




在数字化转型的浪潮下,企业每天都在面对海量的文档、票据、合同、表格等内容。
这些信息分散在纸质文件、扫描件、照片中,格式繁杂、版式不一,人工录入耗时耗力,错误率高。
如何让机器自动理解不同格式的文档,实现一次部署,全场景识别?
这正是OCR识别系统所解决的问题。
一、复杂业务场景的“多版式识别”挑战
在实际业务中,企业面对的文档大致可分为四类:
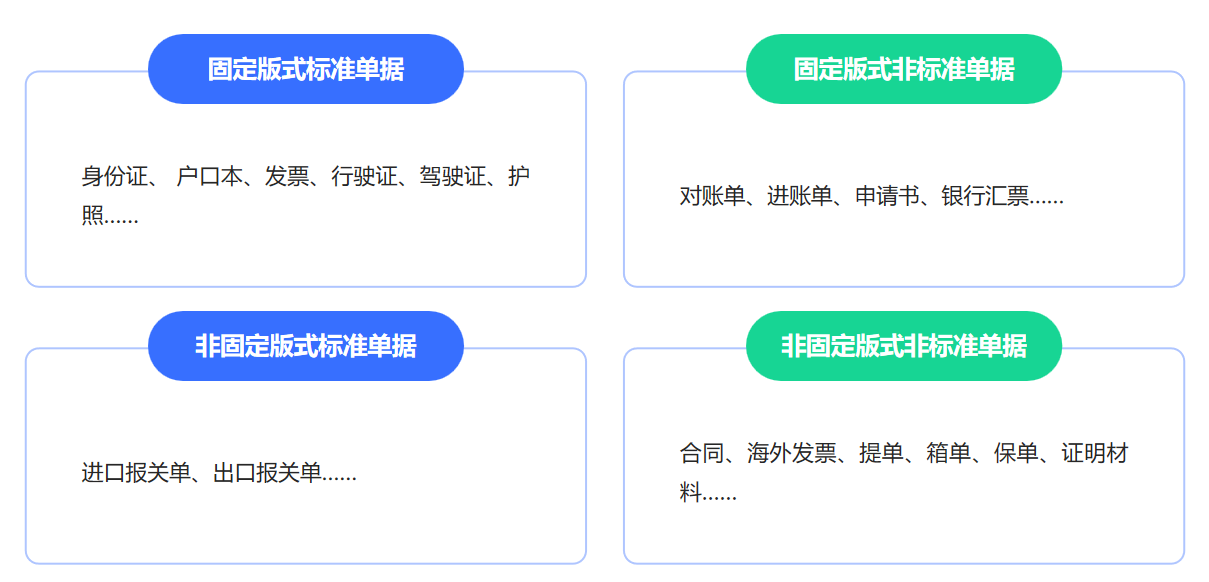
1️⃣ 固定版式标准单据:
如身份证、护照、户口本、发票、行驶证、驾驶证等。
这类文档结构稳定、字段固定,但识别要求极高,需要应对拍摄角度、光照、反光、污损等多种情况。

2️⃣ 固定版式非标准单据:
如对账单、进账单、申请书、银行汇票等。
这些文档虽具固定框架,但字段名称、表格布局可能因机构而异,传统OCR往往无法泛化识别。
3️⃣ 非固定版式标准单据:
如进出口报关单、入境健康申报表等。
版面结构可变、字段关系复杂,对版面分析与语义理解的能力提出更高要求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









