





文章目录
数据结构是计算机科学的核心之一,为了满足不同的应用场景,我们经常需要设计自定义的数据结构。本文将介绍六种最流行的自定义数据结构,并结合访问分析、优化技巧和代码示例,帮助理解如何设计高效的数据结构。
1. 哈希映射(Hash Map)
简介
哈希映射是一种基于哈希函数的数据结构,提供高效的键值存储。
访问分析
| 操作 | 平均时间复杂度 | 最坏时间复杂度 |
|---|---|---|
| 插入 | O(1) | O(n) |
| 删除 | O(1) | O(n) |
| 搜索 | O(1) | O(n) |
设计技巧
- 选择合适的哈希函数,避免冲突。
- 使用链地址法或开放寻址法解决哈希冲突。
- 动态扩展哈希表,避免性能下降。
代码示例
class HashMap:
def __init__(self, size=100):
self.size = size
self.table = [[] for _ in range(size)]
def _hash(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self._hash(key)
for pair in self.table[index]:
if pair[0] == key:
pair[1] = value
return
self.table[index].append([key, value])
def get(self, key):
index = self._hash(key)
for pair in self.table[index]:
if pair[0] == key:
return pair[1]
return None
def remove(self, key):
index = self._hash(key)
self.table[index] = [pair for pair in self.table[index] if pair[0] != key]
2. 双向链表(Doubly Linked List)
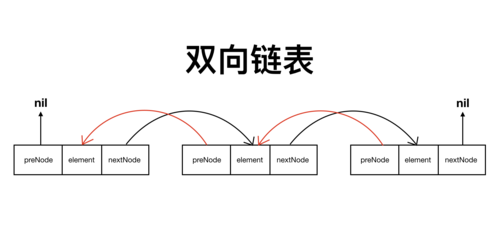
简介
双向链表是链表的一种扩展,每个节点包含前后两个指针。
访问分析
| 操作 | 时间复杂度 |
|---|---|
| 插入 | O(1) |
| 删除 | O(1) |
| 搜索 | O(n) |
设计技巧
- 使用哨兵节点,减少边界条件判断。
- 支持双向遍历,提高操作灵活性。
代码示例
class Node:
def __init__(self, data):
self.data = data
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.head = None
self.tail = None
def append(self, data):
new_node = Node(data)
if not self.head:
self.head = self.tail = new_node
else:
self.tail.next = new_node
new_node.prev = self.tail
self.tail = new_node
def remove(self, data):
cur = self.head
while cur:
if cur.data == data:
if cur.prev:
cur.prev.next = cur.next
if cur.next:
cur.next.prev = cur.prev
if cur == self.head:
self.head = cur.next
if cur == self.tail:
self.tail = cur.prev
break
cur = cur.next
3. 树状数组(Fenwick Tree)
简介
用于处理前缀和查询,常用于动态数据统计。
访问分析
| 操作 | 时间复杂度 |
|---|---|
| 更新 | O(log n) |
| 查询前缀和 | O(log n) |
代码示例
class FenwickTree:
def __init__(self, size):
self.size = size
self.tree = [0] * (size + 1)
def update(self, index, value):
while index <= self.size:
self.tree[index] += value
index += index & -index
def query(self, index):
sum_val = 0
while index > 0:
sum_val += self.tree[index]
index -= index & -index
return sum_val
4. LRU 缓存(Least Recently Used Cache)
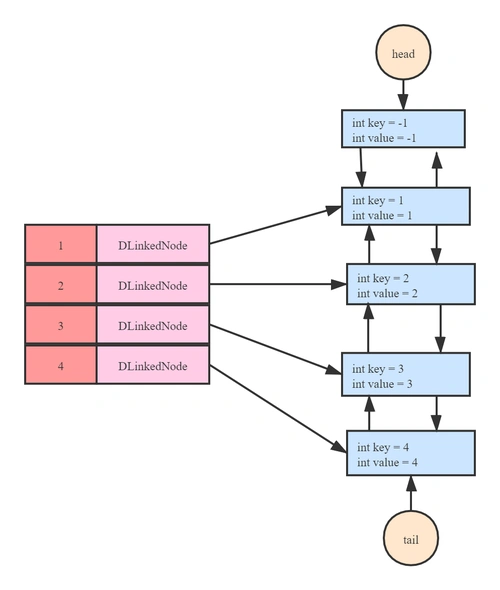
简介
用于管理有限缓存,最少使用的项被移除。
访问分析
| 操作 | 时间复杂度 |
|---|---|
| 插入/访问 | O(1) |
代码示例
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key not in self.cache:
return -1
self.cache.move_to_end(key)
return self.cache[key]
def put(self, key, value):
if key in self.cache:
self.cache.move_to_end(key)
elif len(self.cache) >= self.capacity:
self.cache.popitem(last=False)
self.cache[key] = value
5. 并查集(Disjoint Set)
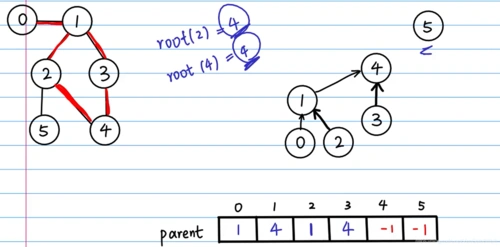
简介
用于动态连通性问题,如网络连接。
访问分析
| 操作 | 时间复杂度 |
|---|---|
| 合并 | O(α(n)) |
| 查询 | O(α(n)) |
代码示例
class DisjointSet:
def __init__(self, n):
self.parent = list(range(n))
self.rank = [1] * n
def find(self, x):
if self.parent[x] != x:
self.parent[x] = self.find(self.parent[x])
return self.parent[x]
def union(self, x, y):
root_x = self.find(x)
root_y = self.find(y)
if root_x != root_y:
if self.rank[root_x] > self.rank[root_y]:
self.parent[root_y] = root_x
else:
self.parent[root_x] = root_y
if self.rank[root_x] == self.rank[root_y]:
self.rank[root_y] += 1
6. 跳表(Skip List)
简介
用于有序数据的高效查询,替代平衡树。
访问分析
| 操作 | 时间复杂度 |
|---|---|
| 插入 | O(log n) |
| 删除 | O(log n) |
| 查询 | O(log n) |
举例代码:略…
数据结构设计技巧
在进行数据结构设计时,有几个技巧可以帮助提高系统的效率、可维护性和扩展性。以下是一些常用的技巧:
1. 选择合适的数据结构
- 根据操作的类型选择:例如,若要频繁插入和删除元素,选择链表或双端队列;若要进行快速查找、插入和删除,哈希表或平衡二叉搜索树可能更适合。
- 考虑时间复杂度:选择能最小化操作时间复杂度的数据结构,如哈希表的查找时间是O(1),而数组是O(n)。
- 空间优化:如果内存有限,考虑压缩数据结构或使用位图等节省空间的数据结构。
2. 尽量避免冗余数据
- 规范化:尽量避免重复存储相同的信息,可以通过规范化设计将冗余数据分散到不同的数据表或数据结构中。
- 压缩存储:使用如位域、前缀树、哈夫曼编码等方法对数据进行压缩,减少存储空间。
3. 分层设计
- 将数据结构设计分层,确保不同的功能模块数据结构独立,并且可以相互协作。比如,数据库系统中,索引结构、存储结构和缓存结构通常会分开设计。
4. 考虑缓存和预取
- 数据访问的效率在现代计算机系统中通常受缓存局部性影响,可以考虑如何使数据结构适应缓存,例如通过顺序存储、分页等手段减少缓存未命中。
5. 使用设计模式
- 工厂模式:用于创建特定数据结构的实例,可以提高代码的灵活性和可维护性。
- 策略模式:用于不同算法的数据结构选择,例如,在不同的查询场景下选择不同的搜索树结构。
- 代理模式:为数据结构设计添加一个代理层,实现延迟加载等功能。
6. 考虑数据的增长
- 在设计数据结构时,要考虑数据的扩展性。比如,栈和队列在处理动态数据时,通常可以通过链表实现动态扩展,避免固定容量限制。
7. 优化查询和插入操作
- 索引优化:比如,数据库中的B树或B+树索引设计可以大大提高查询效率。
- 哈希化:在适用场景下,使用哈希表可以大幅提升查找效率。
8. 避免过度设计
- 数据结构设计要根据需求进行优化,避免为了解决极少出现的边界情况而设计复杂的数据结构。应当在保证性能的前提下,尽量简化设计。
9. 延迟计算
- 对于复杂的数据结构,可以采用延迟计算的策略,直到真正需要数据时再进行计算。例如,懒加载模式可以减少不必要的数据处理。
10. 持久化和序列化
- 在设计持久化存储时,选择合适的序列化机制(如JSON、Protobuf、Thrift等),能够方便数据的保存和恢复。
通过合理运用这些设计技巧,可以帮助你在构建系统时优化性能、提高系统的可维护性和可扩展性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











