



视频教程:
【渣渣讲课】试图做一个正常讲解Latent / Stable Diffusion的成年人_哔哩哔哩_bilibili
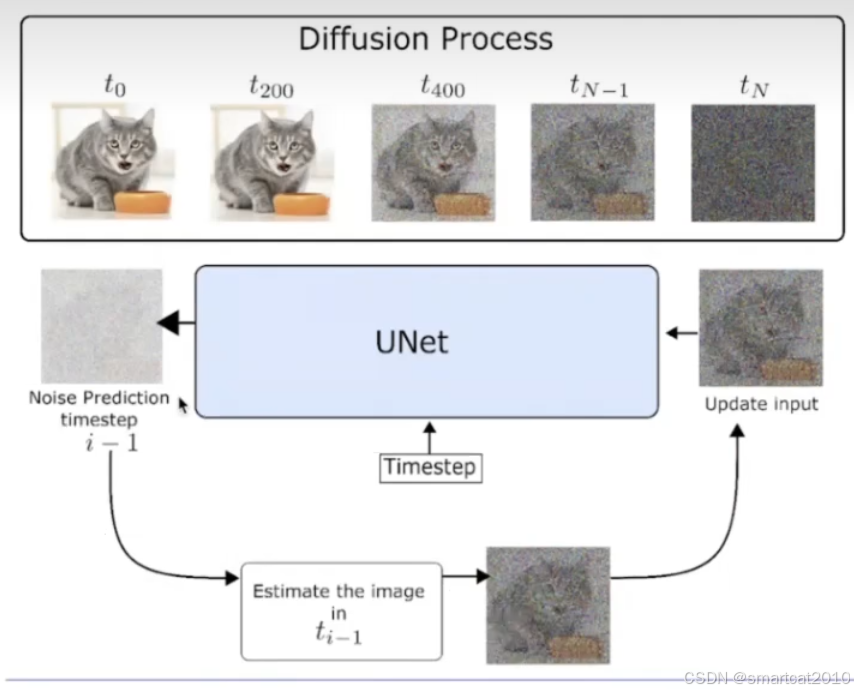
问:为什么需要很多step?
答:1. 把复杂问题,分解成小问题;2. 逐步引入text信息;
x: 输入的原始图像;
:VAE编码器;
D: VAE解码器;
z: 隐向量(latent)
:text文本句子的embedding
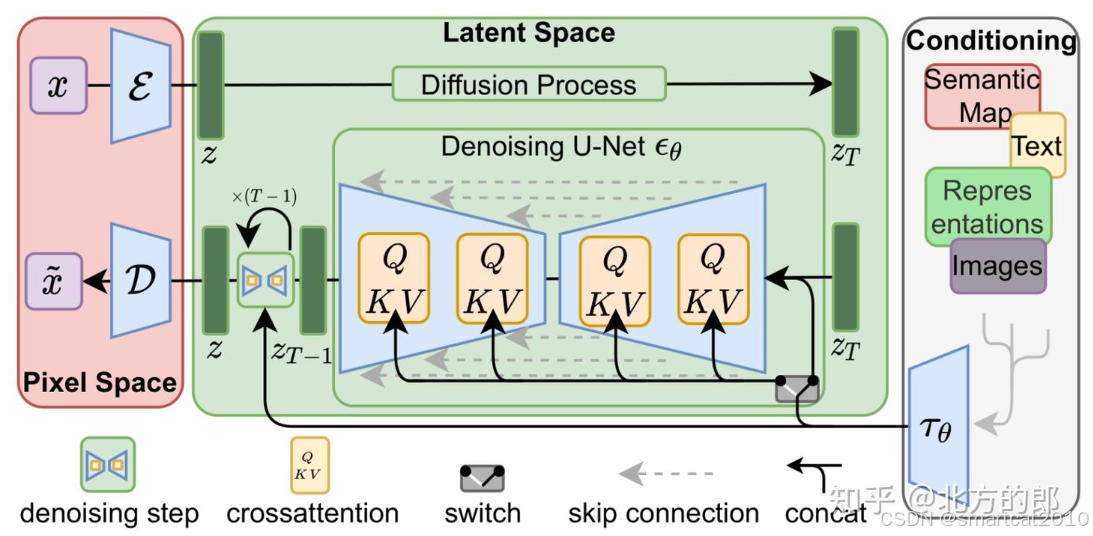
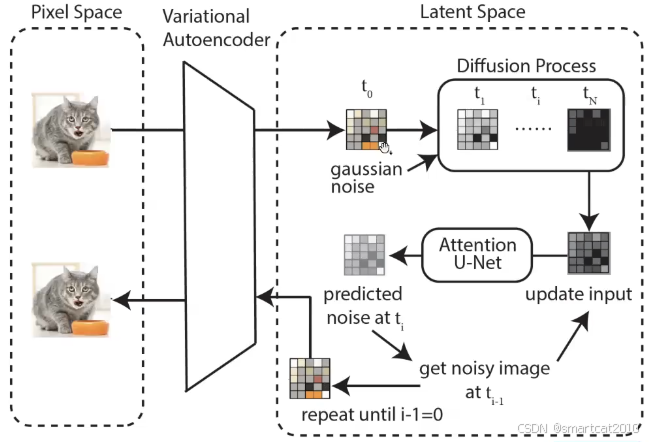
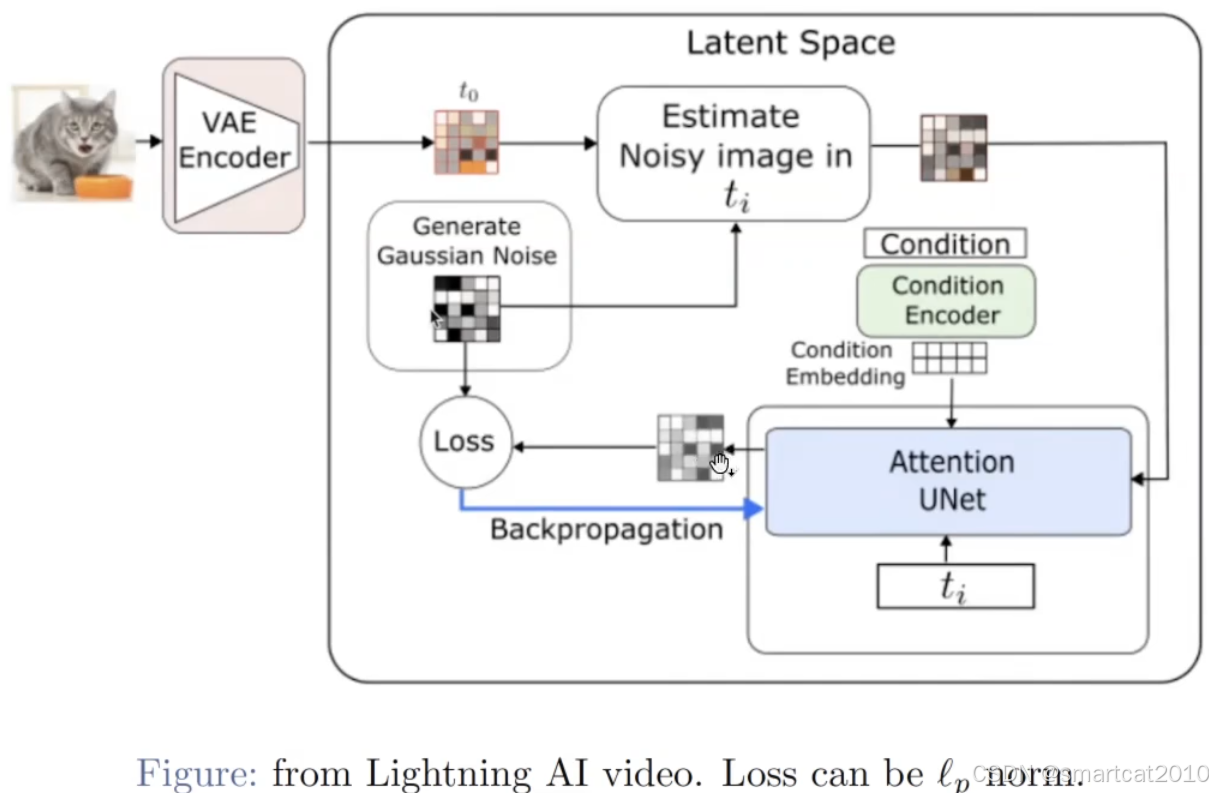
通过VAE编码器,将原始图像,转化为latent空间;在latent空间里做diffusion;
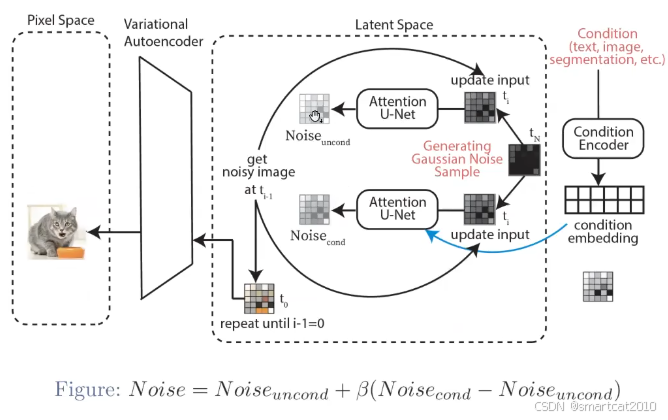
上面不加,下面加入text embedding,两者的输出,综合起来,作为该步的噪音;
损失函数:
x是t时刻的模型输入特征;
t是第t个step;
是加入的ground truth噪音;
是U-Net预测出来的噪音;
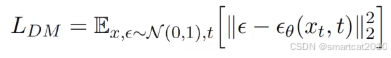
CNN直观图解:
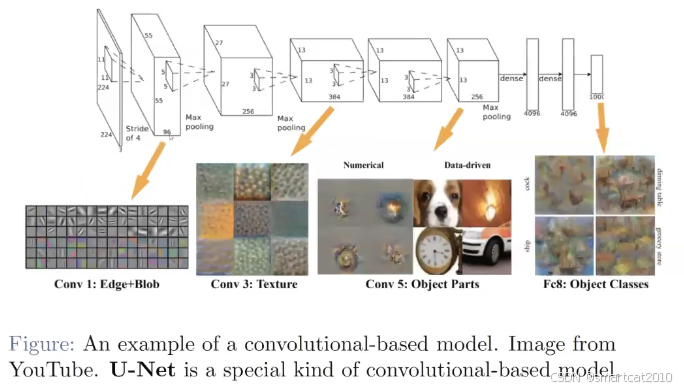
每一层,有很多Channel的feature map,每个feature map表示一种特征(从不同的角度看图片)
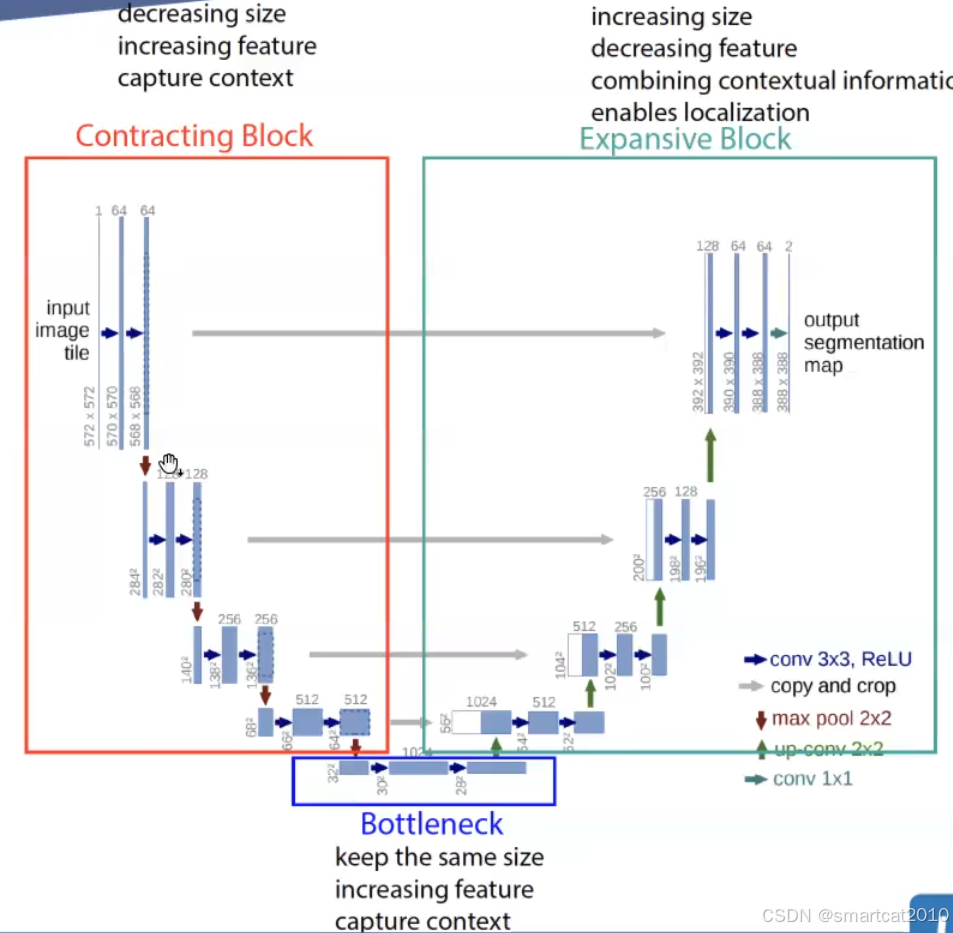
U-Net:
注意:Expansive Block的白框,是相应Contracting Block输出feature的copy;
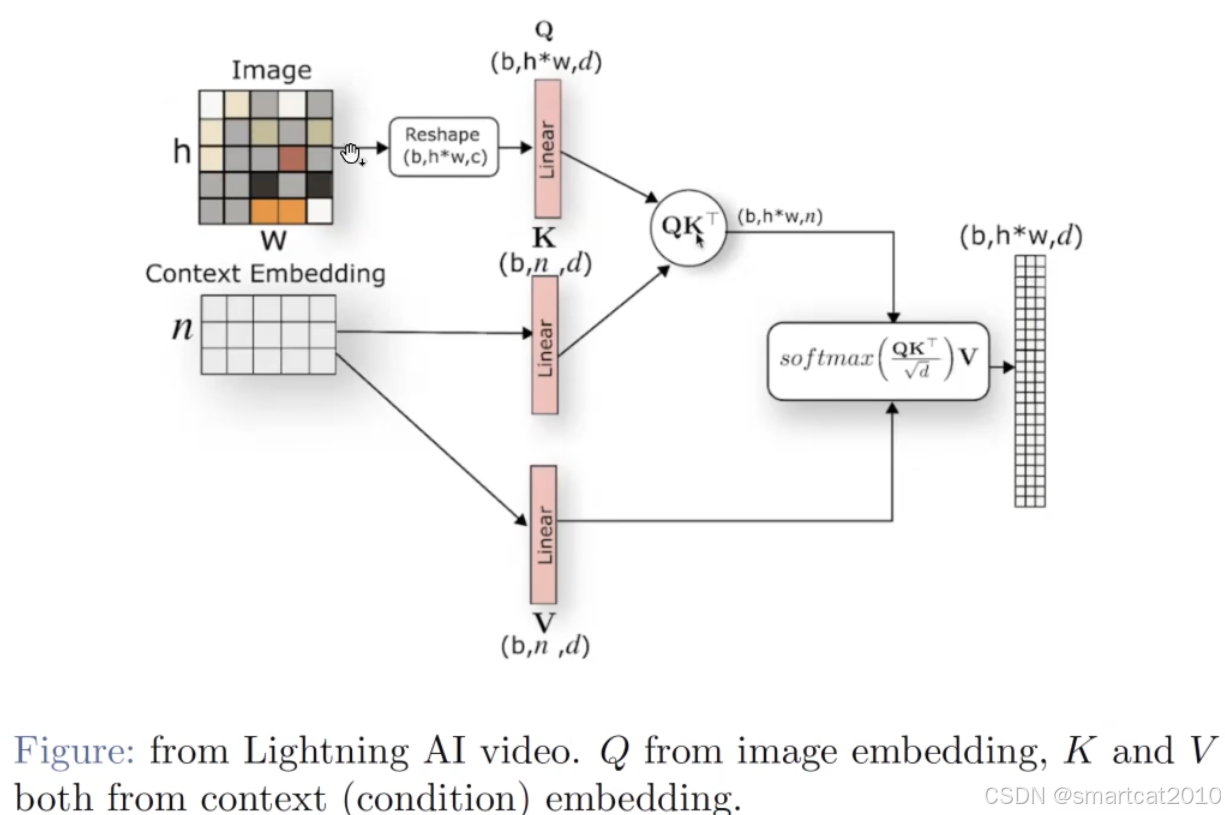
conditional embedding: 文本text的embedding;
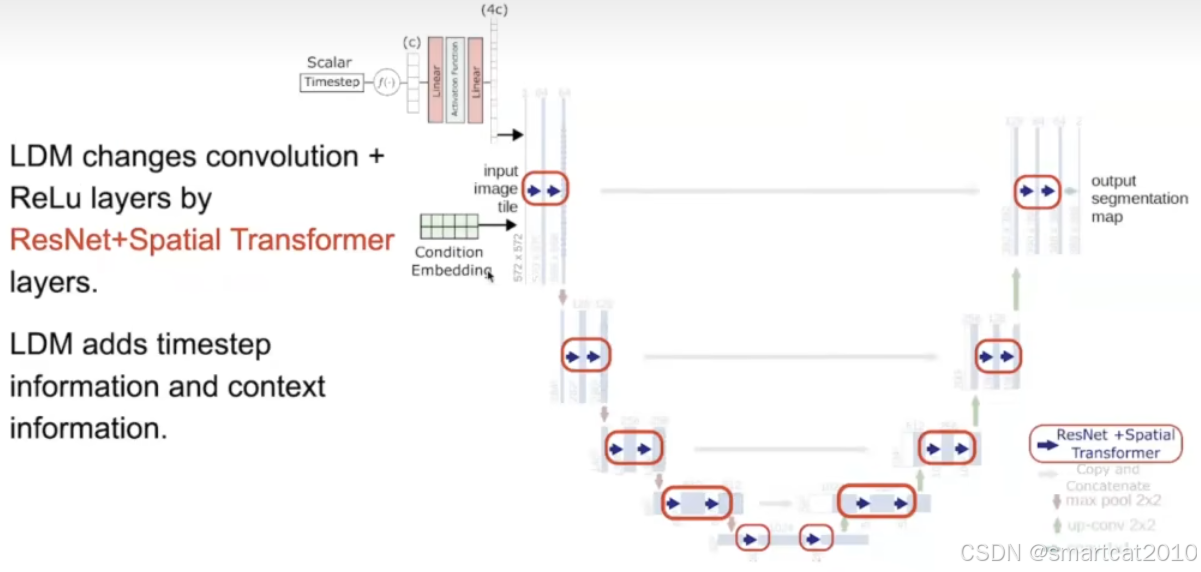
Cross Attention
V竟然来自context,不是来自图片;
插播Multi-head的好处:一个词it,可以在第1个head主要看重The animal,在第2个head主要看重tired

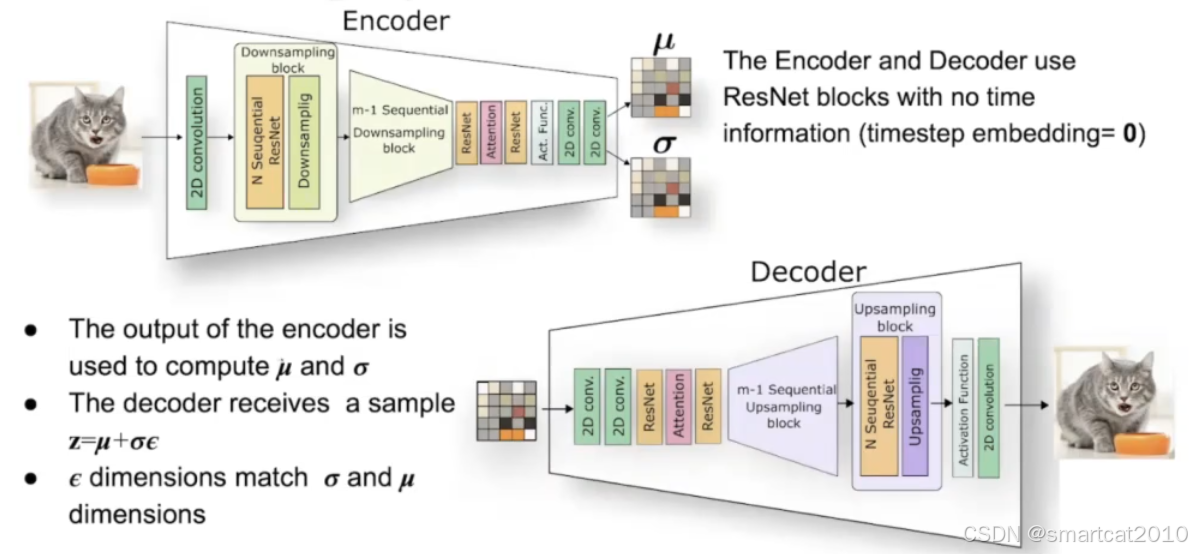
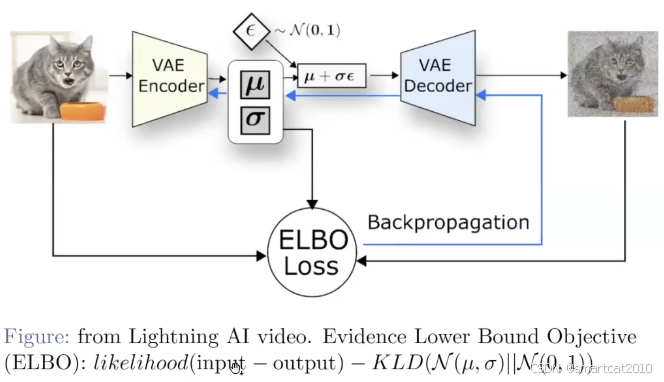
VAE:
细节:Encoder输出均值和方差,Decoder加了随机噪声
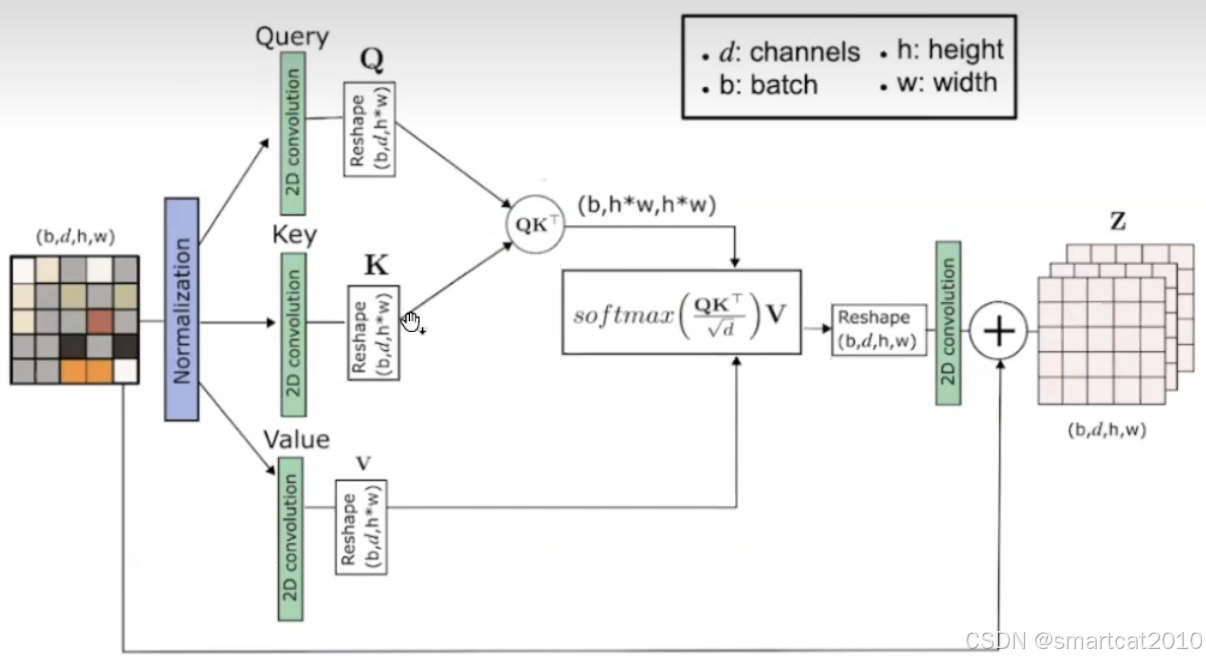
VAE里的Attention是Self-attention, 没有引入text context:
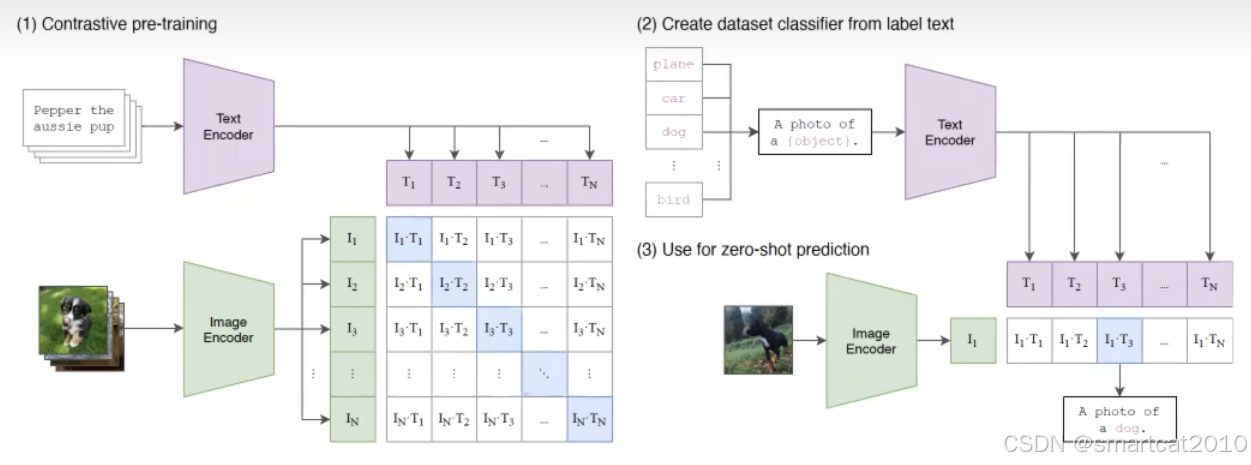
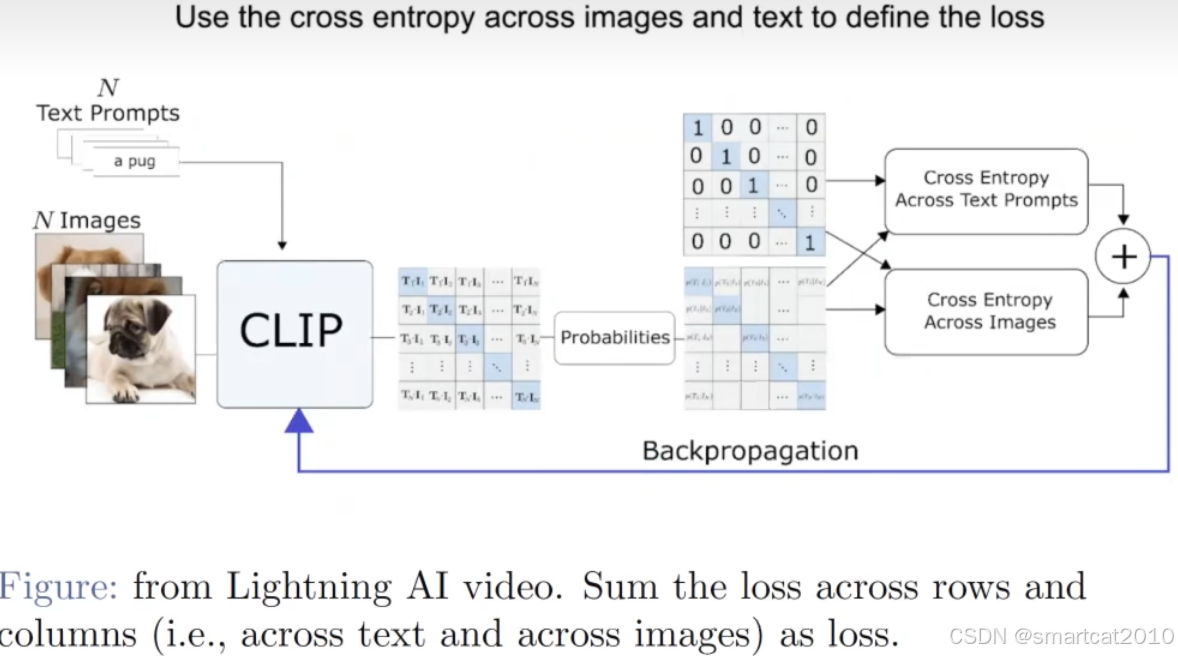
流行使用CLIP做Text Encoder:
<Text, Image>是pairwise一起训练的;训练得到的Text Encoder可以更好的表示图像特征;
先单独训练VAE;再联合训练UNet和Text Encoder(CLIP)
1. 先训练VAE:
2.1 训练UNet
2.2. 训练text encoder (CLIP方法)
一文弄懂 Diffusion Model - CV技术指南(公众号) - 博客园
训练:
首先每个迭代就是从数据集中取真实图像 x0,并从均匀分布中采样一个时间步 t,
然后从标准高斯分布中采样得到噪声 ε,并根据公式计算得到 xt。
接着将 xt 和 t 输入到模型让其输出去拟合预测噪声 ε,并通过梯度下降更新模型,一直循环直到模型收敛。
而采用的深度学习模型是类似 UNet 的结构
生成:
模型训练好之后,在真实的推理阶段就必须从时间步 T 开始往前逐步生成图片。
一开始先生成一个从标准高斯分布生成噪声,然后每个时间步 t,将上一步生成的图片 xt 输入模型模型预测出噪声。接着从标准高斯分布中采样一个噪声,根据重参数化技巧,后验概率的均值和方差公式,计算得到 xt-1,直到时间步 1 为止。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









