



随着GPT-4o的发布,全网又掀起了一波语音大模型(Large Speech Model)的热潮,本文旨在梳理自GPT-4o发布半年以来各种可以实现全双工语音通话的技术方案,以供各位读者参考。
©️【深蓝AI】编译

笔者认为,全双工语音通话,其实主要围绕着语音和通话这两个核心点来展开。现有的研究工作也基本从这两个核心点入手。有的工作认为语音通话和文本对话是不一样的,因此以端到端speech2speech的方式来建模语音通话。更多的工作则是希望能够将文本LLM上的经验迁移到speech language model上来,把speech 模态的信息和原有文本模态的信息进行对齐,后文将详细介绍这些不同路线的细节。
Without Text
Generative Spoken Dialogue Language Modeling
这篇可以说是Speech Language Model的开山鼻祖了,由Facebook Research团队的研究人员提出。由于这篇工作提出的时间较早(2022年),彼时还没有刮起大语言模型的风来,因此研究人员选用的模型从现在的角度看来就显得比较简单了(几百M的Transformer Encoder 相当于0.5B甚至更小尺寸的LLM)
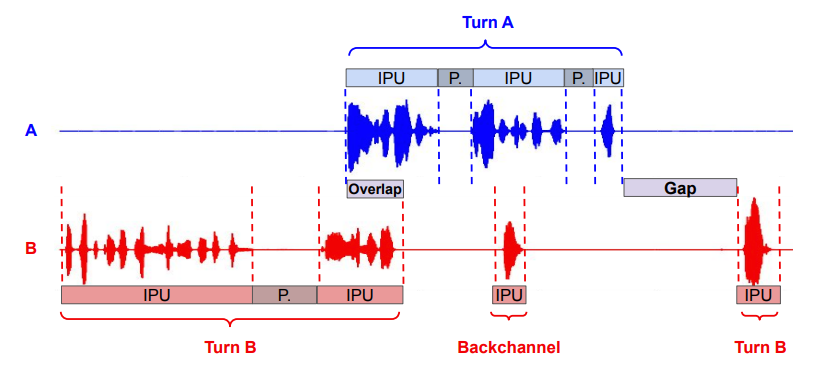
研究人员认为,在自然对话中,说话者们之间会自发地协调当前在说话的人以及另一个人接话的时间。这样对话才能够流畅地进行,而不会出现太多的话语重叠或长时间的沉默。当然,有时也会存在一些沉默和重叠,而它们携带了重要的信息,这些信息会在对话情境中被解读出不同的含义。例如,当出现话语重叠时,它通常包含与内容无关的言语信息(例如,“嗯”、“是的”)或非言语发声(例如,笑声),用于传达倾听的态度。人们似乎很早的时候就掌握了这种语音对话的能力,但是在人机交互领域,这仍然存在着不少的挑战。
研究人员探索了直接从原始音频中训练一个口语对话模型的技术方案。模型基于离散的语音表征,同时通过把对话中的两位speaker建模成两条平行的流来实现。
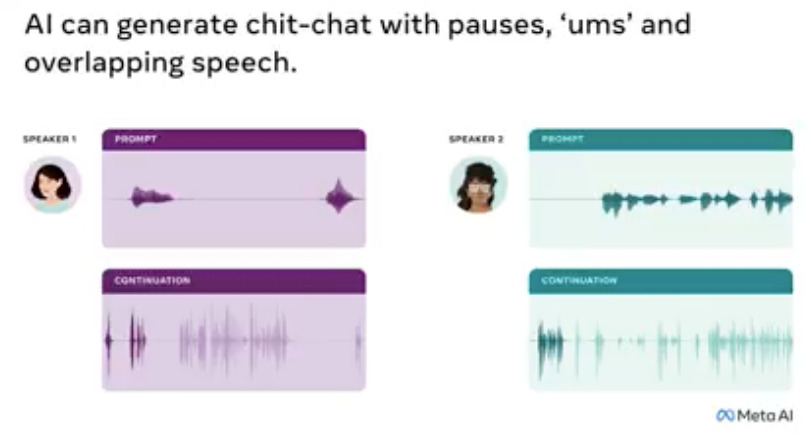
通过把一段双人对话编码成为两条离散token的流,研究人员接着设计了一个新的双塔Transformer结构(虽然以现在的眼光来看这个模型结构没得太多novel的地方了),其中每一条离散token流由其中的一个“Transformer塔”负责,同时,这两个塔也通过cross-attention机制在隐变量层面进行沟通。这个cross-attention机制保证了两个流之间信息的正确同步,以及可以生成口语对话中存在的交替,沉默以及重叠。
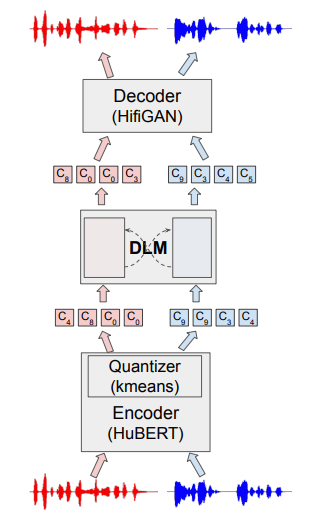
和现有的Speech Language Model一样,主要由三部分组成:一个对Speech进行编码的Encoder,一个可以token2token的language model,以及一个可以把token 还原成音频的Decoder。模型的架构见上图,一个离散编码器(HuBERT + kmeans)将语音对话的每个通道转换为一串离散token(c1,...cN)流,接着由一个对话语言模型(DLM)来自回归地生成token,然后使用解码器(HifiGAN)将其转换为音频。下面将具体介绍一下这几个部分的内容:
离散音素表征: 由于语音对话中包含随意的表达(像“嗯”这样的填充词)和各种在正式或朗读的语音中不会出现的非言语声音(例如,笑声),因此研究人员在对话数据集上对HuBERT模型进行了微调,以获得更好的语音表征。然而与现在广泛使用的codec模型不同的是,这里仅仅使用了K-means对HuBERT提取的嵌入向量进行离散化,从而得到离散token流。
对话模型:这是一个由带有cross-attention且共享权重的双塔Transformer以及一个token preditct head和一个duration predict head构成的。
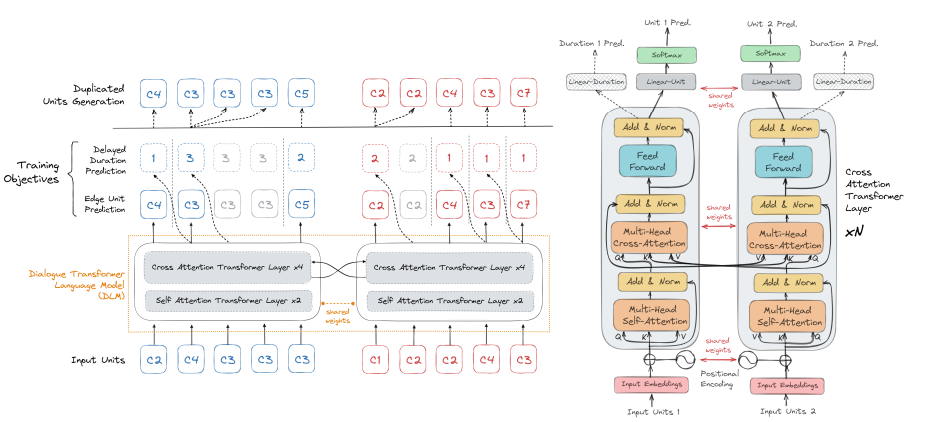
在对语音对话的不同通道进行建模时,研究人员希望语言模型不仅能从每个通道自身的历史中获取信息,还能从其他通道获取信息。因此,研究人员在多头自注意力块之后添加了一个额外的多头交叉注意力块,以在不同通道之间共享信息。在训练时,只会对其中一个Transformer的参数进行拟合。训练结束之后将模型参数克隆一份出来,得到一个共享权重的双塔transfomer模型。
和现在的LLM处理方式一样,通过在Tranformer的hidden值后介入一个头来预测生成的token。通过Cross-Entropy来拟合head的参数:
然而,与现代的LLM稍微不同的地方是,只有通过head预测的token和当前token不同的时候,模型才会进行生成的流程,而不是像现在通过repetition penalty和temperature等参数来更灵活控制生成解码的过程。 此外,除了用于预测音频token的head之外,还存在着一个额外的delayed duration prediction head,这个head的作用主要是对audio token的时长进行建模,预测连续的时长值,这个head的优化目标如下:
因此,模型整体的优化目标如下:
音频解码器:研究人员选用了HiFi-GAN作为音频解码器,同样地,这个解码器也在作者提供的数据集上面进行了微调,使得模型可以根据language model生成的token解码得到对应的语音。
With Text
遗憾的是,随着大模型时代的到来,上述工作却没有后续了。使用一个更大规模参数的Transformer模型在纯语音对话领域上效果如何仍然是未知。下面就来介绍一些基于LLM的语音对话方案。
GLM-4-Voice
智谱团队提出了GLM-4-Voice,这篇工作是首一个脱离了ASR和TTS的端到端语音对话大模型。此外,研究人员来探索了将之前LLM大规模数据预训练的成功经验应用到了语音语言大模型上的方案,提出的text to token模型有效的缓解了纯语音数量不足,无法像文本语料那样进行大规模预训练的问题。
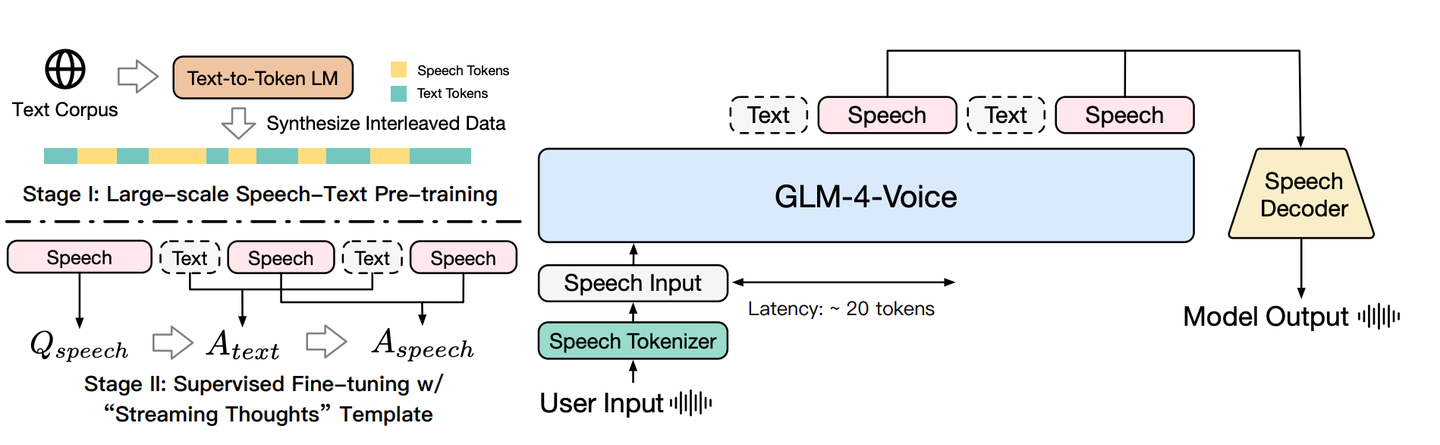
为了使得语音大模型能够像文本大模型一样在大规模语料数据上面进行预训练,研究人员构造了合成语音文本交叉数据。语音文本交叉数据指的是由语音和文本序列在词汇层面交错组成的token序列。例如:“今天是<Speech 24> <Speech 5> ... <Speech 128>天”。在语音文本交错数据上进行训练可以鼓励模型对齐语音和文本模态信息,从而有助于将基于文本的知识迁移到语音表征中。
研究人员提出了一种新颖且高效地使用现有文本数据集构建语音文本交叉数据的方法。该过程分为两个主要步骤:首先,训练一个文本到语音token的模型,该模型直接将文本转换成相应的语音token,从而免去了合成实际语音的必要,并显著提高了合成效率,使其成为一种实用且可扩展的大规模数据生成方法。接着,从现有的文本数据集中提取文本片段,并使用经过训练的文本到token模型转换成语音token。这一过程无需依靠对齐的语音文本配对数据集,即可高效且可扩展地创建语音文本交叉数据。
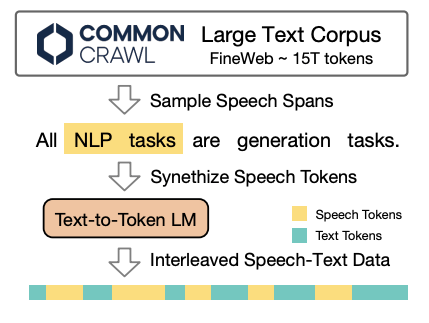
Text2token model: 研究人员基于标准的Transformer架构训练了一个1.5B的文本到token模型,以将文本转换成相应的语音token。为了准备训练数据,首先将文本到语音数据集中的音频转化为离散的语音token。然后训练文本到token模型,根据输入的文本预测这些语音token序列。优化目标是最小化基于相应文本输入的预测语音token的负对数似然:
模型训练过程包含两个阶段。在第一阶段,模型在合成的交叉数据上进行预训练,以学习文本和语音之间的对齐任务。在第二阶段,使用语音对话数据进行微调,使得模型能够处理语音交互。
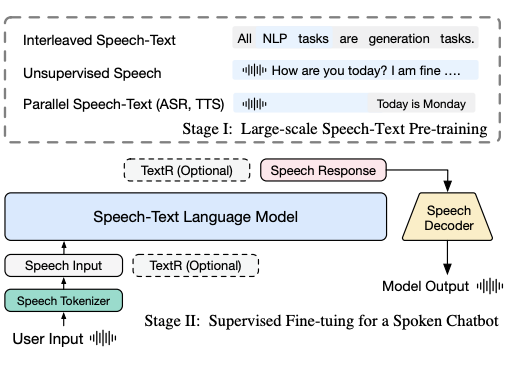
其中,预训练阶段的数据包含以下几个类型:
-
交错语音文本数据:正如前文所描述的,这些数据集有助于文本和语音之间的跨模态知识转移。
-
无监督文本数据:研究人员使用了与GLM类似的多样化语料库,包含来自网页、维基百科、书籍、代码和研究论文的10T token,以保持模型的语言理解能力。
-
无监督语音数据:使用Emilia管道,研究人员收集了700k小时的高质量英语和中文语音数据,通过DNSMOS P.835得分高于2.75进行筛选,确保语音输入的多样性和清晰度。
-
监督语音文本数据:这包括自动语音识别(ASR)和文本到语音(TTS)数据,教会模型学习语音和文本之间的双向关系。
而微调阶段则更加偏重于语音对话,主要包含以下两种类型:
-
多轮口语对话:这些对话主要源自基于文本的数据,经过仔细筛选以确保质量。排除了代码和与数学相关的内容,以专注于适合口语交流的会话材料。通过缩短冗长的文本以及过滤不适合口头表达的内容对回答进行了优化,并合成相应的语音token。
-
语音风格控制的口语对话:这一类别包含根据特定语音风格要求(如语速、情感或方言)定制的高质量多轮口语对话。
智谱算是第一个对语音对话场景交出答卷的国内团队了,虽然取得了不错的效果,但是很显然,它还是没有办法完全脱离text的内容,因此放到with text这一类里面。
LLAMA-OMNI
这是一篇基于Llama的Speech LLM工作,通过对Llama基座进行改造,使其可以支持语音对语音的对话。LLaMA-Omni 由一个预训练的Speech Encoder,用于模态对齐的Adaptor,LLM基座,以及一个可以流式解码的Decoder。LLaMA-Omni不需要把语音转录成文字作为模型的输入,并且能够以极低的延迟直接根据语音指令同时生成文本和语音回复。

用户的语音指令输入通过Speech Encoder进行编码,然后经过Speech Adaptor投影之后,再输入到大型语言模型基座中。基座模型直接从语音指令中解码出文本回复,而无需先将语音转录为文本。
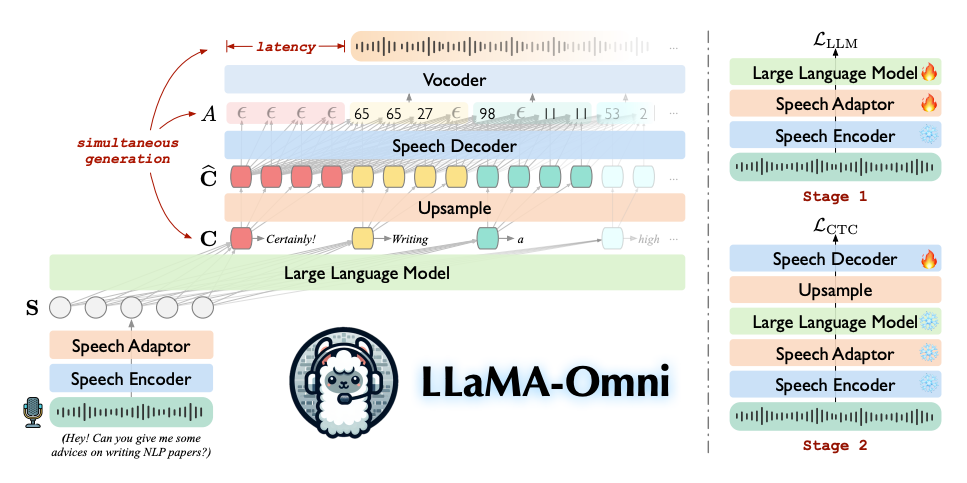
模型的整体架构见上图,下面将详细介绍这几个部分:
Speech Encoder:这一部分就直接采用的Whisper,因此不再过多赘述。
Speech Adaptor:为了使大型语言模型(LLM)能够理解输入的语音,研究人员引入了一个可训练的语音适配器 A,它将语音表示映射到 LLM 的嵌入空间中。研究人员首先对语音表示 H 进行下采样以减少序列长度。具体来说,对每 k 个连续的帧沿着特征维度进行拼接:
接下来,H' 通过一个两层的感知机,在线性层之间使用 ReLU 激活函数,从而得到最终的语音表示 S。上述过程可以形式化如下:
LLM基座:这里研究人员选用了Llama3 作为大语言模型基座,和文本模型的训练任务目标一样,只不过这里的token变成了Speech token:
Speech Decoder:假设LLM生成的token序列为,研究人员首先会对这个序列进行上采样,得到
,然后
在经过Decoer解码成为
,最后再将该序列送到vocoder中还原成音频。
同时研究人员还设计了两阶段的训练方法,用来训练这个模型。在第一阶段,研究人员直接训练模型根据语音指令生成文本回复的任务。具体来说,Speech Encoder被冻结,Speech Adaptor和大型语言模型则进行参数拟合训练。在这个阶段,Speech Decoder不参与训练。在第二阶段,则训练模型生成语音回复。在这个阶段,Speech Encoder、Speech Adaptor和 LLM 都被冻结,只有Speech Decoder进行参数拟合训练。
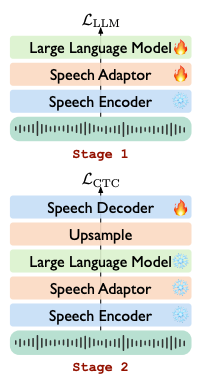
这篇工作的方法比较清晰,整体架构也比较简洁,是第一篇将Llama架构改造到适配成Speech2Speech模态的工作,但是仍然在输出端以及训练过程中借助了文本这个媒介,因此也被归类为with text这一类目里面。虽然取得了一定的效果,但是仍然不是最理想的Speech Language Model的形态,期待Meta官方能够在未来出一些支持speech的模型。
MinMo
这是一篇阿里通义实验室最新公布的一篇工作,由于并没有公布论文,因此没有办法分析里面的技术细节,只能大概从摘要里面进行分析。研究人员认为之前用于语音对话的多模态模型大致分为两类:Speech2Speech Model和Text Speech Aligned Model。Speech2Speech Model 使用单一框架同时对语音和文本进行理解和生成。然而,它们面临着语音和文本序列长度之间的巨大差异、语音预训练不足以及对文本大型语言模型知识的灾难性遗忘等挑战。而Text Speech Aligned Model在保持文本大型语言模型的能力方面更为成功。不足的是,现有的模型通常是在小规模的语音数据上进行训练的,在有限的一组语音任务上进行研究,并且缺乏对丰富和微妙的说话风格的指令跟随能力的系统探索。
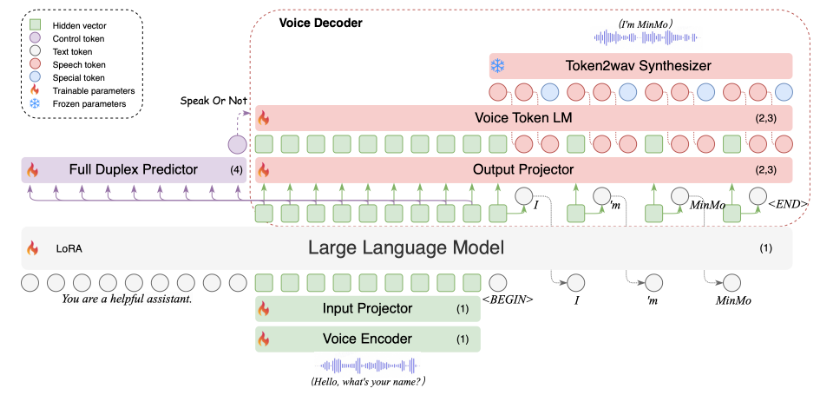
因此研究人员提出了MinMo,这是一个参数量大概在8B,用于语音交互任务的模型。研究人员解决了先前对齐多模态模型的主要挑战,通过语音到文本对齐、文本到语音对齐、语音到语音对齐和双工交互对齐的多个阶段训练任务,在 140 万小时的多样化语音数据和广泛的语音任务上训练 MinMo。经过多阶段训练后,MinMo 在语音理解和生成的各种基准测试中达到了最先进的性能,同时保持了文本大型语言模型的能力,并且还促进了全双工对话,即用户和系统之间的同时双向通信。
总结
从上文的梳理中可以发现,为了实现语音对语音的交互对话,研究人员给出了不同的答案。其中,dgslm是直接训练语音到语音模型的方案,但是遗憾的是,受限于数据量规模,无法用更大的模型进行实验,发挥大模型的能力。更多的工作则是希望借助于预训练LLM中已经学习到的知识,来迁移应用到SpeechLM中去,然而这些工作都还暂时没有摆脱text这一媒介,希望未来随着技术的发展,能够出现可以彻底摆脱text的Large Speech Language Model。
参考文献
Nguyen, Tu et al. “Generative Spoken Dialogue Language Modeling.” Transactions of the Association for Computational Linguistics 11 (2022): 250-266.
Zeng, Aohan et al. “GLM-4-Voice: Towards Intelligent and Human-Like End-to-End Spoken Chatbot.” ArXiv abs/2412.02612 (2024)
Fang, Qingkai et al. “LLaMA-Omni: Seamless Speech Interaction with Large Language Models.” ArXiv abs/2409.06666 (2024)
Chen, Qian et al. “MinMo: A Multimodal Large Language Model for Seamless Voice Interaction.” (2025).


















 1298
1298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









