



导读4D Gaussian Splatting 火了,但你知道它背后的“代价”吗?尽管这种技术能用“会呼吸的点云”高效重建动态3D场景,渲染又快又精致,但也付出了沉重的内存代价——几百万个高斯点,每个都挂着一堆参数,动辄几十G显存。本文作者另辟蹊径,提出一种极致压缩的4DGS框架:不仅把颜色属性从球谐系数砍到3个参数,还通过“共享预测器+变形场+熵正则”控制点数量,压缩比高达190倍!更关键的是,速度没降,质量还在,用更少的点,描绘更丰富的世界。可以说,这是继原始4DGS之后,这条技术路径上的又一次重要跃迁。
论文出处:ICCV2025 (Highlight)
论文标题:MEGA: Memory-Efficient 4D Gaussian Splatting for Dynamic Scenes
论文作者:Xinjie Zhang, Zhening Liu, Yifan Zhang, Xingtong Ge, Dailan He, Tongda Xu, Yan Wang, Zehong Lin, Shuicheng Yan, Jun Zhang
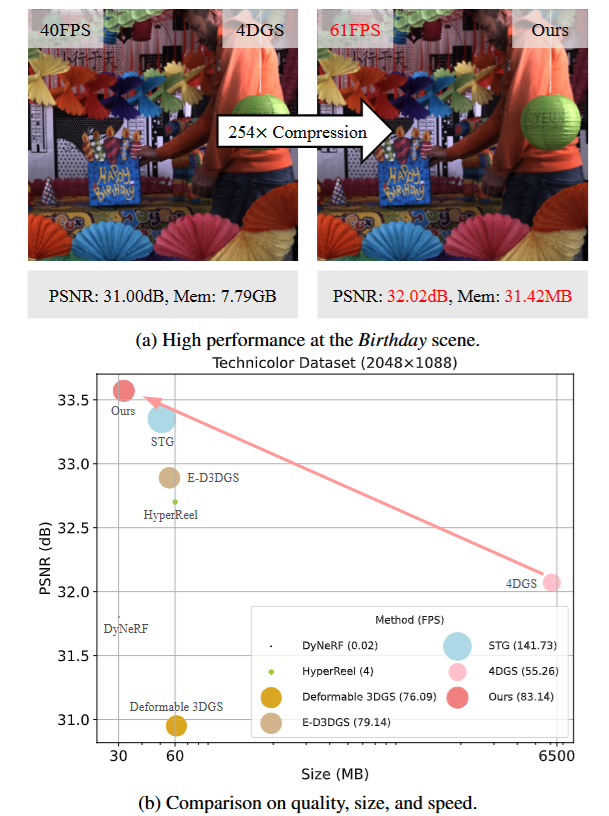
图1|作者提出的方法在保持与 4D Gaussian Splatting(4DGS)相当的真实感质量与实时渲染速度的同时,显著降低了存储需求。其核心思想是构建一种内存高效的 4D 高斯表示形式,并尽可能使用更少数量的高斯来精准拟合动态场景。图(a)中展示了在渲染 Birthday 场景时,4DGS 需要多达 1300 万个高斯点,而该方法仅需约 91 万个。图(b)则呈现了在 Technicolor 数据集上,与多个强有力的对比方法在渲染质量、存储空间和渲染速度等方面的量化对比结果

视角视频的动态场景重建,正成为计算机视觉与图形学中的研究热点,广泛应用于虚拟现实(VR)、增强现实(AR)以及3D内容生产领域。NeRF(神经辐射场)的出现使得从多视图图像合成新视角成为可能,但其基于光线上密集采样的特性导致渲染速度较慢,限制了实际应用。
近年来,3D Gaussian Splatting(3DGS) 技术提出了一种显式的3D高斯表示配合可微分的光栅化渲染方式,大幅提升了渲染速度。基于此,4D Gaussian Splatting(4DGS) 应运而生,将时间维度纳入高斯表示中,将一个动态场景建模为一个4D的时空高斯超柱体。在任意时间戳下,4DGS会将其切片为3D高斯点,再通过不透明度过滤来保留当前可见部分,实现对出现/消失物体的建模,最终通过光栅化方式进行快速渲染。
然而,4DGS 的一个关键瓶颈是其巨大的内存需求。以 Birthday 场景为例,需约 1300 万个高斯点,单个场景占用约 7.79GB 存储,严重限制其在边缘设备(如AR/VR头显)上的部署。为解决这个问题,本文提出了一种面向内存优化的4D Gaussian Splatting 框架(MEGA)。
本方法主要创新包括:
颜色压缩机制:
将每个高斯的颜色属性拆解为:
● 一个仅需3个参数的DC(直流)颜色分量;
● 一个AC(交流)颜色预测器,可根据时间和视角动态预测颜色变化。该预测器为一个轻量三层MLP。
这一设计避免了原始方法中多达144维的球谐系数表示,实现约8倍压缩。
熵约束的高斯变形机制:
为提升每个高斯的有效覆盖范围,作者引入了一个基于时间和视角的高斯形变场,可建模高斯的运动与转瞬变化。同时,加入基于空间不透明度的熵损失,将高斯点的不透明度推向二值状态,从而剔除对最终渲染贡献较小的高斯,减少总数量并提升利用率。
轻量化存储:
使用 16位浮点数(FP16) 存储配合 zip delta 压缩技术,实现进一步压缩。
综合上述方法,作者在 Technicolor 和 Neural 3D Video 两个数据集上分别实现了 约190倍和125倍的存储压缩率,同时保持了与原始4DGS方法相当的渲染速度与场景重建质量,成为该领域中的新一代轻量化标准。
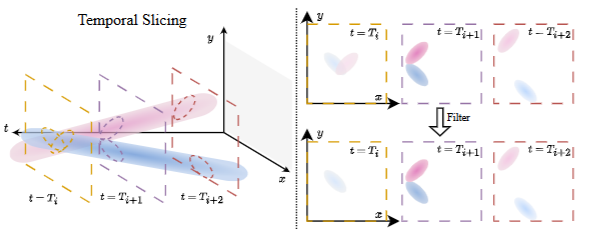
图2|图示展示了 4D Gaussian Splatting 中的时间切片过程,为简洁起见省略了 z 轴。一个 4D 高斯可以被看作是 4D 空间中的超柱体。当给定特定时间点后,系统会从该超柱体中提取出对应的 3D 高斯椭球。椭球的颜色深度表示其时间不透明度。对于那些时间不透明度低于预设阈值的 3D 高斯椭球,将被排除在渲染场景之外

本研究的方法基于先前提出的 4D Gaussian Splatting 技术。这项技术通过可微的光栅化方法,优化一组高维高斯分布,进而高效表达动态场景,并实现高质量的新视角图像实时渲染。
每一个 4D 高斯实体包含以下几个属性:
● 空间和时间上的四维中心位置(x、y、z 及时间 t)。
● 描述旋转的四元数(分别为左旋与右旋两个向量)。
● 对应四个维度的缩放因子。
● 用于建模颜色变化的高维球谐系数,用来表达时间和视角变化下的 RGB 颜色。
● 空间不透明度值(介于0到1之间)。
在渲染任意时间点的图像时,系统会将每个 4D 高斯“切片”为一个时间相关的三维高斯。这一切片过程包含:
● 根据当前时间,对高斯的位置和密度进行调节,使其只在与其中心时间接近的区域内有效;
● 每个高斯的中心位置随时间线性移动,其密度也随时间距离呈现高峰衰减的特性;
接着,这些切片后的高斯会投影到图像平面,并通过可微光栅化完成最终图像渲染。
该方法虽可合成高质量视图,但为了完整表达场景,需要大量高斯点,这使得存储需求高、压缩困难。因此,作者提出了内存优化的增强版本:MEGA。
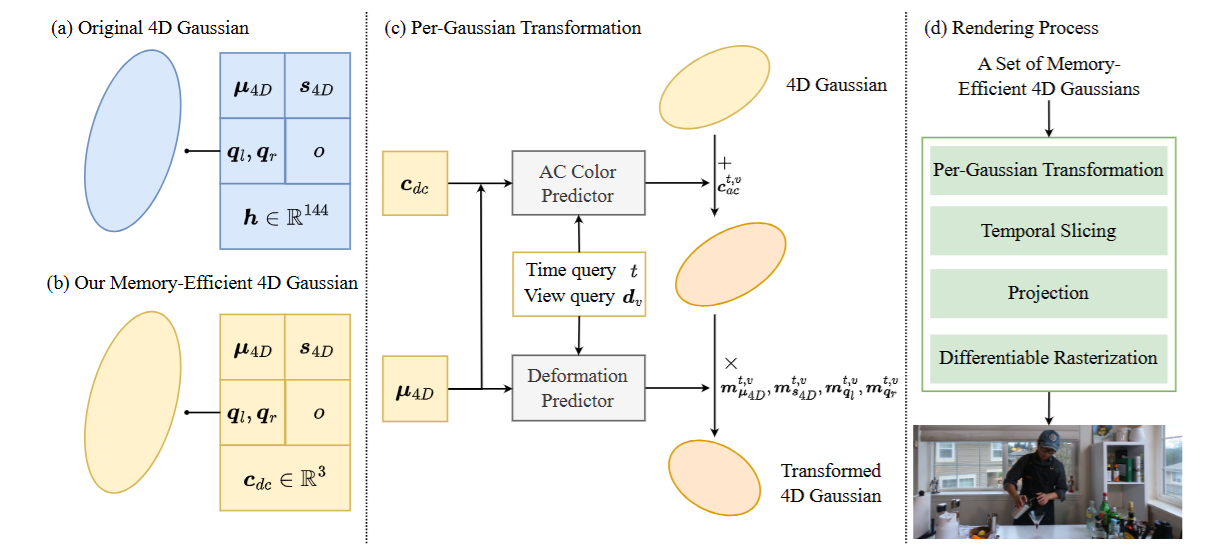
图3|全文方法总览
Memory-Efficient 4D Gaussian Splatting
总体思路
如图3所示,作者设计了一种轻量化的4D高斯框架,从两个方面着手减小模型大小:
● 一是减少每个高斯的存储参数;
● 二是通过几何变形扩展高斯的“作用范围”,以更少的高斯数量表达复杂动态。
具体地,在渲染前,每个高斯都会根据具体时间和视角进行颜色预测与几何变形。这一变换不仅提高了每个高斯在渲染中的参与度,也显著降低了总体高斯数量需求。
渲染过程仍遵循原始 4DGS 的流程,包括时间切片、投影、光栅化等步骤。
一)轻量化的颜色表示:DC-AC 表达方法
在标准4DGS中,用于表达颜色变化的球谐系数占据了大部分存储空间(约占参数总量的 90%)。尽管已有工作尝试用神经场代替球谐系数,但实验显示该方式会显著损失渲染质量。
因此,本文提出了一种混合颜色建模方式:将颜色属性分为两部分:
● DC分量:为每个高斯分配一个固定颜色(仅包含3个RGB值);
● AC分量:使用一个轻量多层感知机(MLP)作为预测器,基于高斯位置、观察视角、时间与DC颜色来预测颜色变化。
这种方式保留了个体颜色特征(DC),同时用神经网络补充时间和视角变化(AC),在保证渲染质量的同时,将存储开销降低至原始方案的 1/8。
二)限制熵的高斯几何变形机制
标准4DGS默认高斯的运动为线性,旋转和缩放保持不变。这种近似虽然简化了计算,但难以表达复杂非线性变化,因而需要引入大量冗余高斯才能补足表达能力。
同时,由于时间衰减机制的限制,在每一帧图像中,往往只有约6%的高斯真正参与渲染,导致资源浪费严重。
为此,作者引入了一个时间-视角相关的几何变形预测器。它基于:高斯中心位置、当前视角方向、当前时间,对每个高斯的中心位置、尺度因子、旋转参数进行变形预测。这样,每个高斯的“活动范围”得以扩展,避免因作用范围过窄而冗余生成多个相似高斯。
此外,为了防止在优化过程中高斯数量膨胀,作者还引入了一个基于空间不透明度的熵约束损失,使得每个高斯的空间不透明度趋向于0或1(即要么完全参与渲染,要么完全被剔除)。训练时,系统定期剪除低影响高斯,从而维持高效表达与紧凑存储。
实验显示,在该机制下,每帧图像中参与渲染的高斯比例可从原来的不到50%提升到75%左右,表达效率显著增强。
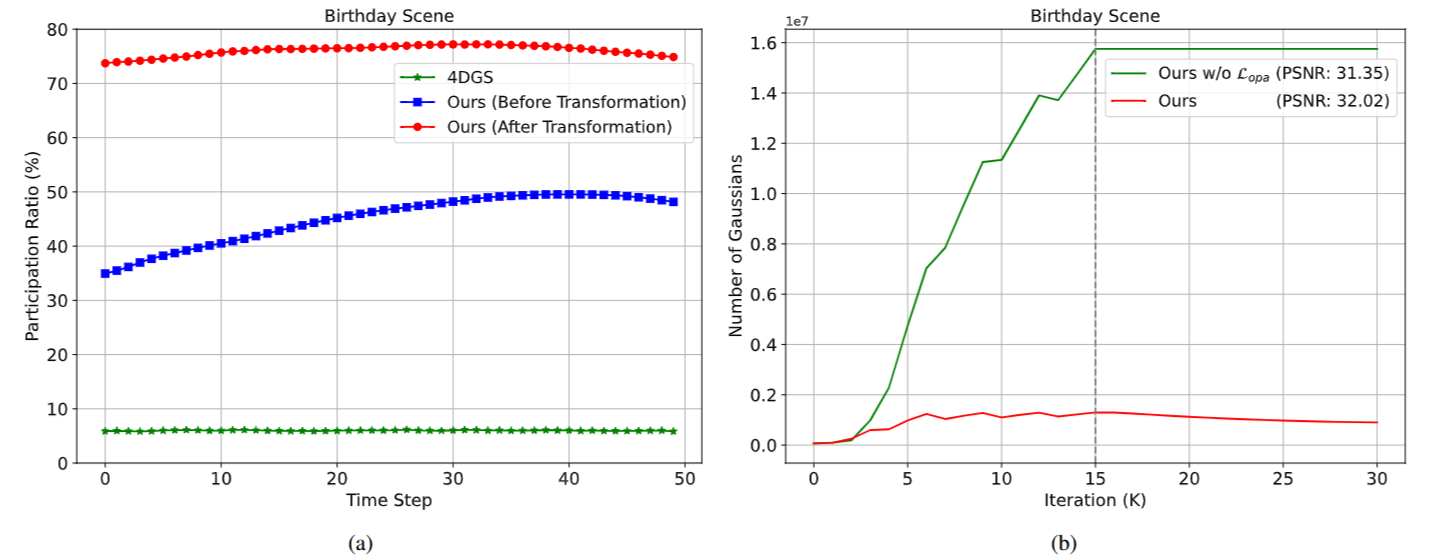
图4|(a) 在不同时间步下参与渲染的 Gaussians 在 Birthday 场景中的比例。蓝色曲线表示在不使用每个 Gaussian 的变换操作时,MEGA 模型中实际参与渲染的 Gaussians 数量。(b) 训练过程中,在 Birthday 场景中参与渲染的 Gaussians 数量随时间变化的可视化结果。
训练与压缩流程
损失函数设计
训练过程中采用以下三种损失项:
● 图像重建损失:包括L1损失与结构相似性(SSIM)损失,用于衡量渲染图像与真实图像之间的差异;
● 不透明度正则项:即前文提到的熵约束损失,鼓励不透明度收敛到极端值,从而便于剪枝。
● 三者加权组合形成总损失,其中各项的权重通过超参数控制。
模型压缩策略
在训练阶段使用半精度(FP16)参数格式,优化完成后将模型存储为16位浮点格式,并应用 zip delta 无损压缩算法,进一步压缩存储空间,平均可再减小约10%。
整体而言,该方法以“压缩颜色表示 + 提高几何表达能力 + 剪枝冗余点 + 压缩格式存储”为核心,系统性解决了4DGS在大规模动态重建任务中“质量与体积难兼得”的问题

作者在两个真实世界的动态场景数据集上评估了MEGA的性能:
● Technicolor Light Field Dataset:多视角时间同步视频数据,采用5个典型场景(如Birthday、Painter等),图像分辨率为2048×1088。
● Neural 3D Video Dataset(Neu3DV):包含6个高分辨率室内动态场景,场景中包含多个物体的复杂运动,渲染分辨率为原始尺寸的一半。
评估指标包括:
● PSNR(峰值信噪比):衡量像素级误差;
● DSSIM(结构相似性反指标):衡量结构差异,提供两个版本(DSSIM1 / DSSIM2)用于公平对比;
● LPIPS(感知相似度):基于神经网络的高层视觉质量评估;
● FPS(渲染帧率):衡量渲染速度;
● 存储空间(Storage):衡量模型压缩比。
对比方法涵盖:
原始的 4DGS 方法;
● 多种 NeRF 系列代表方法(如 DyNeRF、HyperReel、MixVoxels);
● 高斯渲染体系的最新扩展(如 Dynamic 3DGS、STG、E-D3DGS 等)
主要实验结果
Technicolor 数据集(图5)
在五个动态场景中,MEGA 在多项指标上显著超越基线方法:
相较于原始 4DGS:
● PSNR 提升 1.2 dB;
● DSSIM 和 LPIPS 分别下降 0.006 和 0.018,图像结构更清晰;
● 存储需求减少 190 倍,渲染速度提升 50%。
相较于 NeRF 系方法 HyperReel:
● PSNR 提升约 0.87 dB;
● 渲染速度快 20 倍,存储空间减半。
● 相较于最强高斯方法 STG:
● PSNR 提高 0.22 dB,质量更高;存储需求再降 40%。
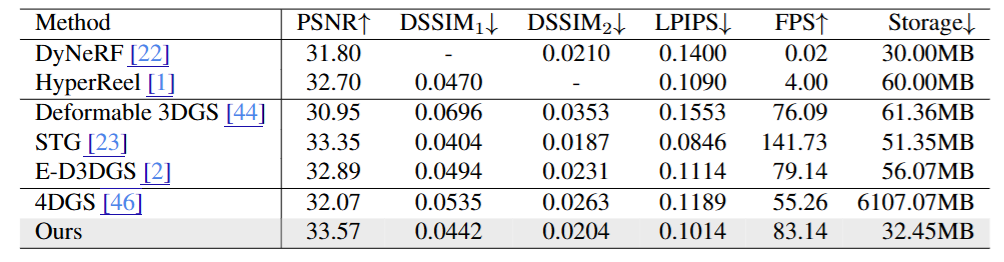
图5|Technicolor数据集定量实验结果
图6中的定性可视化也表明,MEGA能更清晰地保留场景细节,避免伪影产生。

图6|渲染定性实验结果
Neu3DV 数据集(图7)
MEGA 在六个更复杂的动态场景中同样展现强大表现:
相比 4DGS,平均压缩比高达 125×;
● 相较于最优 NeRF 系方法 MixVoxels:
● 存储降低 20 倍;
● 推理速度提升 16 倍;
● 渲染质量保持一致或略优。
该结果显示 MEGA 在高压缩比下依然具有强大的视觉还原能力,适合复杂动态场景部署。
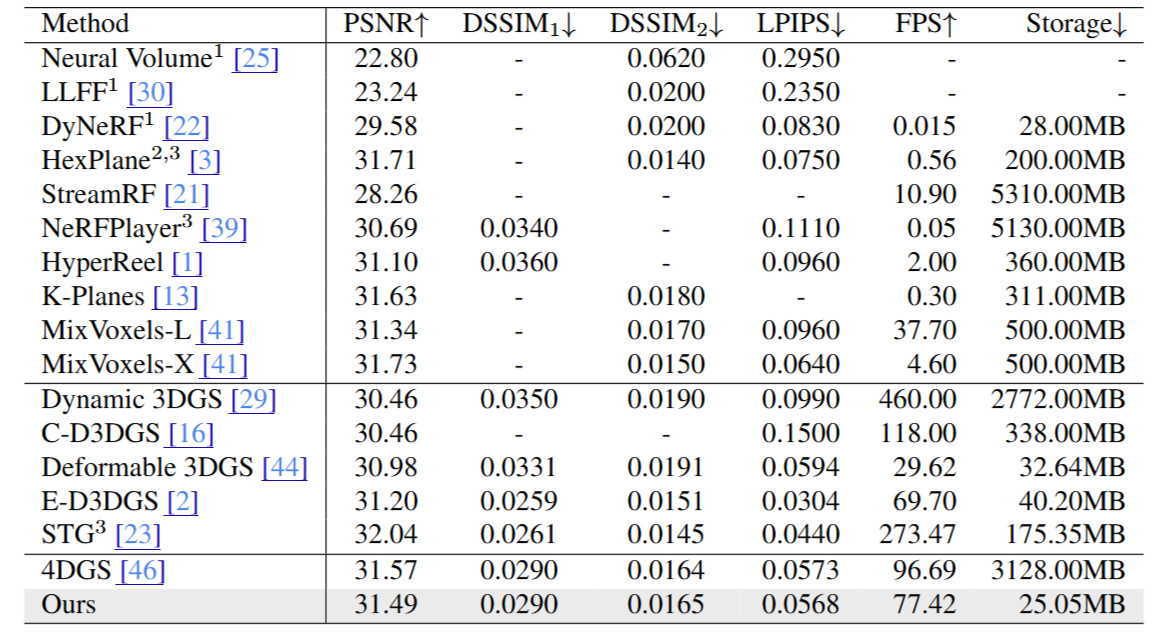
图7|Neu3DV定量实验结果
消融实验
为了分析不同模块的贡献,作者在 Technicolor 和 Neu3DV 中的代表场景上开展了消融实验,得出以下关键结论:
1. DC-AC颜色建模模块
替代球谐系数后,若仅使用 grid-based 网络表示颜色,尽管参数减少 10 倍,但渲染质量大幅下降;采用 MEGA 的 DC-AC 结构后,既保持压缩比,又显著优于 grid 方法,几乎恢复原4DGS 的渲染质量;原因在于 DC 保留静态颜色,AC 预测动态变化,两者协同兼顾细节与变化。
2. 高斯变形与熵约束机制
● 仅使用高斯变形时,尽管表达力增强,但高斯数量会明显增加;
● 仅使用不透明度熵损失,则高斯作用范围受限,表达不足;
两者结合后,即能维持高表达质量,又能大幅减少高斯数量,验证了压缩机制的核心贡献。
小结
MEGA 在保持与原始4DGS近似的图像质量的同时,大幅压缩模型大小与加速渲染效率,在两个动态场景数据集上均优于现有 NeRF 和高斯方法,展现出极强的实用性和可部署性。特别是在资源受限或需要实时渲染的应用场景中,MEGA提供了当前最具性价比的解决方案。
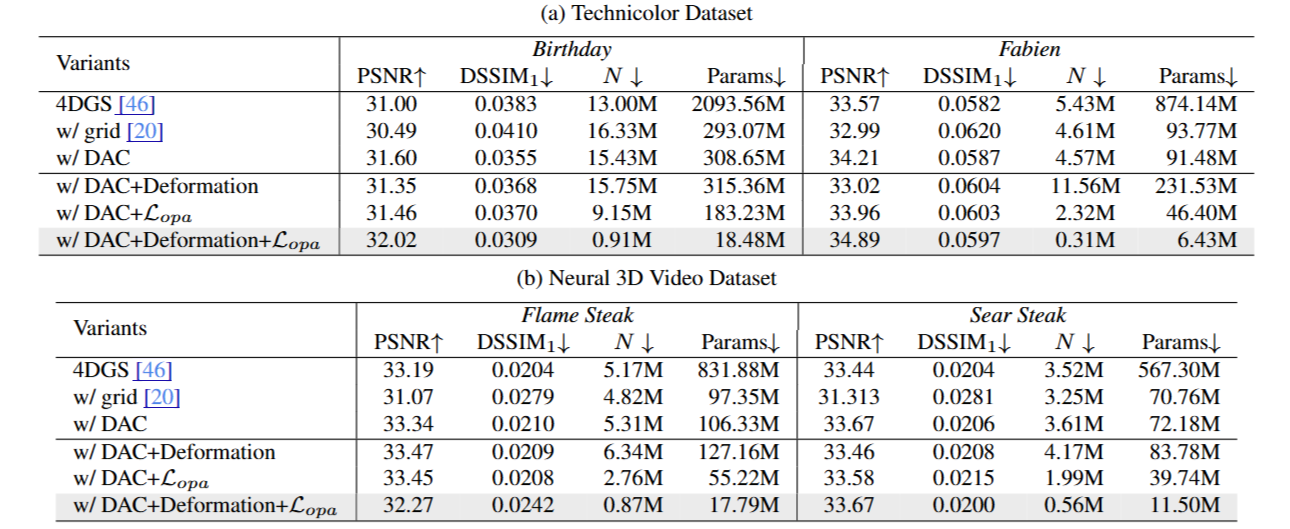
图8|消融实验结果

在本研究中,作者提出了一种面向 4D 高斯渲染的全新记忆优化框架。该方法通过将颜色属性拆解为每个高斯点的直流分量(DC)与一个共享的、轻量级的交流颜色预测器(AC),显著压缩了每个高斯点所需的参数量,同时不影响渲染性能。
为了进一步减少 4D 高斯之间的冗余,作者引入了熵约束的高斯变形机制,有效扩展了每个高斯的作用范围,从而提高了其利用率。这使得模型能够以更少的高斯点完成高质量的动态场景重建。
大量实验结果验证了该方法的有效性——在保持重建质量和实时渲染速度的前提下,存储需求相比原始 4DGS 实现了 百倍以上的压缩。该成果在高性能、轻量化和实时渲染三个维度上树立了新的基准。

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









