




链接:NVIDIA Autonomous Vehicle Research Group
NVIDIA Research 的自动驾驶研究团队由 Marco Pavone 博士领导,这是一个相对年轻但跨学科背景丰富的团队,研究范围覆盖车辆自主技术的核心环节——从感知、预测到规划与控制——并致力于在不确定性决策、自监督学习,以及安全关键型 AI 系统的验证与确认等关键领域推动前沿发展。

Marco Pavone现任 NVIDIA 自动驾驶研究主管,兼任斯坦福航空航天系长期副教授。他主导斯坦福自主系统实验室( Autonomous Systems Laboratory ),并联合执掌汽车研究中心( Center for Automotive Research),研究聚焦自动驾驶、空天无人系统及未来出行体系。从MIT 博士毕业后,他获总统青年科学家奖(Presidential Early Career Award for Scientists and Engineers from President Barack Obama)、NSF CAREER 奖等多项荣誉,并被 ASEE 评为全美 40 岁以下最具潜力二十人之一,同时担任 IEEE《Control Systems Magazine》副主编。
截至2025年七月份 Autonomous Vehicle Research Group在自动驾驶对的多个重要议题上发表了众多硬核论文,其中还有不少提名为best paper,论文包含了RSS、CVPR、ICLR、 ICRA等顶级会议。
接下来,本文将对Nvidia Research在自动驾驶领域的论文进行盘点总结,盘点的10项工作涉及多个细分方向:
自动驾驶数据、多模态大模型智能体,轨迹评估,感知,重建等方面的内容
下面就来一起看看他们取得了哪些有意思的成果吧!

Cosmos Transfer 1: World-to-World Transfer with Adaptive Multi-Control for Physical AI
Cosmos Transfer 1: World-to-World Transfer with Adaptive Multi-Control for Physical AI | Research
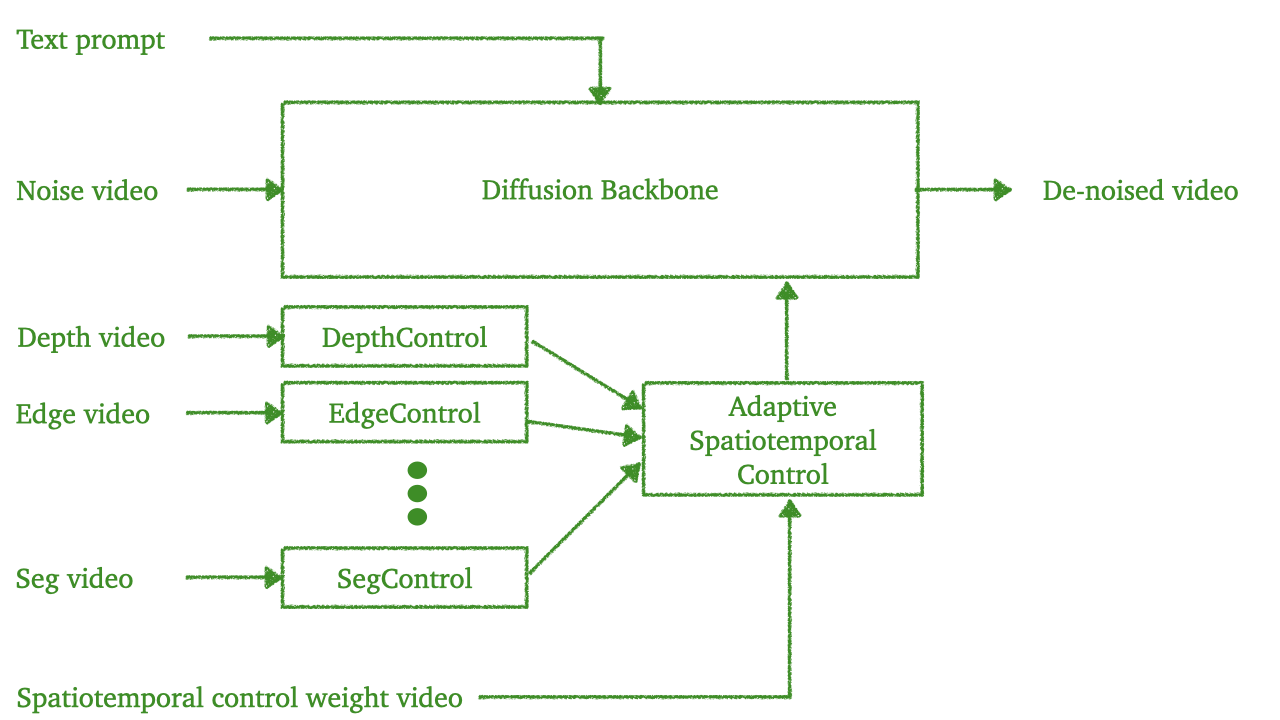

物理智能体要想与现实世界顺畅交互,离不开多模态传感器的“感官”。然而,这些“感官”往往各自带偏、信息残缺,导致感知缺口,最终拖累了决策的稳健性和泛化力。为此,Nvidia Research团队推出了 Cosmos Transfer——一套“世界到世界”的迁移模型,专门替模拟器与现实之间搭桥,让虚拟经验无缝落地到真实场景(Sim2Real)。
Cosmos Transfer 的核心是若干“自适应多 ControlNet”。每个 ControlNet 像一位专精某类世界表征的“画师”,分别用语义图、深度、边缘等线索来“作画”。到了推理阶段,这些“画师”通过一张时空控制图协同创作:这张图既可人工指定,也能让模型动态学习,从而按需合成贴合任务需求的现实画面。
在通用迁移任务和自动驾驶两大场景里,Cosmos Transfer 把五花八门的模拟世界整合成对物理世界连贯、可控且随需应变的新表征。大量实验表明,它显著提升了下游任务的泛化力、适应性和真实感。
(CVPR)OmniDrive: A Holistic Vision-Language Dataset for Autonomous Driving With Counter Factual Reasoning
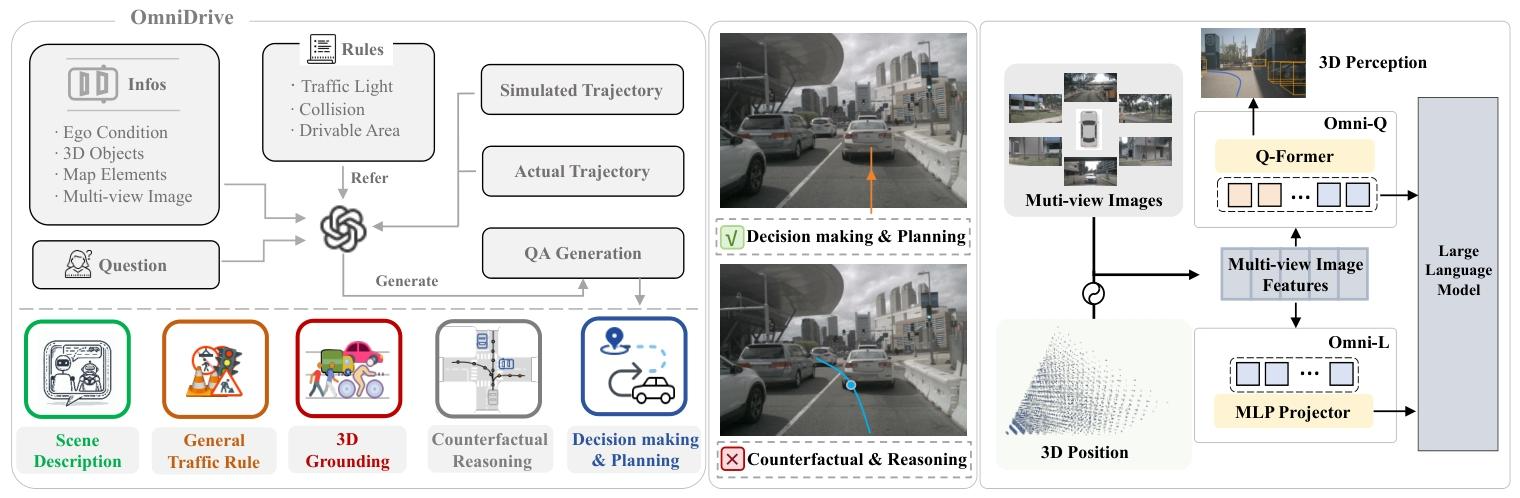

视觉-语言模型(VLM)的突飞猛进,让自动驾驶领域看到了用“语言推理”升级“驾驶大脑”的新可能。然而,把二维图片里的“能说会道”真正扩展到三维世界,才是落地关键。对此,NVIDIA Research团队推出了 OmniDrive——一套专为三维驾驶任务定制的视觉-语言数据集,核心思路是“反事实推理”:像人类司机那样,在脑子里预演不同决策的后果,再选出最安全、最合理的路线。
为了大规模生成高质量标注,团队设计了一条基于反事实的自动合成管线,把规划轨迹与语言解释牢牢绑定,显著提升了监督信号的密度。围绕这套数据,他们又打造了两大智能体框架——Omni-L 与 Omni-Q,专门用来验证“视觉-语言对齐”对三维感知究竟有多重要,也为后续大模型智能体的设计提供了宝贵经验。
在 DriveLM 问答基准和 nuScenes 开环规划任务上,OmniDrive 均取得了显著提升,用实打实的结果证明了这套数据集与方法的有效性。

(CoRL)Tokenize the World into Object-level Knowledge to Address Long-tail Events in Autonomous Driving
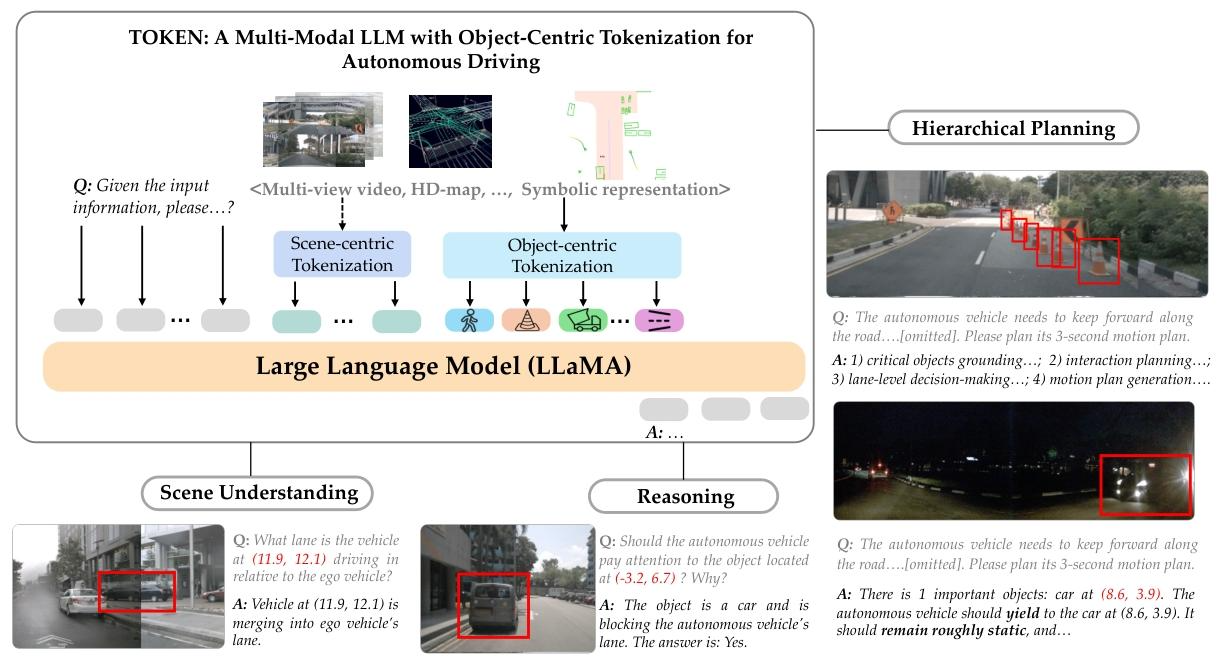
为摆脱人工先验带来的偏差,自动驾驶行业正加速拥抱“端到端”路线——直接从传感器数据学驾驶。但传统模型一旦遇到训练分布外的罕见场景,就容易“翻车”。NVIDIA Research团队推出的 TOKEN 给出新解:把真实世界拆成对象级知识标记,让多模态大语言模型(MM-LLM)用“语言”来推理驾驶,从而在长尾场景里也能稳得住方向。
TOKEN 分两步走:
1. 先用传统端到端模型把场景压成高度紧凑、语义饱满的表征;
2. 再通过“表征对齐 + 推理对齐”两阶段训练,让这些表征无缝接入 LLM 的规划接口,既省 token 又避灾难。
实验里,TOKEN 在定位、推理、规划三项任务全面领跑:长尾场景的轨迹 L2 误差降 27%,碰撞率降 39%。团队指出,只有把表征对齐和结构化推理拧成一股绳,MM-LLM 的常识推理潜能才会被真正点燃,为自动驾驶带来真正可靠的规划。
(CoRL)Wolf: Dense Video Captioning with a World Summarization Framework
[2407.18908] Wolf: Dense Video Captioning with a World Summarization Framework
视频讲解见:https://youtu.be/_waPvOwL9Z8?t=2662
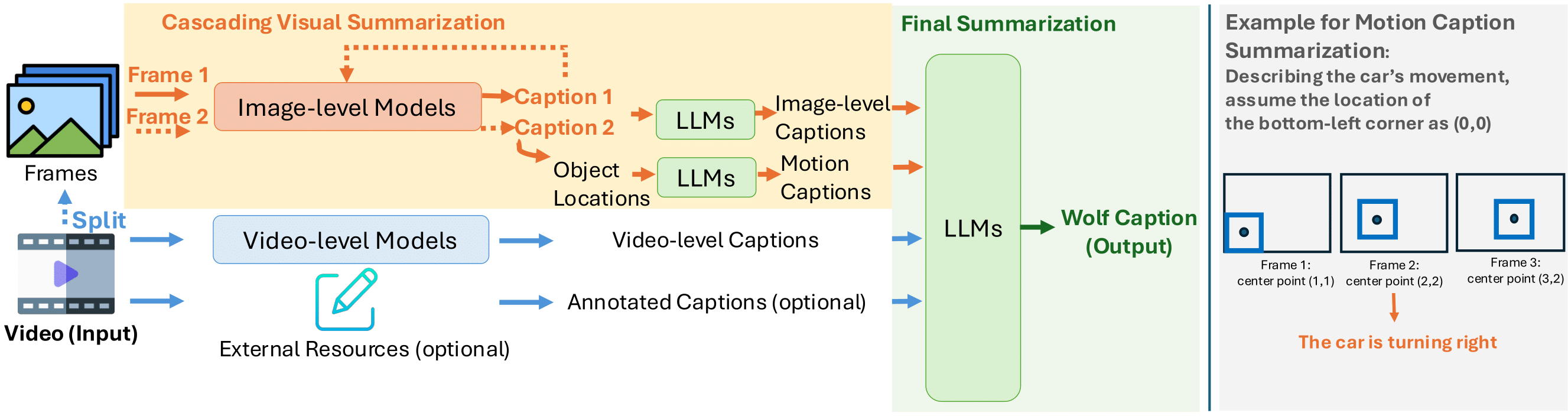
Nivida Research团队推出 Wolf——一个专为“世界级”视频摘要而设计的高精度自动字幕框架。Wolf 采用混合专家(mixture-of-experts)架构,深度融合图像与视频两类视觉-语言模型(VLM)的互补优势,既能捕捉细节,又能提炼全局语义,从而实现高效、准确的视频理解与字幕生成。该框架可直接用于自动驾驶、通用场景及机器人三大领域的视频标注、自动打标与内容摘要。
为量化字幕质量,Nivida Research团队提出 CapScore——一种基于大语言模型的评估指标,可同时衡量生成字幕与人工真值在“语义相似度”与“语言质量”两个维度的差距。此外,我们构建了 4 组人工标注数据集,覆盖驾驶、日常和机器人三大场景,为系统化评测提供坚实基础。实验表明,无论是与学术研究模型(VILA1.5、CogAgent)还是商业方案(Gemini-Pro-1.5、GPT-4V)相比,Wolf 均取得显著领先:在难度最高的驾驶视频上,相较 GPT-4V,Wolf 的 CapScore 质量提升 55.6%,相似度提升 77.4%。
(CVPR)Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
[2412.05334] Closed-Loop Supervised Fine-Tuning of Tokenized Traffic Models
交通仿真的终极目标,是让智能体在闭环演练中复现现实世界的车流轨迹分布。受大语言模型启发,如今主流的“token 化”多智能体策略虽已成为新标杆,却大多靠开环行为克隆训练,一旦进入闭环推演,就会因协变量偏移而失真。
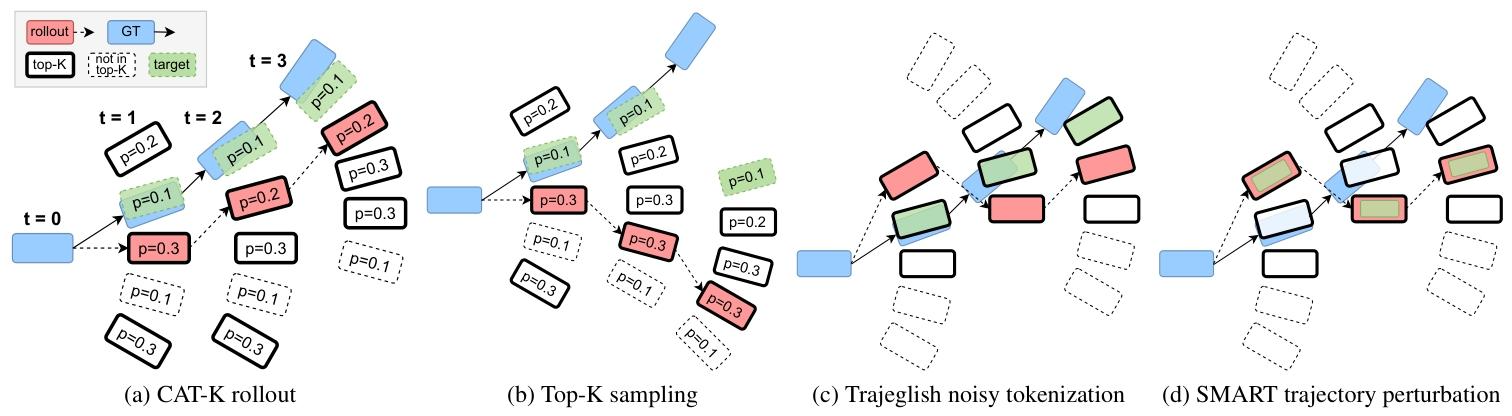
NVIDIA Research团队提出了一种极简而高效的闭环微调策略——“Top-K 中最接近者(CAT-K)”。它无需强化学习,也无需对抗模仿,只用既有轨迹数据即可完成。经过 CAT-K 微调,一个仅 700 万参数的小型 token 化交通模型,便一举击败同族 1.02 亿参数的“大个子”,在提交时登顶 Waymo 仿真智能体挑战赛排行榜。
(CVPR)Driving Everywhere with Large Language Model Policy Adaptation
[2402.05932] Driving Everywhere with Large Language Model Policy Adaptation
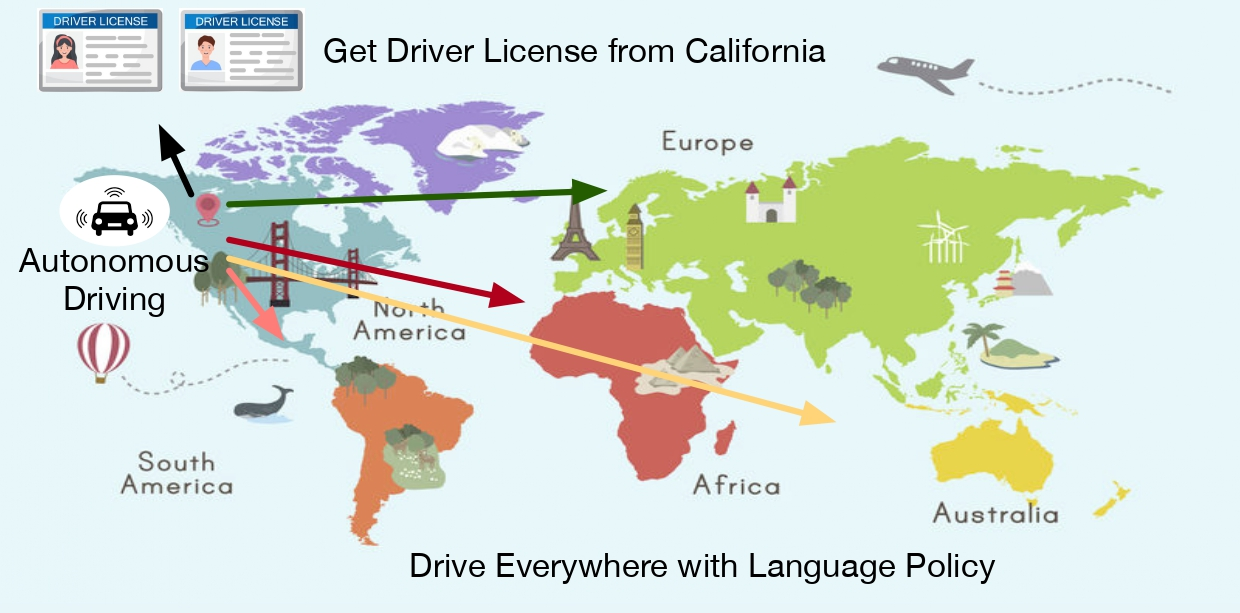
如何让自动驾驶汽车在不同国家、城市甚至街道都能“入乡随俗”,一直是阻碍其大规模落地的核心难题。为此,Nivida Research团队提出 LLaDA——一款简洁却强大的“驾驶域适配器”。它同时服务于人类驾驶员与自动驾驶系统:只需输入当地《驾驶员手册》,LLaDA 即可借助大语言模型出色的零样本泛化能力,把抽象的交通法规转化为可执行的任务指令与运动规划,真正做到“开遍天下都不怕”。
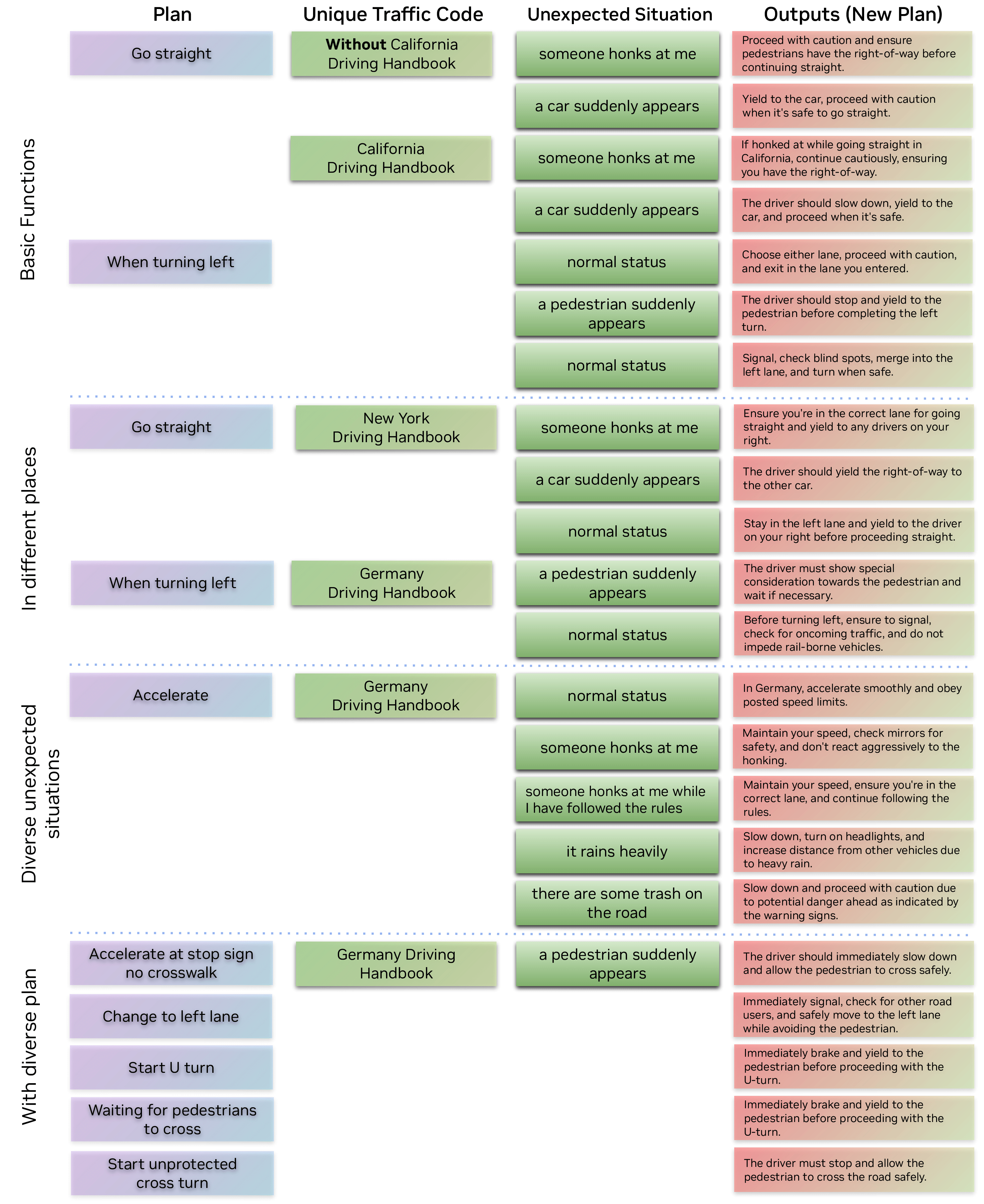
通过大规模用户实验证明,LLaDA 生成的指令能显著帮助人类在陌生或突发交通场景中快速做出正确决策;在真实公开数据集上,LLaDA 同样能实时调整自动驾驶的规划策略,并在所有评测指标上全面超越基线方法。
(CVPR)Generalized Trajectory Scoring for End-to-end Multimodal Planning
[2506.06664] Generalized Trajectory Scoring for End-to-end Multimodal Planning
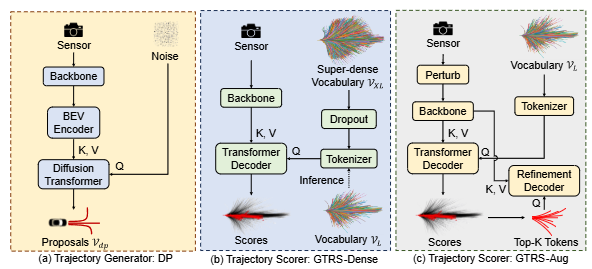
端到端多模态规划正成为自动驾驶的新范式:先撒出一大把候选轨迹,再由“火眼金睛”的打分器挑出最优。可传统方法两头不讨好——静态大词表覆盖面广却调不动细节,动态小集合精准却容易漏掉关键路径。
NVIDIA Research团队带来的 GTRS(通用轨迹打分框架)把“粗筛”与“精挑”合二为一,靠三项互补设计破局:
1. 扩散式轨迹生成器——一次性吐出既多样又精准的候选轨迹;
2. 词表泛化——在超密轨迹库里做随机丢弃正则,让小规模子集推理时依旧稳健;
3. 传感器增强——既提升跨域鲁棒性,又通过精炼训练把关键轨迹的判别力拉满。
凭借这套组合拳,GTRS 一举拿下 Navsim v2 挑战赛冠军。即便传感器信号不给力,它的表现仍能逼近“开挂”的真值感知方法,把端到端规划的天花板又抬高了一截。

(CVPR Best Paper Nomination)FoundationStereo: Zero-Shot Stereo Matching
https://nvlabs.github.io/FoundationStereo/
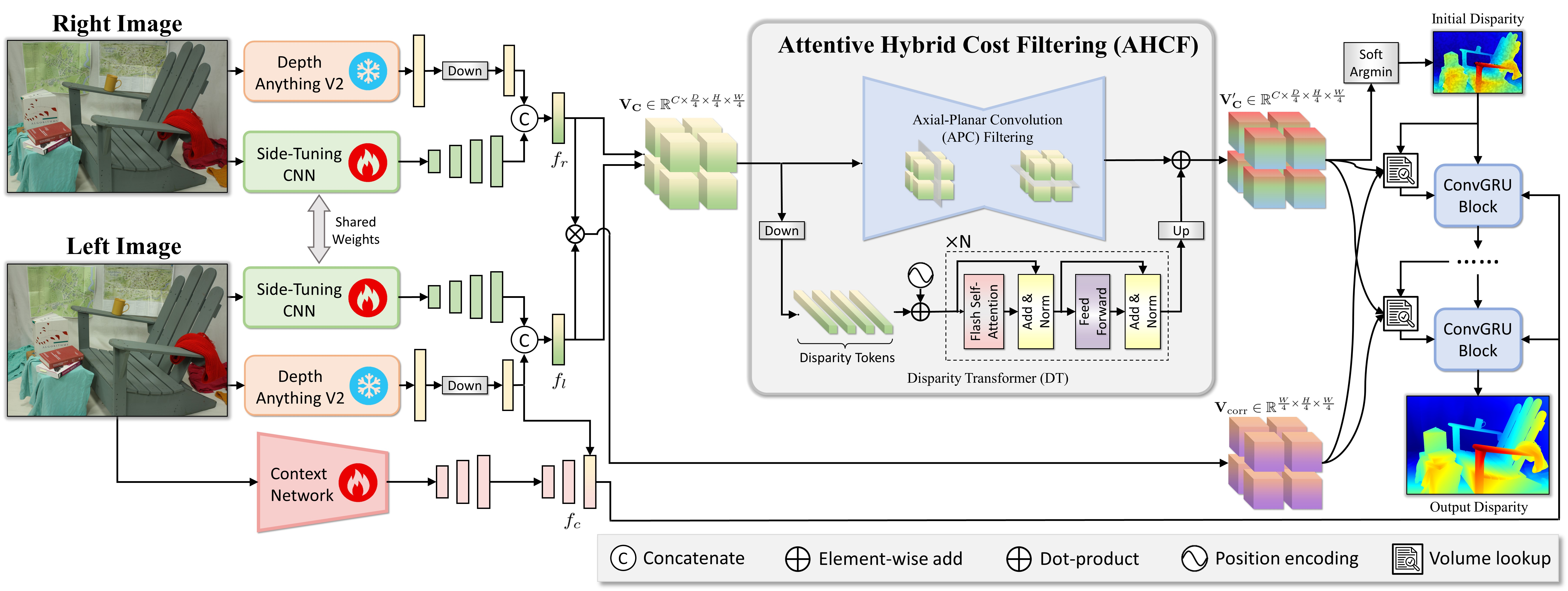
在深度立体匹配圈,“逐场景微调”刷榜早已司空见惯,可真正像视觉基础模型那样“开箱即用”的零样本立体网络,一直缺位。NVIDIA Research团队推出的 FoundationStereo 补上了这块拼图。
他们先打造了一套百万级、高逼真、分布极广的合成数据,并辅以自动清洗管线,剔除歧义样本;随后,在网络里做了三处关键升级:
1. 主干支持“侧向调优”,把海量单目先验无缝迁移到立体任务,一举抹平合成-真实鸿沟;
2. 长程上下文推理模块,专治代价体噪声,细节更干净。
在zero-shot基准上的测试结果显示,FoundationStereo 全面刷新 SOTA,为跨域立体深度估计立下新标杆。
(CVPR Best Paper Nomination)Zero-shot Monocular Scene Flow Estimation in the Wild

大模型已在深度估计等底层视觉任务上实现了跨数据集泛化,但“场景光流”这一同样关键的任务却始终没有通用基础模型可用。由于现有方法泛化能力弱,尽管场景光流潜力巨大,却一直难以落地。Nivida Research团队聚焦三大痛点并提出针对性方案:
设计几何-运动联合估计框架,确保预测精度;
发布“数据配方”,在多样化合成场景中一次性获得 100 万条带标注的训练样本,缓解数据匮乏;
系统评估多种光流参数化方式,最终采用一种更自然、更高效的表示。
由此得到的模型在 3D 端点误差上全面超越现有方法,甚至显著优于基于大规模预训练构建的基线,并在 DAVIS 日常视频和 RoboTAP 机器人操作场景中实现零样本泛化。该工作首次让场景光流预测真正走向“野外可用”
(CVPR Best Paper Nomination)Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
NeRF 与 3D Gaussian Splatting(3DGS)已极大推动了 3D 重建与新视角合成,但在极端视角下仍难逃伪影困扰。Nivida Research提出通用管线 Difix3D+,以单步扩散模型为利刃,从“渲染后处理”与“训练中净化”两端同时下手。其核心是单步图像扩散模型 Difix:在重建阶段,它先清理伪训练视角,再将“提纯”后的图像蒸馏回 3D,显著改善欠约束区域;在推理阶段,它又化身神经增强器,实时抹除因模型容量不足或监督不完美而残留的瑕疵。一枚 Difix,即可通吃 NeRF 与 3DGS,在保持 3D 一致性的前提下,将基线的 FID 平均降低 2 倍。

回顾这一年Nivida Research团队在自动驾驶领域的研究成果,从数据、模型到评估,NVIDIA Research 用十项工作把自动驾驶的“端到端”拼图几乎拼齐,真正让 AI 司机看得懂、判得准、跑得稳。


















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









