



在金融业加速迈向数字化的浪潮中,文档智能处理能力正悄然成为衡量一家金融机构运营效率、业务敏捷性以及风控水平的核心指标。伴随着业务线上化、流程无纸化,金融机构每天处理的文档数量呈指数级增长,从标准化的身份证、发票、银行卡,到非结构化的合同、理赔材料、审批文书,这些海量信息的自动化识别与解析,已经不再只是提升效率的手段,更是决定服务质量与合规风险控制能力的关键。
然而,现实却是:
一方面,身份证、营业执照、财务票据等标准化证件,识别需求高频、准确率要求极致,必须依赖稳定且高性能的OCR引擎; 另一方面,合同、理赔资料、手写申请单等非标文档种类繁杂、格式多变,传统OCR方案大多基于固定模板,维护成本高、泛化能力差,一旦文档版式变动,即需重新配置模板,极大制约了业务响应速度和系统灵活性。
中安专注文档智能识别领域,推出的专用OCR识别方案,正是面向金融行业在不同场景下的刚需痛点,提供覆盖全面、性能卓越的文档解析能力。
一、标准化文档识别:稳定、高效、可规模化落地
针对身份证、银行卡、发票、驾驶证、营业执照等高频卡证票据类型,中安专用OCR模型采用深度卷积+Attention网络结构,能够在复杂背景、低清晰度等真实拍摄环境下,实现高达99.9%的识别准确率。其核心优势在于:
-
极速响应:识别速度快,支持批量识别与并发调用;
-
灵活部署:支持本地私有化部署、信创兼容环境运行;
-
多样输入支持:兼容扫描件、照片、PDF等多种图像源格式;
-
字段结构化输出:可直接输出标准JSON结构,方便业务系统接入。

OCR方案已广泛应用于银行开户、人脸实名、票据报销、客户资料归档等场景,显著降低人工审核成本,提高信息入库效率。
二、非标文档识别:更智能、更灵活、更自适应
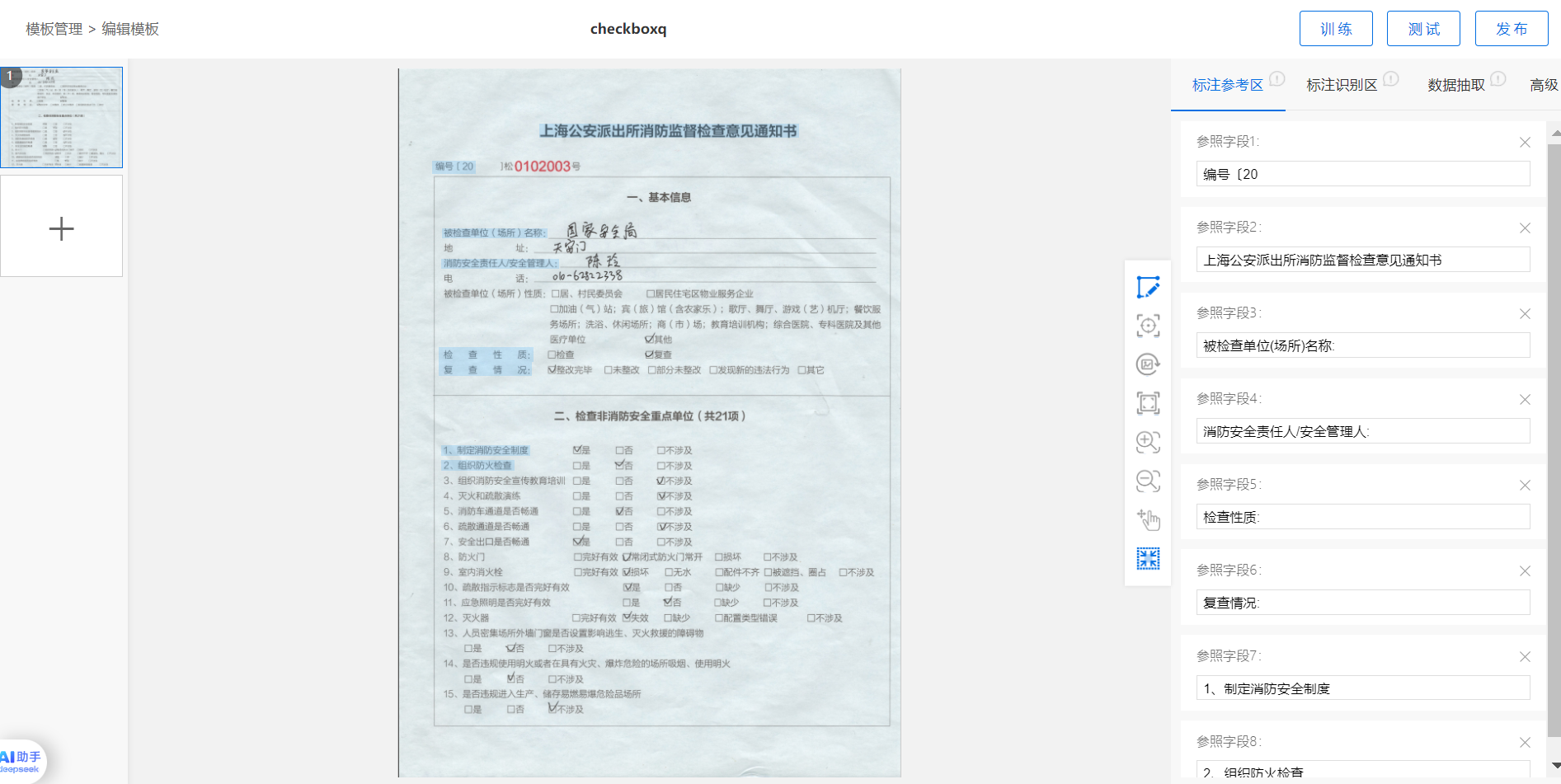
面对格式千差万别、样本稀缺的非标准文档,传统模板匹配OCR往往力不从心。 为此,智能文档影像OCR训练平台应运而生。
该平台具备以下特性:
-
无需海量标注样本: 支持少样本、甚至单样本模型训练;
-
可视化字段配置: 用户可通过图形化界面自由定义字段区域与识别规则;
-
自动模型训练与部署:训练完成后一键部署,无需开发干预;
-
支持复杂版式文档:包括表格嵌套、页眉页脚动态变化、多语种混排等场景。
适用于保险理赔单、贷款申请表、银行审批表、企业合同封面等各种变体多样的文档类型。通过这一平台,机构可实现业务自定义建模,自助拓展OCR能力,极大提升文档解析灵活性。
三、大模型赋能:低代码抽取+结构化输出
在AI大模型浪潮推动下,文档理解能力正迎来飞跃式提升。中安基于大模型训练推出的智能文档抽取系统,支持对任意文档进行低代码字段定义与内容提取:
-
用户只需上传一份样本文档;
-
可视化定义所需字段(如合同编号、保单金额、客户地址等);
-
系统即可自动学习文档结构,输出所需结构化数据;
-
支持部署为API服务,供金融核心系统实时调用。
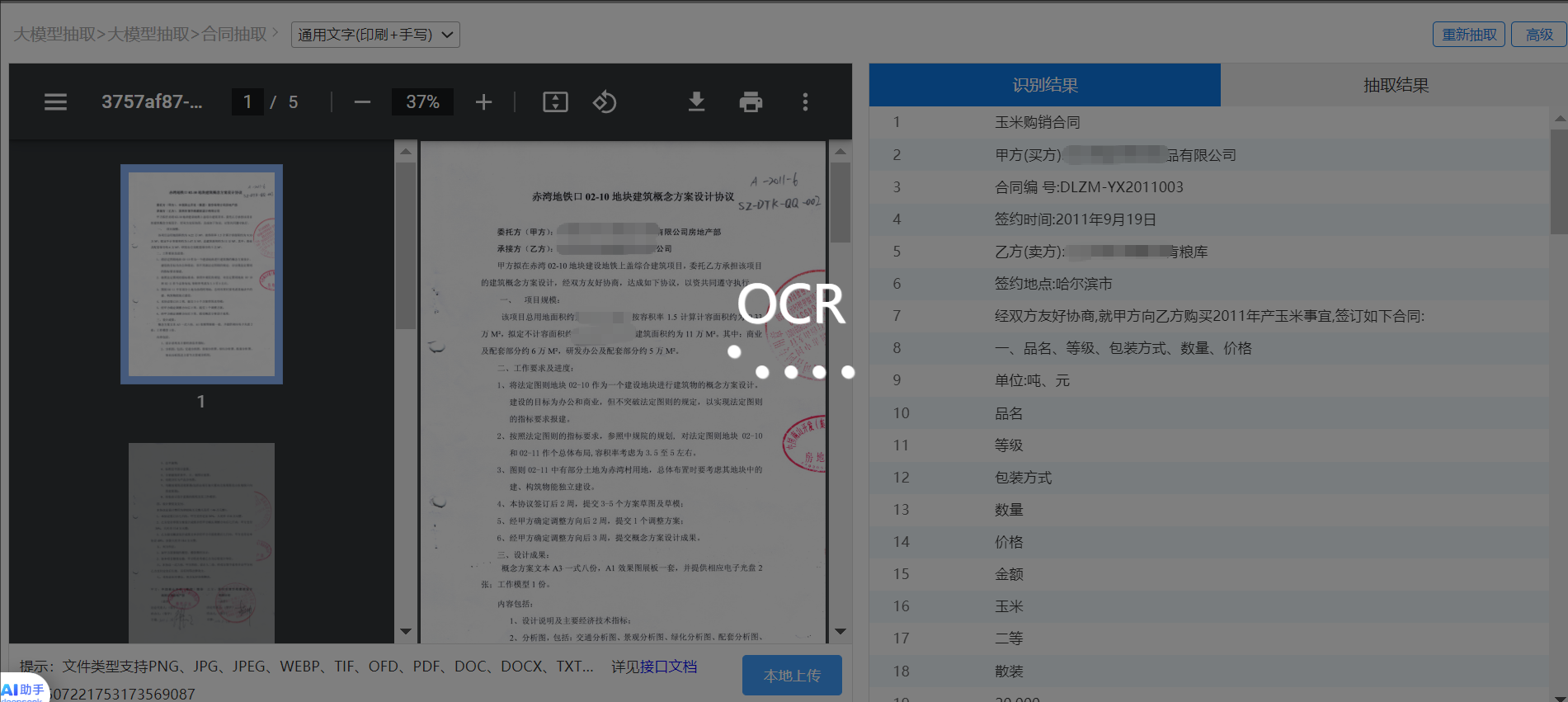
相比传统OCR方案,大模型的引入显著提升了模型对复杂语义、模糊区域、多字段嵌套的理解力,让非结构化文档也能被"读懂"、"用好"。
四、信创兼容:国产化战略全面适配
在金融信创深入推进的大背景下,数字化平台的国产适配能力成为系统选型的重要考量。 中安OCR全系列产品已完成信创生态适配认证,可与主流国产芯片(飞腾、鲲鹏、龙芯)、服务器、操作系统(麒麟、统信)、数据库(达梦、人大金仓)等深度融合。
这不仅保证了系统在金融信创环境下的高安全性与高可靠性,也为政府与大型金融客户提供了未来可持续发展与合规运营的有力支撑。
五、总结:以智能识别,释放数据价值
在海量文档处理场景下,OCR的使命不止于识别,更在于帮助企业高效获取、理解与利用数据。中安OCR解决方案,正是以其强大的识别能力、开放灵活的适配能力、可控安全的部署方案,助力金融行业迈入更高效、更智能、更可控的数字化阶段。
无论你正在应对复杂票据流转流程、拓展客户资料录入能力,还是探索大模型在业务系统中的落地实践,共同构建更智能的文档处理新生态。
OCR大模型与专用OCR识别协同,构建金融文档处理新方案


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









