嵌入了动作头(Action)让机器人具备空间推理到动作执行的一体化能力
3. 沉浸式仿真与数字孪生
通过生成与预测能力,世界模型可以为 XR 训练、数字孪生恢复和交互式仿真 提供高保真场景。这在智慧城市、灾害应对、工业培训等方向都有应用前景。
总结来看,世界模型的功能可以归纳为 四类角色:
● 数据引擎(生成场景数据)
● 动作解释器(预测未来状态)
● 神经模拟器(支持闭环交互)
● 场景重建器(完成和修复不完整观测)
这四类能力正是支撑自动驾驶、机器人和数字孪生等落地应用的核心。

尽管 3D/4D 世界建模近两年取得了长足进展,但要真正支撑具身智能与大规模落地,仍面临多方面挑战:
缺乏统一基准
不同研究使用的数据集和指标体系差异巨大,结果难以横向比较。未来需要 标准化的评测框架,同时涵盖物理合理性、时序一致性与可控性,既能在仿真中测试,也能在真实环境中验证。
长时间尺度建模的脆弱性
当前方法在短期预测中表现尚可,但随着时间延长,误差会快速积累,导致场景不一致甚至崩溃。如何在保证 高保真视觉效果 的同时,保持 长时序稳定性,是关键难题。
物理一致性与可控性不足
生成结果往往缺少严格的物理约束,可能出现与真实世界规律相违背的场景。同时,不同条件信号(几何、动作、语义)的融合不够自然,限制了模型的可控性和泛化能力。
计算效率与实时性挑战
大多数方法依赖庞大网络和多步采样,带来高延迟与内存开销,难以满足实时自动驾驶或机器人任务需求。提升 推理加速与稀疏计算 是未来的研究重点。
跨模态一致性
目前的多模态生成往往难以保持一致性,例如图像生成与几何结构对不齐,严重影响下游感知和规划。未来需要在 视觉、几何、语义三方面联合建模,保证细粒度空间对齐和时间同步。
趋势展望
未来研究将沿着几个方向推进:
● 统一范式:融合生成式与预测式建模,提升可解释性与因果一致性。
● 跨模态融合:打通图像、点云、占据等多源数据,构建一致性强的世界表征。
● 语言与推理结合:让世界模型不仅“看见”与“预测”,还具备可解释的语义推理能力。
● 开放基准与数据:建立大规模开源数据与可复现代码库,加速方法比较与迭代。
这些趋势意味着,未来的世界模型将不只是“生成器”,而会成长为具身智能的 底层认知引擎,与规划、控制和决策紧密结合。

这波 3D/4D 世界建模的热潮,说白了就是让机器真正学会“有三维世界观”。不再停留在二维图像,而是能理解空间、预测未来、补全缺失的信息。
● VideoGen 像是给机器人一双“能看时间的眼睛”;
● OccGen 则是让机器学会用网格去“描地图”;
● LiDARGen 更像是直接拿激光点云“搭骨架”。
有了这些能力,世界模型就不仅是个生成器,而是逐渐成为 数据工厂、未来预言机、仿真引擎和场景修复师。这也解释了为什么自动驾驶、机器人导航、甚至数字孪生都会对它趋之若鹜。
当然,路还很长:评测还不统一、长时间预测容易崩、物理规律有时对不上、算力消耗也很大……但正因为问题多,才更值得期待。随着这些挑战逐渐被攻克,世界模型很可能会像 VLM 之于 VLA 一样,成为具身智能绕不开的底层基石。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









