



论文标题:
End-to-End Autonomous Driving without Costly Modularization and 3D Manual Annotation
论文作者:
Mingzhe Guo, Zhipeng Zhang, Yuan He, Ke Wang, Liping Jing
导读:
本文提出了一个无监督的任务,以舍弃端到端自动驾驶中对3D手动标注的要求,从而可以将训练数据扩展到数十亿级别而不会产生任何标注过载问题。此外,本文引入了一种新颖的自监督方向感知学习策略,以最大限度地提高不同增强视图下预测轨迹的一致性,从而增强了转向场景中的规划稳健性。©️【深蓝AI】编译
1.摘要
本文提出了一种基于视觉的端到端自动驾驶(E2EAD)方法----UAD,它在nuScenes中获得了最佳的开环评估性能,同时在CARLA中表现出稳健的闭环驾驶质量。作者的动机源于这样的观察:当前的E2EAD模型仍然模仿典型驾驶堆栈中的模块化架构,即精心设计了监督感知和预测子任务,为定向规划提供环境信息。虽然取得了突破性的进展,但这种设计也存在一些缺点:
1)前面的子任务需要大量高质量的3D标注作为监督,这对扩展训练数据构成了重大障碍;
2)每个子模块在训练和推理中都需要大量的计算开销。
为此,本文提出了UAD,这是一个带有无监督代理的E2EAD框架,用于解决这些问题。首先,作者设计了一个新颖的角度感知预案(Angular Perception Pretext)来消除标注要求。该前置模型通过预测角度方向的空间物体性和时间动态来对驾驶场景进行建模,无需人工标注。其次,提出了一种自监督训练策略,该策略学习不同增强视图下预测轨迹的一致性,以增强转向场景中的规划鲁棒性。本文的UAD在nuScenes的平均碰撞率上比UniAD提高了38.7%,在CARLA的Town05 Long基准测试中的驾驶得分上比VAD高出41.32分。此外,所提出的方法仅消耗UniAD 44.3%的训练资源,推理速度提高了3.4倍。本文的创新设计不仅首次展示了与监督同行相比无可争议的性能优势,而且在数据、训练和推理方面也享有前所未有的效率。
2.引文
近几十年来,自动驾驶取得了突破性成就,而端到端范式是其中一个代表性分支,旨在将感知、预测和规划任务整合到一个统一的框架中。端到端自动驾驶的最新进展极大地激发了研究人员的兴趣,然而,手工制作且资源密集型的感知和预测监督子任务,此前已在环境建模中证明了其实用性 ,如图1所示。
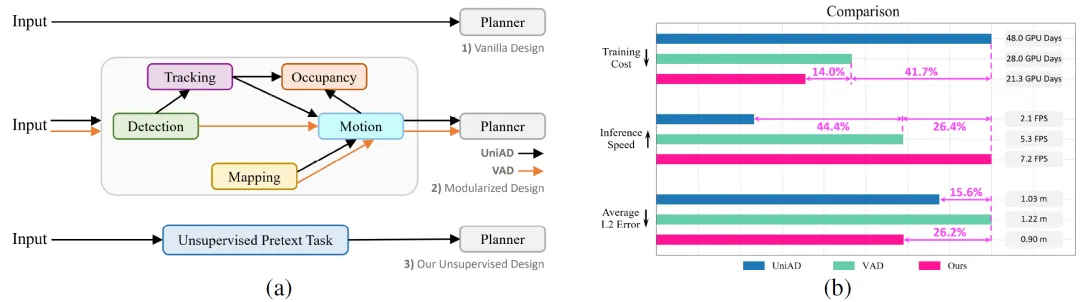
图1|端到端自动驾驶算法一般范式©️【深蓝AI】编译
那么,从最近的端到端自动驾驶进展中可以获得了什么见解呢?
作者注意到,其中最具启发性的创新之一在于使用了基于Transformer的模块,其中查询充当一条连接线,无缝连接各种任务。此外,环境建模能力也得到了显着提升,这主要是由于监督子任务的复杂交互。
然而,这样的模式也是有不足的一面。与原始设计(见图1a)相比,模块化方法会产生不可避免的计算和标注开销。如图1b所示,最近的方法UniAD的训练需要48个GPU训练一天才能完成,而运行速度仅为2.1帧/秒(FPS)。此外,现有感知和预测设计中的模块需要大量高质量的标注数据。人工标注的开销严重阻碍了这种具有监督子任务以利用海量数据的模块化方法的可扩展性。正如大模型所证明的那样,扩大数据量是将模型能力提升到新水平的关键。因此,本文提出了一个问题:在减轻对3D标注的依赖的同时,设计一个高效、强大的E2EAD框架是否可行?
在本文中,作者提出一种创新的端到端自动驾驶(UAD)无监督任务来证明上述提出方案的可行性,该任务旨在有效地对环境进行建模。其中角度感知预案(Angular Perception Pretext)任务包括一个角度感知模块,通过预测BEV空间中每个扇区区域的客观性来学习空间信息,以及一个最优角度解码器,通过预测无法访问的未来状态来吸收时间知识。引入的角度查询将两个模块链接为一个整体任务来感知驾驶场景。值得注意的是,本文的方法通过完全消除感知和预测的标注要求而脱颖而出。对于具有复杂监督模块化的当前方法,这种数据效率是无法实现的。通过将现成的开放集检测器的2D感兴趣区域(ROI)投影到BEV空间,可以获得学习空间物体性的监督。在利用公开可用的开放集2D检测器(该检测器已通过来自其他域(例如COCO)的手动标注进行预训练)的同时,本文避免了在作者的范式和目标域(例如nuScenes和CARLA)内使用任何额外的3D标注的需要,从而创建了一个实用的无监督设定。此外,本文引入了一种自监督的方向感知学习策略来训练规划模型。具体而言,视觉观察通过不同的旋转角度得到增强,并将一致性损失应用于预测以实现稳健的规划。在没有附加功能的情况下,所提出的UAD在nuScenes平均L2误差方面比UniAD好0.13米,在CARLA路线完成分数方面超过VAD 9.92分。这种前所未有的性能提升是通过3.4倍的推理速度、仅44.3%的UniAD训练预算和零标注实现的,如图1b所示。
3.相关工作
3.1 端到端自动驾驶
端到端自动驾驶可以追溯到1988年,当时卡内基梅隆大学提出的ALVINN 可以成功导航超过400米的车辆。此后,为了提高端到端自动驾驶的鲁棒性,一系列现代方法(如NEAT、P3、MP3、ST-P3)引入了更专用的模块化设计,集成了高清地图等辅助信息以及鸟瞰图(BEV)分割等附加任务。最近,采用Transfromer和视觉占用预测等先进架构,UniAD和VAD在开环评估中表现出色。在这项工作中,作者创新性地提出了另一条路径,无需任何人工标注,而不是集成复杂的监督模块子任务,如3D边界框和点云类别,就可以实现比最新技术更优异的性能。

图2|UAD模型架构©️【深蓝AI】编译
3.2 世界模型
为了理解环境中的动态变化,游戏和机器人领域的研究人员提出了各种世界模型。最近,自动驾驶社区引入了更安全的可操纵世界模型。MILE将环境视为高级嵌入,并倾向于通过历史观察来预测其未来状态。Drive-WM提出了一个框架,将世界模型与现有的端到端方法相结合,以提高规划的稳健性。在这项工作中,本文提出了一种自回归机制,针对我们的无监督借口进行量身定制,以捕捉每个扇区内的角度时间动态。
4.方法
4.1 总览
如图2所示,作者的UAD框架由两个基本组件组成:
1)角度感知预案,旨在以无监督的方式将E2EAD从复杂的模块化任务中解放出来;
2)方向感知规划,学习增强轨迹的自监督一致性。
具体来说,UAD首先用角度感知预案对驾驶环境进行建模。通过估计BEV空间内每个扇区的客观性来获取空间知识。引入角度查询(每个查询负责一个扇区)来提取特征并预测客观性。监督标签是通过将2D感兴趣区域(ROI)投影到BEV空间生成的,这些区域通过可用的开放集检测器GroundingDINO进行预测。这种方式不仅消除了3D标注要求,而且大大减少了训练预算。此外,由于驾驶本质上是一个动态和连续的过程,因此作者提出了一个最优角度解码器来编码时间知识。最优角度解码器可以看作是一个增强世界模型,能够自动回归预测未来状态。
随后,引入方向感知规划来训练规划模块。原始BEV特征通过不同的旋转角度进行增强,产生旋转的BEV表示和本体轨迹。本文将自监督一致性损失应用于每个增强视图的预测轨迹,这有望提高方向变化和输入噪声的鲁棒性。学习策略也可以看作是一种为端到端自动驾驶定制的新型数据增强技术,增强了轨迹分布的多样性。

图3|角度感知预案和最优角度解码器©️【深蓝AI】编译
4.2 角度感知预案
· 空间表示学习
作者的模型尝试通过预测BEV空间内每个扇区的客观性来获取驾驶场景的空间知识。特别的,以多视图像为输入 { I i ∈ R H i × W i × 3 } \{\mathbf{I}_{\rm i}\!\in\!\mathbb{R}^{H_{\rm i}\!\times W_{\rm i}\!\times 3}\} {Ii∈RHi×Wi×3},BEV编码器首先将视觉信息提取到BEV特征中 F b ∈ R H b × W b × C {\bf F}_{\rm b}\!\in\!\mathbb{R}^{H_{\rm b}\!\times W_{\rm b}\!\times C} Fb∈RHb×Wb×C。然后, F b {\bf F}_{\rm b} Fb以固定的角度被均匀划分为 K K K个扇区,并且这些扇区是以本体车辆为中心,划分后每个扇区包含BEV空间中的多个特征点。将扇区中的特征表示为 f ∈ R N × C {\bf f}\!\in\!\mathbb{R}^{N\!\times\!C} f∈RN×C,其中 N N N是所有扇区中特征点的最大数量,进一步得出BEV特征 F a ∈ R K × N × C {\bf F}_{\rm a}\!\in\!\mathbb{R}^{K\!\times\!N\!\times\!C} Fa∈RK×N×C,对于少于 N N N个特征点的扇区使用零填充。
那么,为什么要将矩形BEV特征划分为角度格式呢?根本原因是,在没有深度信息的情况下,2D图像中ROI对应的BEV空间区域是一个扇区。如图 3a 所示,通过将3D采样点投影到图像上并验证它们在2D ROI中的存在,生成一个BEV对象掩码 M ∈ R H b × W b × 1 {\bf M}\!\in\!\mathbb{R}^{H_{\rm b}\!\times W_{\rm b}\!\times\!1} M∈RHb×Wb×1,表示BEV空间中的对象。具体而言,落在2D ROI内的采样点设置为1,而其他采样点设置为0。值得注意的是,正扇区在BEV空间中分布不规则且稀疏。为了使对象性标签更紧凑,与BEV特征划分类似,作者将 M M M均匀分成 K K K个相等的部分。与正扇区重叠的部分被分配1,构成角度对象标注 Y o b j ∈ R K × 1 {\bf Y}_{\rm obj}\!\in\!\mathbb{R}^{K\!\times\!1} Yobj∈RK×1。由于开放集检测的快速发展,现在可以通过将预定义的提示(例如车辆、行人和障碍物)输入到像GroundingDINO这样的2D开放集检测器来方便地获取输入多视图图像的2D ROI,这种设计是降低标注成本和扩大数据集的关键。
为了预测每个扇区的目标得分,作者将角度查询定义为 Q a ∈ R K × C {\bf Q}_{\rm a}\!\in\!\mathbb{R}^{K\!\times\!C} Qa∈RK×C,用来对 F a {\bf F}_{\rm a} Fa求和。每个在 Q a {\bf Q}_{\rm a} Qa角度查询 q a ∈ R 1 × C {\bf q}_{\rm a}\!\in\!\mathbb{R}^{1\!\times\!C} qa∈R1×C将会和对应的 f f f交互得到交叉注意力:
q a = C r o s s A t t e n t i o n ( q a , f ) {\bf q}_{\rm a} = {\rm CrossAttention}({\bf q}_{\rm a}, \, {\bf f}) qa=CrossAttention(qa,f)
最后,作者用一个线性层将 Q a {\bf Q}_{\rm a} Qa映射到对象分数 P a ∈ R K × 1 {\bf P}_{\rm a}\!\in\!\mathbb{R}^{K \times 1} Pa∈RK×1,该线性层由 Y o b j {\bf Y}_{\rm obj} Yobj以二元交叉熵损失(表示为 L s p a t \mathcal{L}_{\rm spat} Lspat)进行监督。
时间表征学习
作者建议使用最优角度解码器来捕捉驾驶场景的时间信息。如图3b所示,解码器以类似于世界模型的方式自回归学习每个扇区的过渡动态。假设规划模块预测未来 T T T步骤的轨迹,则梦境解码器相应地包含 T T T层,其中每个层根据学习到的时间动态更新输入角度查询 Q a {\bf Q}_{\rm a} Qa和角度BEV特征 F a {\bf F}_{\rm a} Fa。在步骤 t t t,查询 Q a t − 1 {\bf Q}_{\rm a}^{t-1} Qat−1首先使用门控循环单元(GRU)从观察特征 F a t {\bf F}_{\rm a}^{\rm t} Fat掌握环境动态,从而生成 Q a t {\bf Q}_{\rm a}^{t} Qat(隐藏状态):
Q a t = G R U ( Q a t − 1 , F a t ) {\bf Q}_{\rm a}^{t} = {\rm GRU}({\bf Q}_{\rm a}^{t-1}, {\bf F}_{\rm a}^{t}) Qat=GRU(Qat−1,Fat)
在以前的世界模型中,隐藏状态 Q Q Q仅用于感知观察到的场景。因此,GRU迭代在 t t t处结束,最终观察结果为 F a t {\bf F}_{\rm a}^{\rm t} Fat。在作者的框架中, Q Q Q还用于预测未来的本体轨迹。然而,未来的观察,例如 F a t + 1 {\bf F}_{\rm a}^{\rm t+1} Fat+1,是不可用的,因为世界模型仅用于通过当前观察来预测未来。为了获得 Q a t + 1 {\bf Q}_{\rm a}^{t+1} Qat+1,我们首先建议更新 F a t {\bf F}_{\rm a}^{\rm t} Fat以提供伪观察 F ^ a t + 1 {\bf \hat{F}}_{\rm a}^{t+1} F^at+1:
F ^ a t + 1 = C r o s s A t t e n t i o n ( F a t , Q a t ) {\bf \hat{F}}_{\rm a}^{t+1} = {\rm CrossAttention}({\bf F}_{\rm a}^{t}, \, {\bf Q}_{\rm a}^{t}) F^at+1=CrossAttention(Fat,Qat)
然后可以利用上述公式以及 F ^ a t + 1 {\bf \hat{F}}_{\rm a}^{t+1} F^at+1和 Q a t {\bf Q}_{\rm a}^{t} Qat的输入生成 Q a t + 1 {\bf Q}_{\rm a}^{t+1} Qat+1。
遵循世界模型中的损失函数设计,作者分别将 Q a t − 1 {\bf Q}_{\rm a}^{t-1} Qat−1和 Q a t {\bf Q}_{\rm a}^{t} Qat映射到分布 { μ a t − 1 , σ a t − 1 ∈ R K × C } \{ {\bf \mu}_{\rm a}^{t-1},{\bf \sigma}_{\rm a}^{t-1}\!\in\!\mathbb{R}^{K \times C} \} {μat−1,σat−1∈RK×C}和 { μ a t , σ a t ∈ R K × C } \{ {\bf \mu}_{\rm a}^{t},{\bf \sigma}_{\rm a}^{t} \in \mathbb{R}^{K \times C} \} {μat,σat∈RK×C},然后最小化它们的KL散度。针对来自于 Q a t − 1 {\bf Q}_{\rm a}^{t-1} Qat−1的先验分布,它被看作没有观测下的未来动态预测。相比之下,来自于 Q a t {\bf Q}_{\rm a}^{t} Qat的后验分布表示带有观测 F a t {\bf F}_{\rm a}^{\rm t} Fat的未来动态预测。两个分布间的KL散度衡量设想的未来知识和真实未来知识之间的差距。作者希望提高针对长距离驾驶安全的未来预测性能,可以通过优化理想损失 L d r m \mathcal{L}_{\rm drm} Ldrm来实现:
L d r m = K L ( { μ a t , σ a t } ∣ ∣ { μ a t − 1 , σ a t − 1 } ) \mathcal{L}_{\rm drm} = {\rm KL}(\{ {\bf \mu}_{\rm a}^{t},{\bf \sigma}_{\rm a}^{t}\} || \{{\bf \mu}_{\rm a}^{t-1},{\bf \sigma}_{\rm a}^{t-1}\}) Ldrm=KL({μat,σat}∣∣{μat−1,σat−1})

图4|方向感知学习策略示意图©️【深蓝AI】编译
4.3 方向感知规划
· 规划头
角度感知预案的输出包含一组角度查询 { Q a t ( t = 1 , . . . , T ) } \{{\bf Q}_{\rm a}^{t} \,(t=1,...,T)\} {Qat(t=1,...,T)}。对于规划任务,作者相应地初始化 T T T个本体查询 { Q e g o t ∈ R 1 × C ( t = 1 , . . . , T ) } \{{\bf Q}_{\rm ego}^{t}\!\in\!\mathbb{R}^{1 \times C} \,(t=1,...,T)\} {Qegot∈R1×C(t=1,...,T)},以提取与规划相关的信息并预测每个未来时间步骤的本体轨迹。本体查询和角度查询之间的交互是通过交叉注意进行的:
Q e g o t = C r o s s A t t e n t i o n ( Q e g o t , Q a t ) {\bf Q}_{\rm ego}^{t} = {\rm CrossAttention}({\bf Q}_{\rm ego}^{t}, \, {\bf Q}_{\rm a}^{t}) Qegot=CrossAttention(Qegot,Qat)
然后使用输出的本体查询 { Q e g o t } \{{\bf Q}_{\rm ego}^{t}\} {Qegot}来预测未来步的本体轨迹。根据先前的研究,提供高级驱动信号 c c c(左转,右转或直行)作为先验知识。规划头将 { Q e g o t } \{{\bf Q}_{\rm ego}^{t}\} {Qegot}中的连接本体特征 F e g o ∈ R T × C {\bf F}_{\rm ego}\!\in\!\mathbb{R}^{T \times C} Fego∈RT×C和驱动命令 c c c作为输入,并输出规划轨迹 P t r a j ∈ R T × 2 {\bf P}_{\rm traj}\!\in\!\mathbb{R}^{T \times 2} Ptraj∈RT×2:
P t r a j = P l a n H e a d ( F e g o , c ) {\bf P}_{\rm traj} = {\rm PlanHead}({\bf F}_{\rm ego}, c) Ptraj=PlanHead(Fego,c)
其中规划头来自于UniAD。作者使用 L 1 \mathcal{L}_1 L1损失最小化预测本体轨迹 P t r a j {\bf P}_{\rm traj} Ptraj和全局真值 G t r a j {\bf G}_{\rm traj} Gtraj之间的距离,表示为 L i m i \mathcal{L}_{\rm imi} Limi。注意的是, G t r a j {\bf G}_{\rm traj} Gtraj容易获得,但是实际场景中手动标注不易获取。
· 方向增强
观察到训练数据以直行场景为主,作者提出了一种方向增强策略来平衡分布。如图4所示,BEV特征 F b {\bf F}_{\rm b} Fb以不同的角度 r ∈ R = { 90 ° , 180 ° , 270 ° } r\!\in\!R\!=\!\{90°,180°,270°\} r∈R={90°,180°,270°}旋转,得到旋转表示 { F b } \{{\bf F}_{\rm b}\} {Fb}。增强的特征也将用于借口和规划任务,并由上述损失函数(例如 L s p a t \mathcal{L}_{\rm spat} Lspat)监督。值得注意的是,BEV对象掩码 M M M和地面真实本体轨迹 G t r a j {\bf G}_{\rm traj} Gtraj也被旋转以提供相应的监督标签。
此外,作者提出了一项辅助任务来增强转向能力。具体来说,作者根据本体查询 Q e g o t {\bf Q}_{\rm ego}^{t} Qegot预测本体汽车打算操纵的规划方向(即左转、直行或右转),该查询映射到三个方向 P d i r t ∈ R 1 × 3 {\bf P}_{\rm dir}^{t}\!\in\!\mathbb{R}^{1 \times 3} Pdirt∈R1×3的概率。方向标签 Y d i r t {\bf Y}_{\rm dir}^{t} Ydirt是通过将地面真实值 G t r a j t ( x ) {\bf G}_{\rm traj}^{t}(x) Gtrajt(x)的x轴值与阈值 δ \delta δ进行比较生成的。具体而言,如果 − δ < G t r a j t ( x ) < δ -\delta\!<\!{\bf G}_{\rm traj}^{t}(x)\!<\!\delta −δ<Gtrajt(x)<δ,则 Y d i r t {\bf Y}_{\rm dir}^{t} Ydirt分配给直行,否则对于 G t r a j t ( x ) ⩽ − δ / G t r a j t ( x ) ⩾ δ {\bf G}_{\rm traj}^{t}(x)\!\leqslant\!-\delta/{\bf G}_{\rm traj}^{t}(x)\!\geqslant\!\delta Gtrajt(x)⩽−δ/Gtrajt(x)⩾δ, Y d i r t = l e f t / r i g h t {\bf Y}_{\rm dir}^{t}\!=\!left/right Ydirt=left/right。作者使用交叉熵损失来最小化方向预测 Y d i r t {\bf Y}_{\rm dir}^{t} Ydirt和方向标签 Y d i r t {\bf Y}_{\rm dir}^{t} Ydirt之间的差距,表示为 L d i r \mathcal{L}_{\rm dir} Ldir。
· 方向一致性
针对引入的方向增强,作者提出了方向一致性损失,以改进自监督方式的增强计划训练。应该注意的是,增强轨迹预测 P t r a j t , r {\bf P}_{\rm traj}^{t,r} Ptrajt,r包含与原始轨迹预测 P t r a j t , r = 0 {\bf P}_{\rm traj}^{t, r=0} Ptrajt,r=0相同的场景信息,即具有不同旋转角度的BEV特征。因此,考虑预测之间的一致性并调节旋转引起的噪声是合理的。规划头有望对方向变化和输入干扰因素更具鲁棒性。具体而言,首先将 P t r a j t , r {\bf P}_{\rm traj}^{t,r} Ptrajt,r旋转回原始场景方向,然后对 P t r a j t , r = 0 {\bf P}_{\rm traj}^{t, r=0} Ptrajt,r=0应用 L 1 \mathcal{L}_1 L1损失:
L c o n s = 1 T ⋅ ∣ R ∣ ∑ t = 1 T ∑ r R ∣ ∣ R o t ( P t r a j t , r ) − P t r a j t , r = 0 ∣ ∣ 1 \mathcal{L}_{\rm cons} = \frac{1}{T\cdot|R|} \sum_{t=1}^{T}\sum_{r}^{R} ||{\rm Rot}({\bf P}_{\rm traj}^{t,r}) - {\bf P}_{\rm traj}^{t, r=0}||_1 Lcons=T⋅∣R∣1t=1∑Tr∑R∣∣Rot(Ptrajt,r)−Ptrajt,r=0∣∣1
其中 R o t {\rm Rot} Rot逆旋转操作。
总而言之,作者的UAD的总体目标包括空间对象性损失、角度感知预案损失,以及规划任务中的模仿学习损失、方向损失、一致性损失:
L = ω 1 L s p a t + ω 2 L d r m + ω 3 L i m i + ω 4 L d i r + ω 5 L c o n s \mathcal{L} = \omega_{1}\mathcal{L}_{\rm spat} + \omega_{2}\mathcal{L}_{\rm drm} \\ +\omega_{3}\mathcal{L}_{\rm imi} + \omega_{4}\mathcal{L}_{\rm dir} + \omega_{5}\mathcal{L}_{\rm cons} L=ω1Lspat+ω2Ldrm+ω3Limi+ω4Ldir+ω5Lcons
其中, ω 1 , ω 2 , ω 3 , ω 4 , ω 5 \omega_{1},\omega_{2},\omega_{3},\omega_{4},\omega_{5} ω1,ω2,ω3,ω4,ω5是权重系数。
5.实验
5.1 实验设定
作者在nuScenes中进行了开环评估实验,该数据集包含40,157个样本,其中6,019个用于评估。根据以前的研究,本文采用L2误差(以米为单位)和碰撞率(以百分比为单位)的指标。值得注意的是,BEV-Planner中提出的与道路边界的交叉率(以百分比为单位)也包括在评估中。对于闭环设置,作者遵循以前的研究在CARLA模拟器的Town05基准中进行评估。路线完成度(以百分比为单位)和驾驶得分(以百分比为单位)用作评估指标。我们采用基于查询的视图转换器从多视图图像中学习BEV特征。开集2D检测器的置信度阈值设置为0.35,以过滤不可靠的预测。分割BEV空间的角度θ设置为4 ∘ ^{\circ} ∘( K = 36 0 ∘ / 4 ∘ K=360^{\circ}/4^{\circ} K=360∘/4∘),默认阈值 δ \delta δ为1.2米。权重系数设置为 2.0、0.1、1.0、2.0、1.0。本文的模型在8个NVIDIA Tesla A100 GPU上训练了24个epoch,每个GPU的批次大小为1。除非另有说明,否则其他设置遵循UniAD 。
作者观察到,ST-P3和VAD在其官方代码中采用了与UniAD不同的开环评估协议(L2误差和碰撞率)。作者分别将ST-P3和VAD中的设置表示为 T e m A v g TemAvg TemAvg,将 UniAD 中的设置表示为 N o A v g NoAvg NoAvg。具体来说, T e m A v g TemAvg TemAvg协议通过对0.5秒到相应时间戳的性能进行平均来计算指标。以2秒时的L2误差为例, T e m A v g TemAvg TemAvg中的计算为:
L 2 @ 2 s = Avg ( l 2 0.5 s , l 2 1.0 s , l 2 1.5 s , l 2 2.0 s ) {\rm L2@2s}=\operatorname{Avg}({l2}_{0.5s},{l2}_{1.0s},{l2}_{1.5s},{l2}_{2.0s}) L2@2s=Avg(l20.5s,l21.0s,l21.5s,l22.0s)
其中 A v g {\rm Avg} Avg是平均操作, 0.5 s 0.5s 0.5s是nuScenes中两个连续标注帧之间的时间间隔。对于 N o A v g NoAvg NoAvg协议, L 2 @ 2 s = l 2 2.0 s {\rm L2@2s}={l2}_{2.0s} L2@2s=l22.0s。

表1|nuScenes上开环规划性能©️【深蓝AI】编译
5.2 和目前最好算法的对比
· 开环评估
表1显示了L2误差、碰撞率、与道路边界的交叉率和FPS方面的性能比较。由于ST-P3和VAD采用与UniAD不同的评估协议来计算L2误差和碰撞率,作者分别计算不同设置下的结果,即 N o A v g NoAvg NoAvg和 T e m A v g TemAvg TemAvg。如表1所示,所提出的UAD在所有指标上都实现了优于UniAD和VAD的规划性能,同时运行速度更快。值得注意的是,与UniAD和VAD相比,作者的UAD在 N o A v g NoAvg NoAvg评估协议下在 C o l l i s i o n @ 3 s \rm Collision@3s Collision@3s上获得了39.4%和55.2%的相对改进(例如,39.4%=(0.71%-0.43%)/0.71%),证明了作者方法的长期稳健性。此外,UAD的运行速度为7.2FPS,分别比UniAD和VAD-Base快3.4倍和1.4倍,验证了作者框架的效率。令人惊讶的是,作者的微型版本UAD-Tiny与VAD-Tiny中的基干、图像大小和BEV分辨率设置保持一致,以18.9FPS的最快速度运行,同时明显优于VAD-Tiny甚至达到与VAD-Base相当的性能。这再次证明了作者设计的优越性。最近许多研究讨论了在规划模块中使用本体状态的效果。按照这种趋势,作者还将他们模型的本体状态版本与这些作品进行了公平的比较。这表明作者的UAD的优势仍然得到保留,并且在比较方法中也取得了最佳性能。此外,BEV-Planner引入了一个名为“交互”的新指标,以更好地评估E2EAD方法的性能。如表1所示,作者的模型获得了1.13%的平均交互率,明显优于其他方法。这再次证明了作者的UAD的有效性。另一方面,这表明了设计一个合适的模块来感知环境的重要性,仅使用本体状态对于安全驾驶是不够的。

表2|CARLA模拟器上闭环验证©️【深蓝AI】编译
· 闭环评估
CARLA 中的仿真结果如表2所示。与最近的E2E规划器ST-P3和VAD相比,作者的UAD在所有场景中都取得了更好的性能,证明了其有效性。值得注意的是,在具有挑战性的Town05 Long基准上,UAD大大优于最近的E2E方法VAD,驾驶得分高出41.32分,路线完成率高出19.24分。这证明了作者的UAD对于长期自动驾驶的可靠性。

表3|对于损失函数的消融实验©️【深蓝AI】编译
5.3 消融实验
· 损失函数
作者首先分析了与所提出的借口任务和自监督轨迹学习策略相对应的不同损失函数的影响。实验是在nuScenes的验证分割上进行的,如表3所示。具有单一模仿损失 L i m i \mathcal{L}_{\rm imi} Limi的模型被视为基线 (①)。随着空间对象性损失 L s p a t \mathcal{L}_{\rm spat} Lspat增强的感知能力,平均L2误差和碰撞率分别从3.18m和2.43%明显改善到1.00m和0.71%(② vs. ①)。最优角度损失 L d r m \mathcal{L}_{\rm drm} Ldrm、方向损失 L d i r \mathcal{L}_{\rm dir} Ldir和一致性损失 L c o n s \mathcal{L}_{\rm cons} Lcons也分别在平均L2误差上带来了1.98m、1.58m、1.77m的显著收益,超过基线模型 (③、④、⑤ vs. ①)。最后将损失函数组合起来,构建了作者的UAD (⑥),获得了平均L2误差0.90m和平均碰撞率0.19%。结果证明了每个提出的组件的有效性。

表4|对于最优解码器的消融实验©️【深蓝AI】编译
· 使用最优解码器进行时间学习
使用所提出的最优解码器进行时间学习是通过循环更新和梦想损失实现的。循环更新负责从观察到的场景中提取信息(等式2)并生成伪观察以预测未来帧的本体轨迹(等式3)。作者在表4中研究了每个模块的影响。循环更新和梦想损失分别在平均L2误差上带来0.70m/0.78m的性能提升(②、③v.s.①),证明了作者设计的有效性。同时应用两个模块(④)可实现最佳性能,显示出它们对时间表示学习的互补性。

表5|对于方向感知策略的消融实验©️【深蓝AI】编译
· 方向感知学习策略
方向增强和方向一致性是所提出的方向感知学习策略的两个核心组成部分。作者在表5中证明了它们的有效性。它表明方向增强将平均L2误差提高了相当多的0.05m(②v.s.①)。一个有趣的观察是,应用增强为长期规划带来了比短期规划更多的收益,即与 ① 相比,1s/3s的L2误差减少了0.01m/0.08m,这证明了作者的增强在增强较长时间信息方面的有效性。方向一致性进一步将平均碰撞率降低了令人印象深刻的0.13%(③v.s.②),增强了驱动方向变化的稳健性。

表6|角度设计的消融实验©️【深蓝AI】编译
· 角度设计
作者通过移除角度分区和角度查询来进一步探索所提出的角度设计的影响。具体来说,BEV特征直接输入到梦想解码器中以预测像素级的物体性,该解码器由具有二元交叉熵损失的BEV对象掩码(见图2)监督。此外,本体查询通过交叉注意直接与BEV特征交互以提取环境信息。结果显示在表6中。当丢弃角度设计时,平均L2误差下降0.47m,平均碰撞率持续下降1.18%。这证明了作者的角度设计在感知复杂环境和规划稳健驾驶路线方面的有效性。

表7|不同驾驶场景的性能比较©️【深蓝AI】编译
5.4 进一步分析
· 不同驾驶场景下的规划性能
方向感知学习策略旨在增强车辆转向场景中的规划性能。作者通过评估表 7 中不同驾驶场景的指标来证明他们提出的模型的优越性。根据给定的驾驶命令(即直行、左转和右转),作者将nuScenes中的6019个验证样本分为三部分,分别包含5309、301和409个。意料之中,所有方法在直行场景下的表现都比转向场景下更好,证明了增强不平衡训练数据以实现稳健规划的必要性。当应用所提出的方向感知学习策略时,作者的UAD在左转和右转场景的平均碰撞率(UAD v.s. UAD∗)上取得了相当大的进步。值得注意的是,作者的模型在转向场景中的表现远远优于UniAD和VAD,证明了它的有效性。

图5|定性分析结果©️【深蓝AI】编译
· 角度感知和规划的可视化
角度感知借口旨在感知每个扇区区域中的物体。作者通过可视化图5a中的nuScenes中预测的物体性来展示其能力。为了获得更好的视图,作者将离散的物体性得分和地面实况转换为伪BEV掩码,这表明作者的模型可以成功捕捉周围的物体。图5a还展示了最近的SOTA UniAD、VAD和本文的UAD的开环规划结果,证明了作者的方法可以有效地规划更合理的本体轨迹。图5b比较了Transfuser 、ST-P3和CARLA中的UAD之间的闭环驾驶路线。作者的方法成功地注意到了人并以更安全的方式驾驶,证明了他们的UAD在复杂场景下处理安全关键问题的可靠性。
5.5 讨论
· 自我状态和开环规划评估
在规划模块中使用本体状态(见表1),在nuScenes的开环评估中获得L2错误和碰撞率(nuScenes中的原始指标)的良好表现并不困难。
但开环评估就毫无意义吗?作者的答案是否定的。
首先,观察的内在原因是直行的简单情况主导了nuScenes测试数据集。在这些情况下,即使是线性外推运动也足以进行规划也就不足为奇了。然而,如表7所示,在右转和左转等更具挑战性的情况下,开环指标仍然可以清楚地表明转向场景的难度和方法的差异,这在实验中也得到了证明。因此,开环评估并非毫无意义,关键在于测试数据和指标的分布。其次,开环评估的优势在于其效率,这有利于算法的快速发展。最近的一项模拟器设计研究也揭示了这一观点,该研究试图将闭环评估转变为开环方式。
在本文的工作中,作者将他们的模型与其他方法进行了彻底的比较,结果表明,在各种驾驶场景(直行或转向)、不同的本体状态使用方式(有或无)、不同的评估指标(L2误差、碰撞率或交叉率)和不同的评估类型(开环或闭环)下,他们的模型与以前的工作相比都有持续的改进。这再次证明了为端到端自动驾驶设计合适的任务的重要性。
如何保证当前自动驾驶系统的安全性?
安全性是实际产品中自动驾驶系统的首要要求,尤其是对于L4级自动驾驶汽车。为了保证安全,在当前技术条件下,使用预测的3D框进行离线碰撞检查是不可避免的后处理。
那么,就存在这样一个问题:如何安全地将模型应用于当前的自动驾驶系统?
在回答这个问题之前,作者重申他们的主张,即丢弃3D标签是E2EAD的一个高效、有吸引力且潜在的方向,但这并不意味着如果实际产品工程中有相对便宜的3D标签,作者就会拒绝使用任何3D标签。例如,仅标注没有对象标识的边界框进行跟踪比标记其他元素(如高清地图)和点云分割标签进行占用要便宜得多。因此,作者通过安排额外的3D检测头来提供他们方法的降级版本。相关模型就可以无缝集成到自动驾驶产品中,并实现离线碰撞检查。如表8所示,集成3D检测头不会带来额外的改进,这再次证明了他们的方法设计已经将3D信息充分编码到规划模块中。

表8|对于3D检测头的消融实验©️【深蓝AI】编译
6.总结
本文的工作旨在将端到端自动驾驶从昂贵的模块化和3D手动标注中解放出来。为此,作者提出了无监督的任务,通过预测角度上的目标和未来动态来感知环境。为了提高转向场景中的鲁棒性,作者引入了方向感知训练策略进行规划。实验证明了作者方法的有效性和效率。如上所述,虽然本体轨迹很容易获得,但几乎不可能收集带有感知标签的十亿级精确标注数据,这阻碍了端到端自动驾驶的进一步发展。作者相信本文的工作为这一障碍提供了潜在的解决方案,并且当有大量数据可用时可能会将性能推向新的水平。
编译|匡吉
审核|Los
移步公众号【深蓝AI】,第一时间获取自动驾驶、人工智能与机器人行业最新最前沿论文和科技动态👇
深蓝AI·赋能智驾+AI+机器人

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









