




CPU: 多类型任务,低延迟。
GPU: 并行计算任务,高吞吐。
GPU线程执行,齐步走:



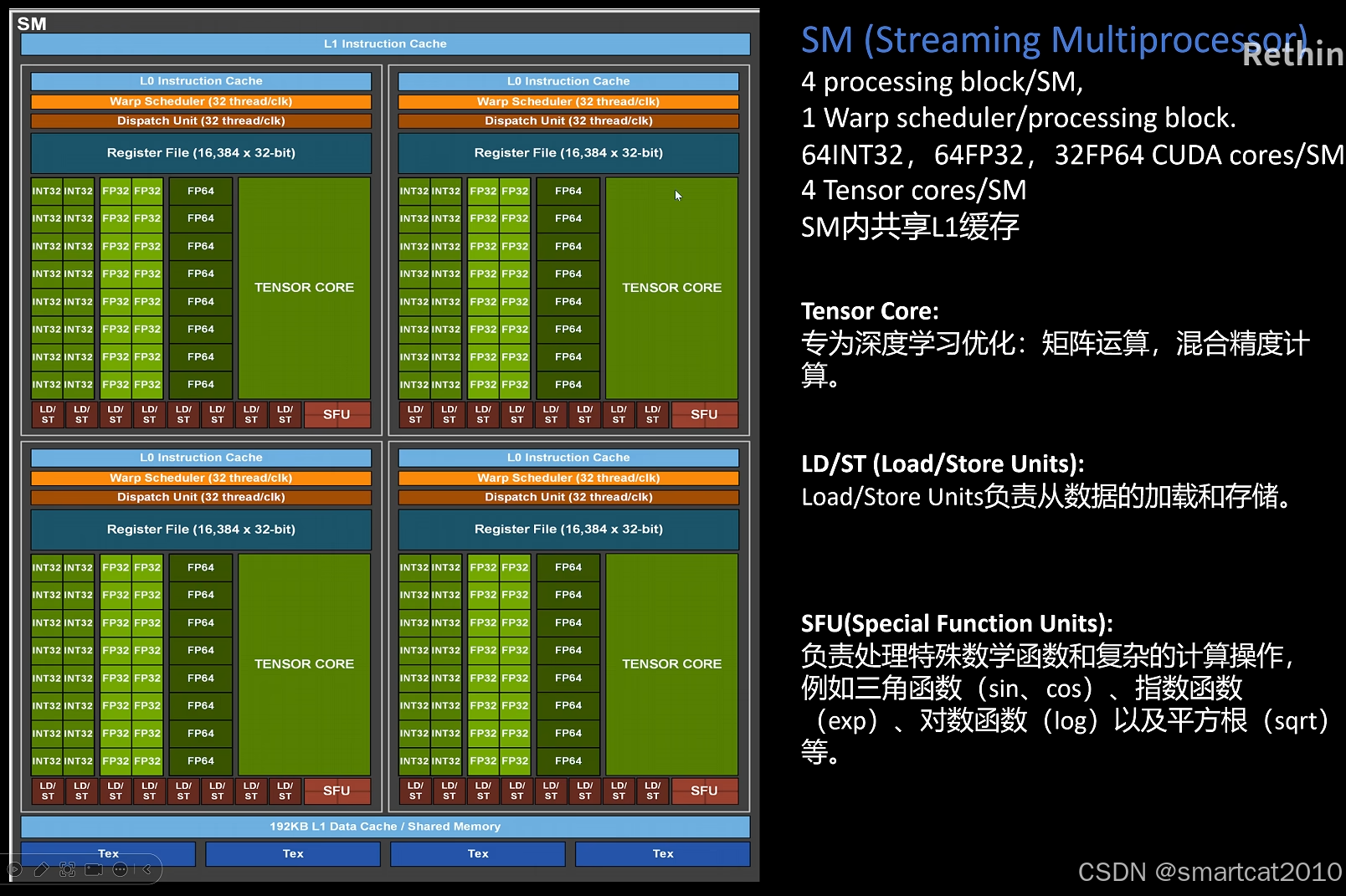
A100的Streaming Multiprocess(SM)构造:
一个SM里,有4个processing block。
L1 cache/Shared Memory,是SM内共享的。
INT32、FP32、FP64、TensorCore,这些是各自独立的计算单元。
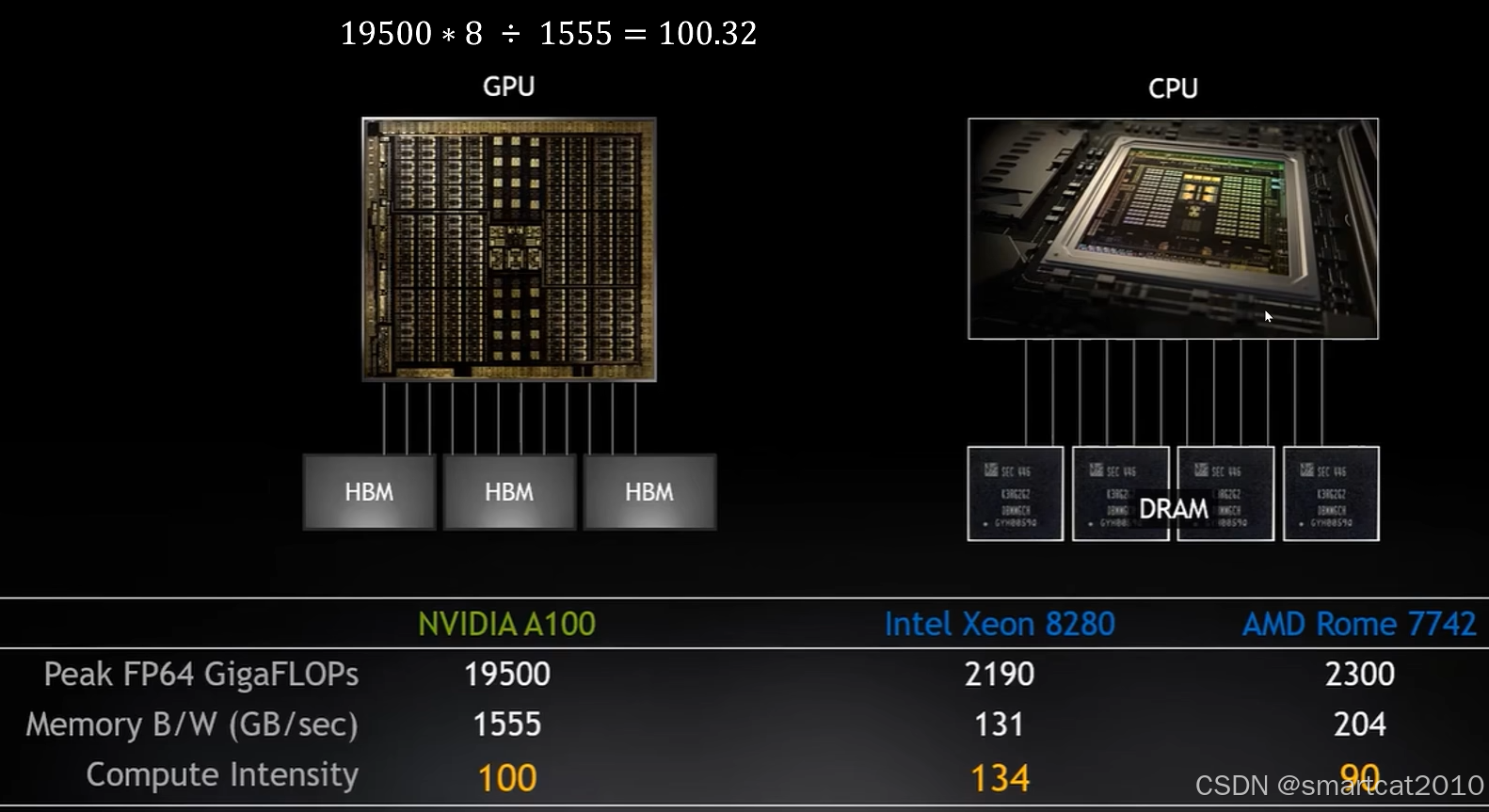
访存 VS. 计算
(CPU和DRAM主存之间的访问,是通过
CPU: 多类型任务,低延迟。
GPU: 并行计算任务,高吞吐。
GPU线程执行,齐步走:
A100的Streaming Multiprocess(SM)构造:
一个SM里,有4个processing block。
L1 cache/Shared Memory,是SM内共享的。
INT32、FP32、FP64、TensorCore,这些是各自独立的计算单元。
访存 VS. 计算
(CPU和DRAM主存之间的访问,是通过
 1522
6546
1732
1522
6546
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























