




论文链接:https://www.arxiv.org/pdf/2506.16475
四足机器人(如机器狗)在复杂环境中的移动能力已很成熟,能在崎岖地形行走、适应各种场景。但它们在自主操作技能(如抓取、搬运、使用工具等)方面仍有很大不足,尤其是难以灵活应对多样化任务(如单臂 / 双臂操作、精细工具使用、长流程任务等)。
传统机器人训练方法依赖大量机器人自身数据,但收集四足机器人的操作数据成本高、效率低,且难以覆盖多样化场景。人类数据虽容易获取(人类操作数据中包含丰富信息),但人类与四足机器人的形态差异极大(比如人类用手和躯干操作,机器人用腿部末端执行器和躯干移动),直接套用人类数据难以有效地将人类动作迁移到四足机器人中去。
如果想在四足机器人的运动上利用人类操控数据,那么相应的跨形态学习方法则是必须要考虑的事情了。然而,现有跨形态学习方法多针对机械臂或类人机器人,对四足这种 “非传统形态” 机器人的适配性差,难以处理两者在运动方式、感知能力上的巨大差距。

图1|Human2LocoMan构建了统一的框架体系,可同步采集人体示范动作与遥控操作机器人全身运动数据,并实现四足机器人操作的跨形态策略学习。
为了解决上述问题,来自Carnegie Mellon University、Google DeepMind和Bosch Center for AI的研究人员提出了一个叫做“Human2LocoMan” 的框架,简单来说,就是让四足机器人(像机器狗那样有四条腿的机器人)通过学习人类的动作,掌握更多样的操作技能。

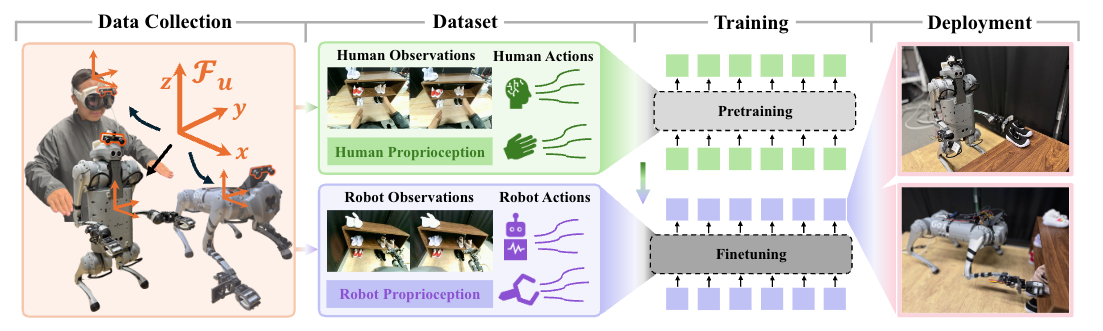
图2|Human2LocoMan框架图
Human2LocoMan遥操作系统利用Apple Vision Pro头显与机器人端的立体相机(水平视场角120°)构建多视角交互体系:操作者可通过VR设备接收人视角或机器人主视角画面,并远程操控LocoMan执行单/双手操作任务。系统创新性地将操作者头部运动映射为机器人躯干运动,以扩展工作空间并提升感知能力。在数据层面,系统同步采集人机交互数据,通过掩码机制区分不同载体形态与操作模式,并转换至共享特征空间。采集的人类数据用于预训练模块化跨载体Transformer(MXT)动作模型,而机器人领域数据则用于微调该模型,最终输出可预测LocoMan执行器六维位姿及动作的操作策略。

构建人机统一参考系: 为了能够将基于VR的人体遥操作动作映射到LocoMan的不同操作模式,并增强运动数据在不同具身形态间的可迁移性,研究人员建立了一个统一参考系,用于对齐不同机器人的动作。如图2(a)所示,该统一参考系固定于主相机安装的刚体上。在机器人的初始姿态下,x轴指向正前方,与操作空间方向一致且平行于地面;y轴指向左侧;z轴垂直向上指向。
动作映射方法:研究人员将操作者手腕动作映射至LocoMan的末端执行器运动,将头部动作映射至机器人躯干运动,同时将手部姿态映射至机器人的执行器动作其中头部位姿表示为,左右手腕位姿分别表示为
与
。此处
代表 VR 世界坐标系中的平移向量,
代表旋转矩阵。
随后,通过变换公式将 6 自由度位姿转换至统
一参考系,其中
表示 VR 参考系相对于统一参考系
的旋转矩阵。
全身控制器实现方案:遥操作服务器计算出时间步的机器人目标位姿
后, 将其发送至 LocoMan 机器人的全身控制器。研究人员通过零空间投影实现运动学目标追踪,并采用二次规划进行动态优化,最终解算出各关节的目标位置、速度及扭矩参数。
人机形态差异控制策略:为克服操作者与 LocoMan 机器人间的显著具身形态差异,并实现带全身运动的动态四足平台平稳遥操作,研究人员在系统中集成了关节运动限位规避、奇异点处理、自碰撞检测及动作平滑化机制。操作度指标通过下式计算:
用于评估目标位姿逼近奇异状态的程度,其中$\mathbf{J}$表示目标位姿下机器人机械臂的雅可比
矩阵。
若低于预设阈值
,则判定目标位姿处于奇异点附近。自碰撞检测采用Pinocchio 库计算机体部件间碰撞对。
当触发以下任一条件——关节运动越限、奇异点状态或自碰撞发生——全身控制器将自动切换追踪 位姿而非
。为抑制动作突变,系统对躯干
与
、右执行器
与
、左执行器
与
位姿进行线性插值,同时对夹爪开合角
与
实施平滑处理。

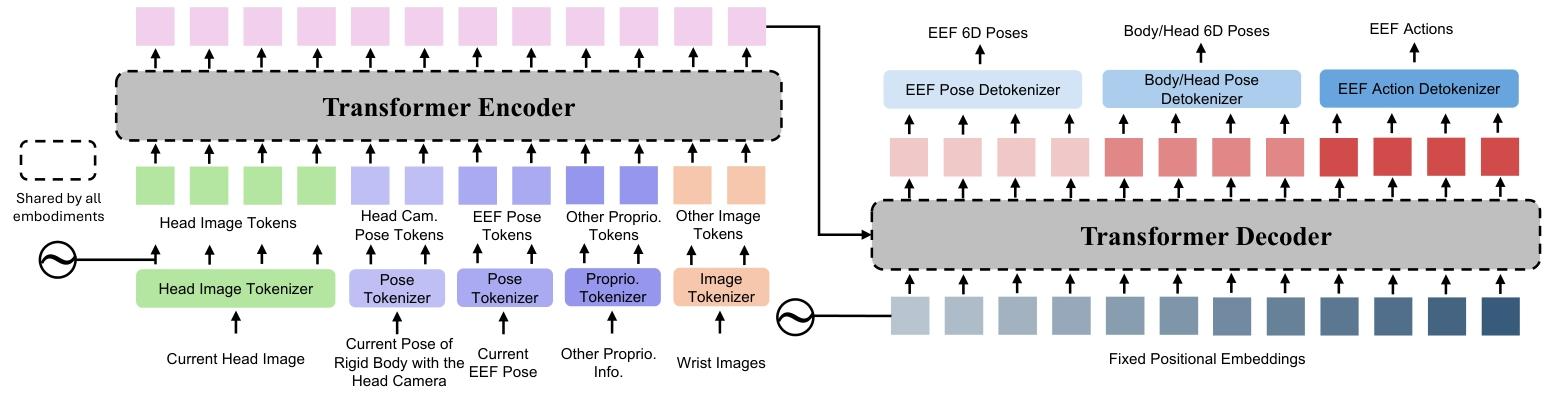
图3|模块化跨机器转化器模型架构图
如图3所示,MXT主要由三组模块构成:分词器(tokenizers)、Transformer主干网络(trunk)及解码器(detokenizers)。分词器作为编码器,负责将机器人自身的观测模态映射至潜在空间的特征token;解码器则将主干网络输出的特征token转化为各机器人形态动作空间中。其中tokenizer与detokenizer为单一机器人形态量身定制的专用模块,不同的机器人形态对应的模块也不同;而Transformer主干网络在所有机器人形态间共享,支持跨形态的操作策略迁移复用。
Tokenizer:Tokenizer将原始观测数据转换为Transformer主干网络所需的特征token。参照HPT(Heterogeneous Pre-trained Transformers
)的设计思路,采用特征抽取交叉注意力层将各模态观测特征格式化为固定维度的token序列。针对图像输入,其特征通过预训练的ResNet编码器提取(该编码器在训练过程中可参与微调);对于本体感知或结构化状态输入,则通过可训练的多层感知器(MLP)网络对原始数据进行特征计算生成对应token。
Detokenizer:Detokenizer 作为动作解码器头,负责将主干网络输出的特征token映射至各机器形态动作空间中。为降低误差累积效应并减少模型推理频次,采用动作块预测机制:在每个推理步中,Detokenizer一次性输出 h步连续动作序列。单个Detokenizer内部通过可学习交叉注意力层,将主干网络固定位置生成的潜在动作token转换为维度匹配的h步动作序列。
主干网络架构:主干网络采用编码器-解码器结构的Transformer模型,其输入序列长度与输出序列长度均固定不变。通过在人机多具身形态间共享主干网络权重,模型得以学习处理多模态特征token的生成机制,同时有效捕捉跨机器形态的通用决策模式。
模态解藕机制实现:基于跨机器形态统一的数据格式及标准化的观测/动作空间,模型能够分别处理观测输入与动作输出中每个语义独立模态单元,并与Transformer主干网络和特征Tokenizer/Detokenizer进行自定义组合。该设计既保留了各机器形态特有的模态分布规律,又使模型能够显性处理跨具身形态的分布差异问题。
研究人员采用多个模态级特征Tokenizer ,在更细粒度的模态单元
上对观测输入
进行独立编码。例如,系统摒弃了传统方案中先将所有图像输入聚合再通过视觉Tokenizer的做法,转而针对主相机视角与腕部相机视角分别部署独立的特征Tokenizer。最终,所有已编码的模态单元将串联组合为Transformer主干网络的输入token序列。
同样地,在进行Detokenize时,需指定Transformer输出token中对应每个动作模态的子集,例如身体姿态、末端执行器姿态和夹爪动作,并通过独立的Detokenizer 解码所选token以生成各模态。
通过显式解耦输入输出模态并分别编码,模型能够利用观测与动作的内在结构,将这种结构强加至Transformer处理的token序列中。因此,训练期间习得的不同模态处理方法可在不同机器系统之间共享,进而保证了策略的高效迁移。


算法1描述了MXT训练流程的具体细节。对于给定任务,首先使用人类数据集进行模型预训练,随后利用对应LocoMan数据集进行微调。微调期间仅从预训练检查点初始化Transformer主干权重。针对语义相似但操作模式不同的任务(对应表I中的不同具身系统),研究人员在这些任务上采用不同操作模式的人类数据集联合预训练模型,随后使用对应LocoMan机器人数据集在各任务上分别微调。

表1|Human2LocoMan机器数据
优化目标:研究人员在预训练与微调阶段均采用行为克隆目标函数。通常,给定具身系统 的数据集
及对齐的动作模态
,在系统
上的训练总损失函数为:
其中表示动作模态
在系统
数据集上的
损失。实际训练中, 研究人员对每个训练批次
优化如下批量损失函数,作为
的替代:
式中: 动作标签序列样本 中,
表示第
步模态
的动作;
表示第
步模态
的预测动作;
为分段步长或动作跨度。

研究人员设计了一系列实验以回答如下的问题:
1. Human2LocoMan系统是否能实现多样化的四足机器人操作能力?
2. MXT框架相较于当前最优模仿学习架构表现如何?
3. Human2LocoMan系统采集的人类数据对模仿学习性能有何贡献?
4. MXT框架的设计选择能否促进人类操作向LocoMan机器人的正向迁移?
实验设置
任务:使用 Human2LocoMan 系统收集的数据,在 LocoMan 机器人的单手 / 双手操作模式下,对 6 项不同难度的家庭任务评估 MXT:
● 单手玩具收集(TC-Uni):机器人需拾取矩形区域内随机摆放的玩具并放入地面篮子,涉及抓取和释放动作,使用 10 个物体微调,全部物体用于预训练和评估。
● 双手玩具收集(TC-Bi):类似 TC-Uni,但玩具位于篮子两侧矩形区域,同样使用 10 个物体微调。
● 单手鞋架整理(SO-Uni):长时序任务,需整理鞋架不同层的两只鞋,涉及推、敲击等动作,包含 3 双鞋(1 双为 OOD)。
● 双手鞋架整理(SO-Bi):将第三层边缘的一双鞋向内推并对齐,涉及推和敲击动作。
● 单手铲取(Scoop-Uni):使用铲子从猫砂盆不同位置铲取 3D 打印猫砂并倒入垃圾桶,涉及工具使用和可变形物体操作,包含抓铲、倾倒等子步骤。
● 双手倾倒(Pour-Bi):双手操作将乒乓球从一个杯子倒入另一个,需精准抓取杯子并倾倒,涉及拾取、倾倒和放置动作。
Human2LocoMan 实体模式:单手和双手模式在形态、观察空间和动作空间上不同,单手任务使用腕部摄像头。
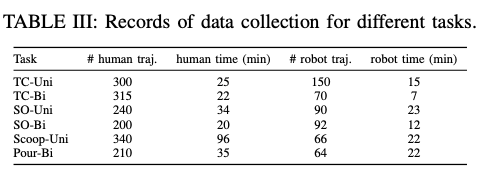
数据收集:每个任务收集不同数量的人类和机器人轨迹数据,10% 用于验证(具体见下表)。
训练细节:玩具收集和鞋架整理任务中,先利用单 / 双手人类数据联合预训练模型,再用对应机器人数据微调;所有任务使用相同超参数(如批量大小、数据块大小),模型超参数见附录。
基线方法:与以下 SOTA 模仿学习方法对比:
● 人形模仿 Transformer(HIT):基于 ACT 的解码器架构,同时预测动作序列和图像特征,引入 L2 图像特征损失防止过拟合,仅使用机器人数据训练。
● 异构预训练 Transformer(HPT):在仿真、真实机器人和人类视频的异构数据上预训练,包含主干和头尾结构;与 MXT 区别在于:MXT 按模态对齐数据并保留模态特异性,而 HPT 使用单一标记器,且冻结图像编码器(MXT 端到端微调)。对 HPT 测试三种设置:仅用 LocoMan 数据、人类数据预训练 + LocoMan 微调、直接微调预训练 checkpoint。
评估指标:
● 成功率(SR):ID 物体测试 24 次,OOD 物体测试 12 次,计算完成所有子步骤的比例。
● 任务得分(TS):每个子步骤完成得 1 分,达成最终目标额外 1 分,总分由所有测试回合累加。
● 验证损失:反映模型优化程度,用于对比不同架构训练过程
结果与分析
Human2LocoMan 系统是否赋予四足机器人多功能操作能力?
实验结果总览。研究人员在表II中汇总了本方法与HIT在所有任务中的成功率和任务得分。Human2LocoMan的MXT框架凭借较小规模数据集即在所有任务上表现优异,基准方法在多数任务中也取得良好性能。这些结果既印证了所采集数据的高质量,也验证了Human2LocoMan数据收集与训练流程的有效性。

表2| 实验结果汇总。研究人员报告每项任务的成功率(SR)↑(百分比形式)及任务得分(TS)↑,最优性能以加粗字体标出,次优性能以下划线标识。ID结果基于24次实验汇总而来,OOD测试结果基于12次实验汇总而来。

表3|不同任务上的数据收集记录

图4|MXT策略的执行轨迹及实验所用操作任务物体图 绿色箭头指示末端执行器运动,红色箭头表示躯体移动,粉色箭头代表夹爪动作。
MXT 与 SOTA 模仿学习架构的对比如何?
与基线模型HIT和HPT相比,MXT模型展现出显著优势。相较于HIT,无论是否经过预训练,MXT在多数单/双手操作任务、ID/OOD场景下的成功率(SR)和任务得分(TS)均达到相当或更高水平,尤其在预训练后性能全面超越HIT(见表2)。验证损失分析显示MXT收敛性更优(见图7),且数据规模增大时性能提升更显著(但需注意在特定子任务中,HIT因场景单一性可能出现更低验证损失)。而相比HPT,MXT在玩具整理任务的所有预训练与数据规模组合中全面领先(见图5和图8),验证损失更低且未出现HPT表现出的严重过拟合现象,突显其模块化设计对泛化能力的提升作用。
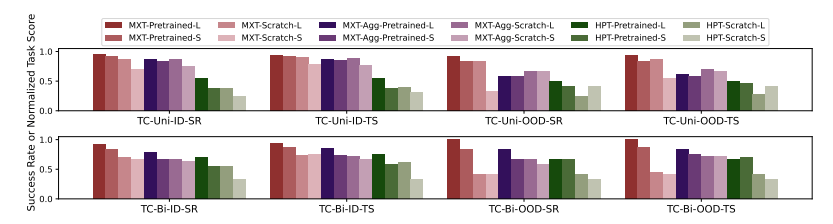
图5|单臂式与双臂式玩具收集任务消融实验结果。研究人员在成功率与任务得分指标上对比MXT、其变体MXT-Agg及基准方法HPT。此处,"L"表示较大训练集(单臂玩具收集任务40条轨迹,双臂玩具收集任务60条轨迹);"S"表示较小训练集(单臂玩具收集任务20条轨迹,双臂玩具收集任务30条轨迹)。
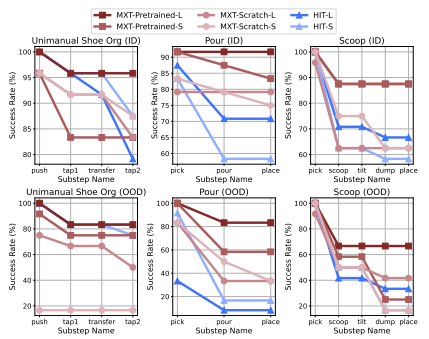
图6|子步骤成功率。特定子步骤的成功率计算为机器人成功完成该子步骤的实验比例。研究人员针对每项任务,均基于24次分布内测试及12次分布外测试进行计算。其中- MXT预训练版:采用人类数据集预训练MXT(单双臂任务如适用则包含),随后使用LocoMan数据微调 - MXT零基础版:仅采用LocoMan数据训练MXT 。"L"表示较大训练集(单臂鞋架整理任务80条轨迹,倾倒与舀取任务60条轨迹),"S"表示较小训练集(单臂鞋架整理任务40条轨迹,倾倒与舀取任务30条轨迹)。
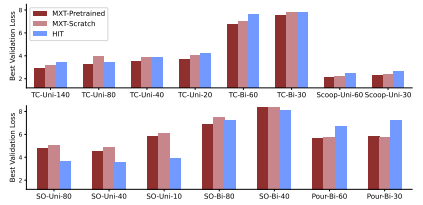
图7| 各任务方法最佳验证损失值对比。研究人员将本方法与HIT在全部任务中的最优验证损失结果展示如下:- MXT预训练版:采用人类数据集预训练MXT(单双臂任务如适用则包含),随后使用LocoMan数据微调- MXT零基础版:仅采用LocoMan数据训练MXT(模型编号后缀表示LocoMan训练集的示范样本数量。)
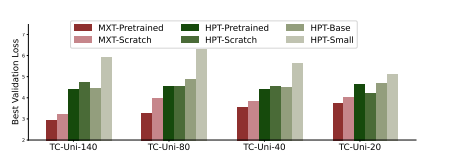
图8| 单臂式玩具收集任务方法最佳验证损失值对比。研究人员将本方法与HPT在该任务中的最优验证损失结果展示如下:MXT预训练版:采用人类数据集预训练MXT(单双臂任务如适用则包含),随后使用LocoMan数据微调- MXT零基础版:仅采用LocoMan数据训练MXT - HPT预训练版:主干网络基于人类数据预训练后,使用LocoMan数据微调 -HPT零基础版:仅采用LocoMan数据训练HPT网络 - HPT基础版:使用官方HPT基础权重初始化主干网络,结合LocoMan数据微调 - HPT精简版:使用官方HPT精简权重初始化主干网络,结合LocoMan数据微调
Human2LocoMan 收集的人类数据如何提升模仿学习性能?
MXT模型通过人类数据预训练显著提升了机器人的操作性能,在效率、鲁棒性和泛化性方面均表现突出。预训练不仅使模型在机器人数据有限时保持强劲性能(尤其在玩具收集、勺取等任务中),还促进了更平滑稳健的动作生成,显著提升了目标物体的定位精度(如图6所示勺取任务优势)。在涉及未知物体的OOD场景中,预训练模型也展现出优秀的跨场景泛化能力。对于长时域多步骤任务(如鞋整理、双手倾倒),预训练能有效维持各子步骤的成功率,关键改进在于提升了精确移动定位等困难步骤的执行能力,避免了像无预训练模型或HIT基线那样在后期步骤中快速失效的问题。这表明人类示范数据对提升操作精确性和长时任务稳定性具有重要作用。
MXT 的设计是否促进了从人类到 LocoMan 的正向迁移?
MXT框架在应对人机载体差异方面展现出卓越的跨载体迁移能力。实验表明(图8),相比HPT模型在人类数据预训练后的改进幅度有限,MXT通过预训练显著提升了在LocoMan任务上的性能泛化性。具体性能对比(图5)显示,无论是否微调,HPT在成功率和任务得分上均持续落后于MXT,这主要源于其缺乏模块化设计且采用冻结图像编码器。为验证模块化的价值,研究者构建了消融变体MXT-Agg(采用统一编码器模拟HPT结构)。结果表明:1)标准MXT的预训练效益显著优于MXT-Agg,证明模块化分词设计能更有效利用人类数据;2)MXT-Agg在迁移时可能出现负优化(微调预训练模型相比从头训练几无改进),因非模块化设计导致表示能力过强而损害迁移性;3)MXT的模块化架构通过引入正则化效果,实现了网络表示能力与迁移性间的有效权衡。

本文提出Human2LocoMan框架及其核心组件模块化跨载体Transformer(MXT),旨在通过人机协作数据收集与迁移学习提升四足机器人LocoMan的通用操作能力。该框架创新点包括:1)构建人机动作空间桥接系统,实现高效高质量数据集采集;2)设计模块化策略架构,有效利用人类示范数据优化机器人策略。在六类家庭任务实验中,Human2LocoMan在操作性能、训练效率和分布外场景泛化性方面均超越现有模仿学习方法,验证了跨载体学习机制与模块化策略设计对推动通用型四足机器人操作系统的关键价值。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









