




点击下方卡片,关注“自动驾驶之心”公众号
今天自动驾驶之心为大家分享清华&博世最新的工作!Impromptu VLA:清华博世带来完全开源性能SOTA的纯血VLA!如果您有相关工作需要分享,请在文末联系我们!
自动驾驶课程学习与技术交流群事宜,也欢迎添加小助理微信AIDriver004做进一步咨询
>>点击进入→自动驾驶之心『VLA』技术交流群
论文作者 | Haohan Chi等
编辑 | 自动驾驶之心
导读
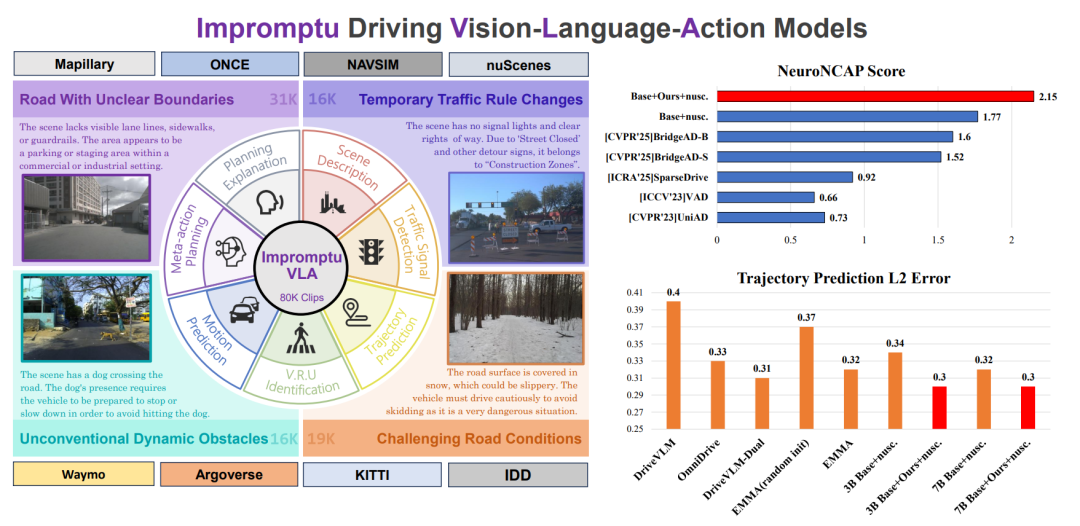
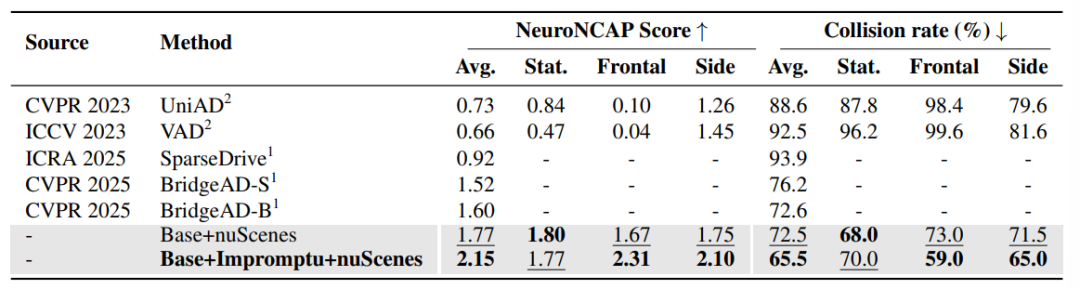
当前自动驾驶系统在城市和高速公路等结构化环境中取得了显著进展,但面对乡村小路、临时施工区、非标准交通规则以及恶劣路况等“非结构化场景”时,其鲁棒性和安全性仍面临严峻挑战。现有大规模自动驾驶数据集主要侧重于常规交通状况 ,导致在这些复杂多变的非结构化环境中缺乏专门的、大规模且精细标注的数据。为了弥补这一关键空白,清华AIR联合博世中央研究院 提出并构建了 Impromptu VLA 框架,旨在提供一个开放权重和开放数据的驾驶视觉-语言-动作模型。Impromptu VLA 是一个完全端到端、无中间感知表征的“纯血VLA”系统,其从驾驶视频片段中直接提取多模态特征,并生成自然语言格式的驾驶命令,无需手工设计感知模块、行为先验或中间BEV表达。在NeuroNCAP闭环安全评测体系中,Impromptu VLA 展现出强大的决策稳健性与泛化能力,显著超越 CVPR 2025 最新提出的 BridgeAD 系统(2.15 v.s. 1.60)。

❝论文链接: https://arxiv.org/abs/2505.23757
代码仓库 (Github): https://github.com/ahydchh/Impromptu-VLA
项目主页: http://impromptu-vla.c7w.tech/
数据集 (Hugging Face): https://huggingface.co/datasets/aaaaaap/unstructed
研究背景
自动驾驶技术取得了显著进步,尤其是在城市和高速公路等结构化环境中,具备清晰的车道标记和可预测的交通流,其导航能力已日益成熟。然而,要实现“无处不在”的自动驾驶终极愿景,我们必须超越这些常规场景,深入探索复杂且往往难以预测的非结构化道路环境。这些非结构化场景涵盖了从乡村土路、动态施工区域到标志模糊地带,甚至是经历过自然事件恢复的区域,它们共同构成了自动驾驶系统亟待攻克的下一个重大前沿。目前,现有的自动驾驶系统在这些复杂场景中经常遭遇严峻考验,因此,要充分发挥“随处可达”的自动驾驶潜力,就必须在这些领域取得突破。
然而,成功应对这一前沿挑战受到专业数据严重稀缺的极大阻碍。尽管许多现有驾驶数据集为自动驾驶的当前进展奠定了基础,但它们主要侧重于捕获常见的、结构化的交通状况。这导致在处理非结构化环境的巨大多样性和独特挑战方面存在显著的“盲点”,例如道路边界不清晰、出现非常规动态障碍物、临时交通规则变化或恶劣路面条件等。如果没有大规模、精心标注且专门反映这些复杂条件的数据集,自动驾驶系统训练的有效性将受到严重限制,也难以严格评估其在此类场景中的适应性。
为解决这一数据稀缺问题,研究团队引入了 Impromptu VLA 数据集。该数据集包含约80,000个经过精心挑选和标注的视频片段,这些片段从八个公开来源的200多万个原始片段中提取而来,重点关注四类挑战性非结构化场景:边界不清晰的道路、临时交通规则变化、非常规动态障碍物和挑战性道路条件。
我们的主要贡献包括:
Impromptu VLA 数据集: 一个公开可用、大规模、标注丰富的数据集,专门用于解决非结构化驾驶场景中的数据空白。
系统分类和数据整理管道:我们提出了一种新颖的四类非结构化场景分类法,以及可扩展的、以 VLM 为中心的数据管理流程,用于识别、分类和全面注释,并具有适用于训练高级 VLM 的多任务问答功能。
显著的性能提升: 大量实验证据表明,使用 Impromptu VLA 数据集进行训练可显著提升标准驾驶基准测试的结果,并可作为评估和改进非结构化环境中 VLM 能力的有效诊断工具。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









