



引入
近年来,基于端到端的自动驾驶技术展现出了非凡的潜力。与传统模块化的自动驾驶范式相比,端到端自动驾驶架构不仅统一了模型的流程,减少了模块之间的误差传播,还进一步增强了系统的简洁性。
近年来,视觉语言大模型展现出了强大的推理能力,有许多工作将其扩展到了具身智能和端到端自动驾驶领域形成视觉-语言-动作模型,并展现出了优于传统模块方法的性能。
然而,现有的视觉语言模型通常将视觉输入转换为大量的视觉token,导致计算开销巨大,推理延迟增加。这对于在计算资源和推理速度都受到严重限制的实际场景中部署车辆提出了重大挑战。
为了解决上述提到的相关问题,本文提出了一种基于重建的新型视觉token剪枝框架FastDriveVLA,专门为端到端自动驾驶模型设计。相关的实验结果表明,本文提出的算法模型在不同的剪枝比例下取得了在nuScenes数据集开环规划任务上的SOTA性能。
本文贡献如下:
●本文提出了FastDriveVLA,一种新颖的基于重构的token剪枝框架,它不同于现有的基于注意力机制和基于相似度的剪枝方法。
●本文设计了ReconPruner剪枝器,通过MAE式像素重建训练的即插即用剪枝器,并引入了一种新颖的对抗性前景-背景重建策略,以增强其识别有价值token的能力。
●本文构建了一个带有前景分割标注的nuScenes-FG数据集,用于自动驾驶场景,共包含241,000个图像-掩码对。
●本文提出的方法专为端到端自动驾驶VLA模型量身定制,并在nuScenes开环规划基准上实现了SOTA性能。

nuScenes-FG数据集介绍
本文受到人类驾驶行为的启发,将自动驾驶场景中的前景区域定义为包含行人、道路、车辆、交通标志和交通障碍物的区域。同时采用Grounded-SAM在nuScenes场景中生成一致且细粒度的前景分割标注。由此产生的nuScenes-FG 数据集包含来自六个摄像机视角的241k个图像-掩码对,示例如图1所示。

图1|nuScenes-FG数据集样例
ReconPruner:基于重建的剪枝器
本文提出的ReconPruner架构包含一个剪枝层和一个打分器,如图2所示。具体而言,剪枝层由Qwen2.5-VL-3B模型的一个Decoder层来实现。打分器由一个单层的前向网络来实现。
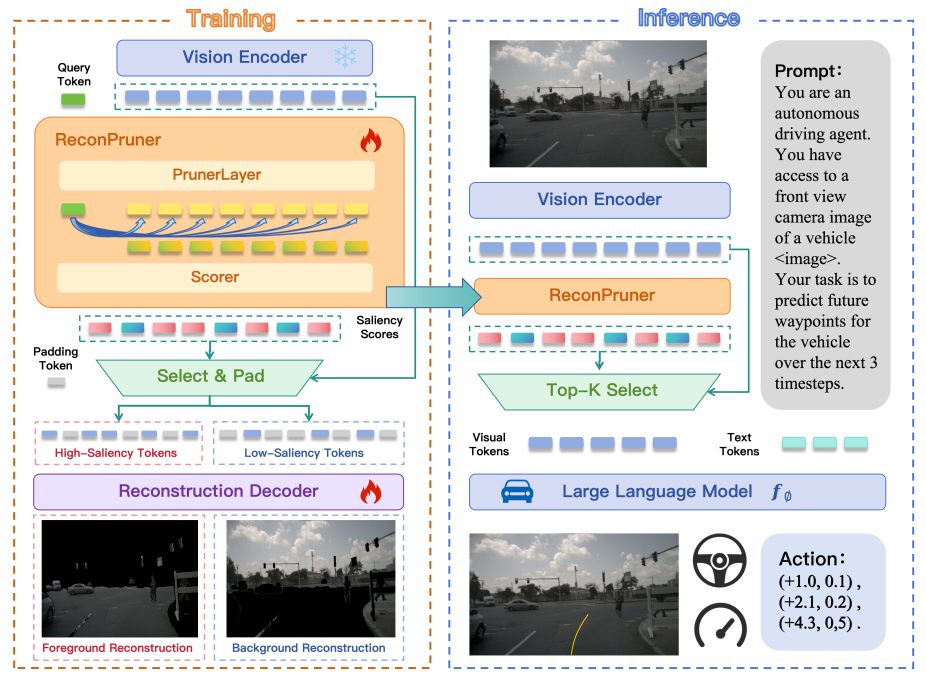
图2|FastDriveVLA算法模型的流程图
在训练和推理过程中,本文引入了一个可学习的查询token来捕捉前景中视觉token的显著性。查询token和视觉token一起送入到剪枝层中得到和
:
融合的token通过计算和
的Hadamard积来得到,随后将其送入到打分器中将显著性分数分配给视觉token。
在训练过程中,本文选择ReconPruner剪枝器预测的显著性得分最高的视觉token子集,并将其用于带掩码的前景重建。基于该子集计算的重建损失将作为监督信号,鼓励 ReconPruner剪枝器为真正与前景内容对应的视觉token分配更高的显著性得分。
对抗性前景-背景重建策略
本文作者考虑到仅仅依赖前景重建可能会导致解决方案退化,为了解决这个问题,本文借鉴了生成对抗网络的灵感,提出了一种对抗性的前景-背景重建策略。具体来说,ReconPruner需要使用获得低显著性得分的视觉token来重建背景区域。通过施加这种互补的背景重建约束,可以有效地阻止模型分配统一的高显著性得分。这种对抗性设置增强了ReconPruner剪枝器区分前景token和背景token的能力,从而提升了token的选择性能。
首先,基于ReconPruner剪枝器预测的显著性得分生成二进制的掩码,定义方式如下:
考虑到是不可导的,本文采用直通估计器,在前向传播中应用离散掩码,在后向传播中使用连续近似来实现梯度传播。该操作定义如下:
然后利用近似的掩码保留高显著性视觉token,并用填充token替换低显著性视觉token,以获得前景视觉token。用类似的方法得到背景视觉token,整个过程如下所示
重建的解码器包含六组Qwen2.5-VL-3B解码器层和一个前馈重建头。本文将和
喂入到重建解码器中得到重建的前景和背景:
训练损失函数
本文为了兼顾像素级精度和感知一致性,将重建损失公式化为均方误差和结构相似性指数测量损失的加权组合。

本文采用Impromptu-VLA作为视觉token剪枝的基础模型,并且在nuScenes数据集上开展了相关实验。
相关的实验结果如图3所示。当修剪25%的视觉token时,本文的方法在所有指标上的表现均优于所有基线方法。当修剪50%的视觉token时,大多数方法的碰撞性能都优于25%的修剪设置。同样,在75%的修剪率下,一些方法甚至比50%的修剪率获得了更高的性能。
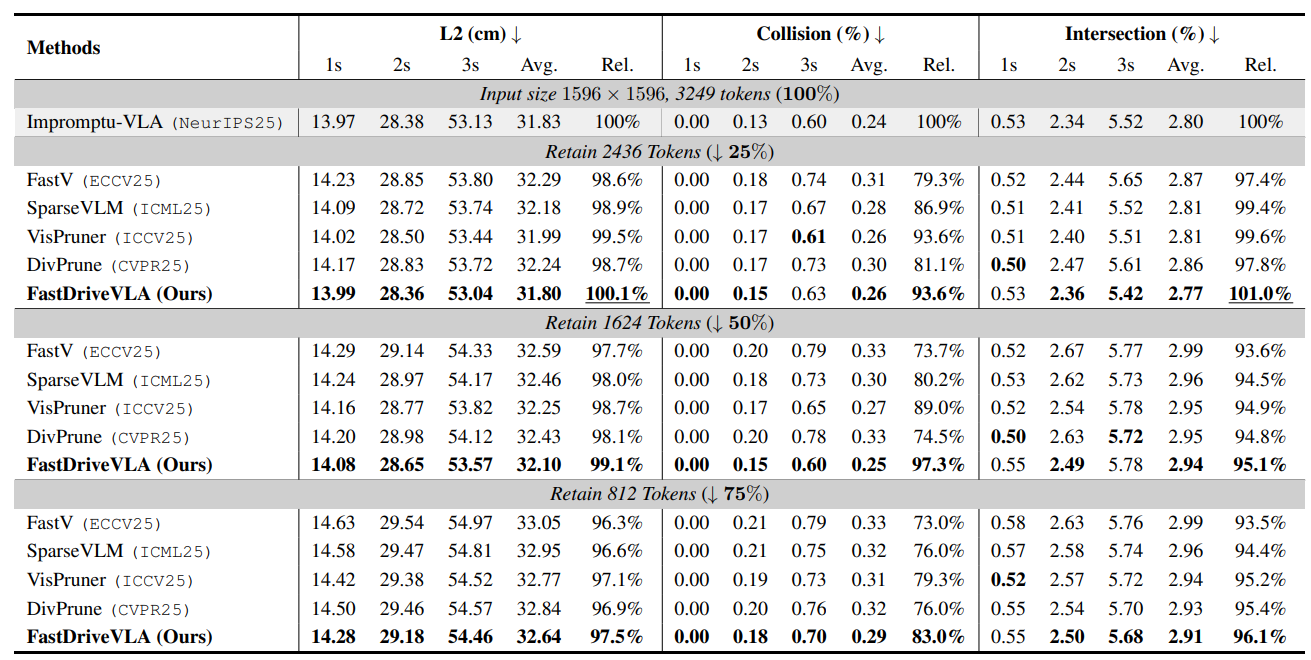
图3|Impromptu-VLA上不同剪枝方法的性能比较
此外,本文还进行了相关的消融实验来验证提出的像素重建和对抗性前景-背景重建策略对本文方法的贡献,如图4所示。相关的实验结果表明,本文提出的各类创新点均可以共同提升算法模型的最终表现性能。

图4|消融实验结果汇总
为了更加直观的展示基于重建的剪枝方法的有效性,本文展示了前景和背景重建的定性可视化效果。如图5所示。ReconPruner有效地保留了与前景对象相关的token,同时区分了背景区域,实现了高质量的重建,并展示了其在减少token冗余的同时保留重要视觉信息的能力。
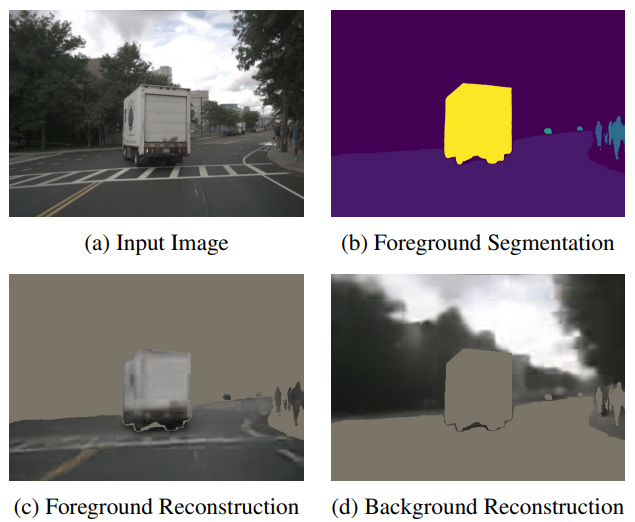
图5|重建结果可视化
此外,本文也进一步可视化了FastV、Divprune以及本文提出方法所选择的视觉token,如图6所示。

图6|不同视觉token剪枝方法保留的视觉token的视觉比较
可视化结果可以清晰地表明,本文提出的方法更好地保留了车道区域,并有效地关注了车道标志和车辆。相比之下,FastV倾向于忽略车辆,而Divprune保留了更多更分散的token,但对车道区域的关注有限。

本文提出了一种基于重构的视觉token剪枝框架FastDriveVLA,与传统的基于注意力机制和相似度的剪枝方法相比,它更适用于前景定义清晰的自动驾驶任务。在nuScenes数据集开环规划基准上实现了SOTA的性能。本文的工作不仅为自动驾驶VLA模型中高效的视觉token剪枝建立了新的范式,也为特定任务的剪枝策略提供了宝贵的见解。


















 2538
2538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









