



一、Markdown:用纯文本写出结构化世界
Markdown 是一种轻量级标记语言,它用最简洁的纯文本语法,实现了文档的结构化与可读性。
不需要复杂的排版工具,不需要臃肿的编辑器,只需一个文本文件,就能写出清晰的标题、列表、引用、链接、图片和代码块。
生成后即可直接发布为网页、技术博客或API文档。
GitHub、Notion、Jira、Confluence 等平台都已将 Markdown 作为内容标准。
正因如此,它被称为“技术人最懂的语言”,也是知识沉淀与内容管理的基础。
二、OCR识别:让机器理解非结构化内容
然而,现实中的信息往往并非都存在于可编辑的文本中。
发票、合同、身份证、护照、表格扫描件、图像报告……
这些都是非结构化数据,人类可以一眼看懂,但机器无法直接读取。
OCR(Optical Character Recognition,光学字符识别)技术的出现,让机器有了“读懂纸质文字”的能力。
OCR识别SDK 正是其中的代表,它通过深度学习算法 + 多语言识别模型,实现了从图像到结构化文本的全过程自动识别。
三、OCR识别SDK:不仅能识别,还能理解
OCR识别SDK 是面向企业级应用的智能识别引擎,支持文档、表格、票据、证件等多类型内容识别,可广泛应用于金融、政务、交通、出入境等场景。
其技术核心包括:
-
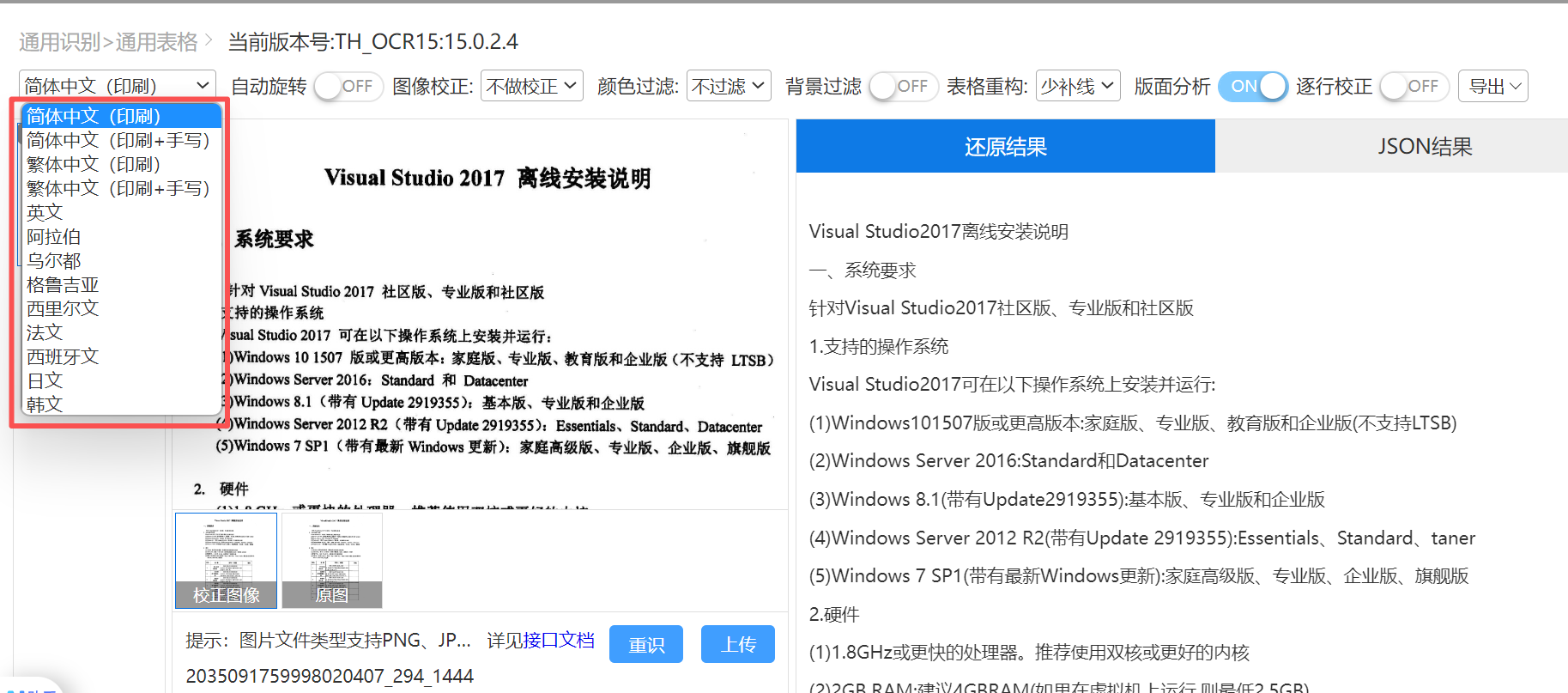
多语种识别引擎:支持中文、英文、阿拉伯文、乌尔都文、格鲁吉亚文、西里尔文、法文等语言,兼容东南亚及中东国家常见证件文本;
-
智能版面分析:自动检测文档结构,识别表格边框、单元格、字段区域,实现精准字段定位;
-
自适应图像预处理:自动纠偏、去噪、二值化、倾斜矫正,即使手机拍摄、扫描模糊的图片也能清晰识别;
-
AI模型优化:融合Transformer与CNN结构,实现复杂字体与印章叠盖的鲁棒识别;
-
数据安全控制:支持本地部署与离线识别,保障敏感信息不出内网环境。
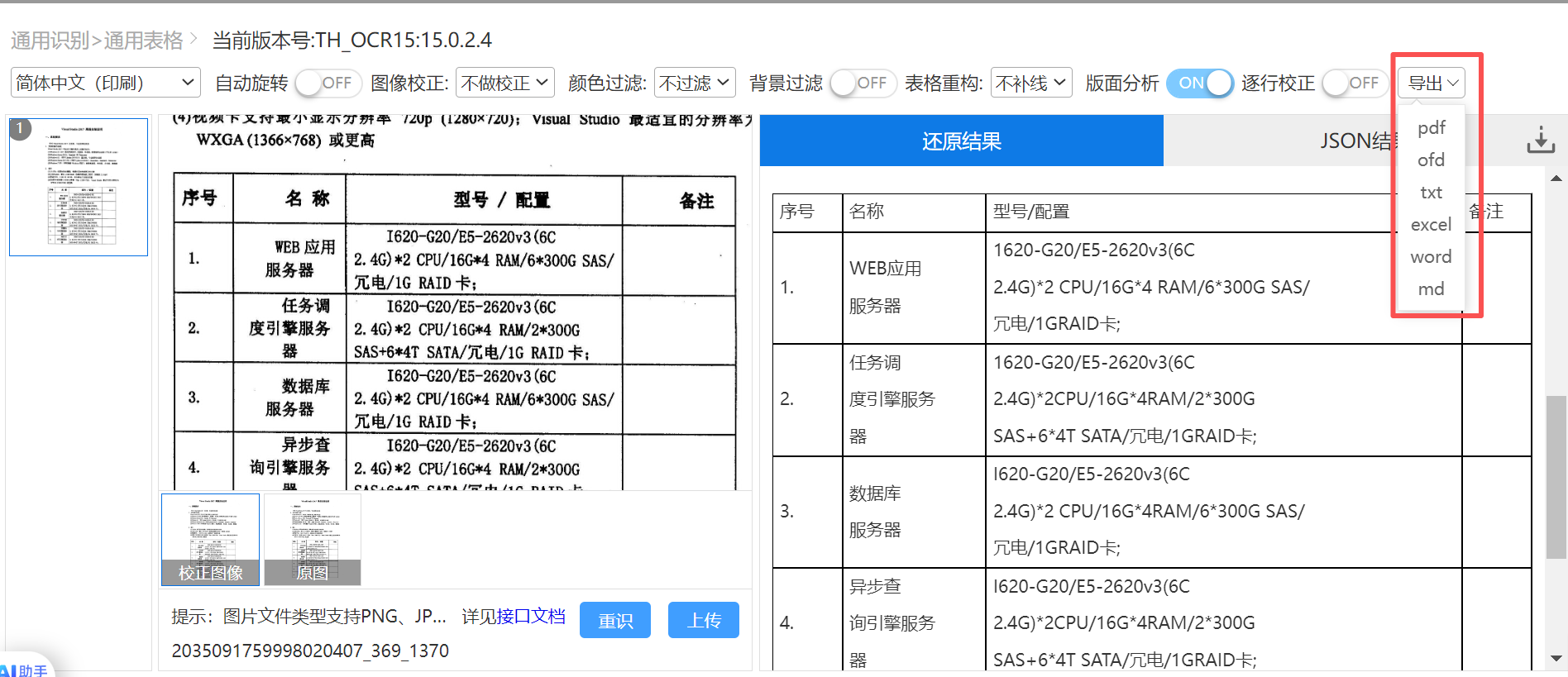
更重要的是,识别结果不仅可输出 Json、Pdf、Ofd、Excel、Word、Txt 等常见格式,
还新增支持 Markdown 格式输出 —— 这意味着识别后的文档,可以直接以Markdown格式呈现,被无缝导入知识库或技术文档系统。
四、Markdown输出,让识别结果更轻更通用
传统OCR的结果往往是“平面文字”,而Markdown输出让文本变得“结构化、可重组、可计算”。
举个例子:
当OCR识别一份扫描的合同或表格时,系统可以直接输出如下Markdown结果:

这种输出方式比纯文本更智能,既能供程序读取,也能直接发布为知识文档。
OCR 与 Markdown 的结合,让机器输出的内容,直接具备可传播性与再编辑性。
五、轻量识别 · 智能输出 · 技术赋能
Markdown 让写作更简单;OCR,让识别更智能。
当两者融合在一起,知识从纸面到数字世界的迁移,就不再是信息的搬运,而是结构的再创造。
Sinosecu OCR识别SDK 通过标准化接口和跨平台支持(Windows、Linux、Android、iOS),
可被快速嵌入企业业务系统,实现从图像到结构化知识的完整闭环。
无论是文档自动归档、表单自动提取,还是跨语言的智能识别,都能高效完成。
六、未来趋势:让机器更懂内容
在AI与知识自动化的浪潮下,OCR已不再是“识别文字”的单一工具,而是企业数字化转型的底层能力。
Markdown作为结构化知识表达标准,与OCR输出结合,正在成为技术内容管理的新方向。
未来,当系统自动识别文件并生成Markdown知识片段,我们将拥有一个能被AI直接理解、引用、学习的“活文档生态”。
这正是Sinosecu OCR识别SDK 希望带来的——让机器更懂内容,让文字真正“活起来”。
七、Markdown 编辑器推荐
- Windows
Typora、Simplenote、Laverna、Boostnote、Inkdrop、Cmd Markdown、Github、马克飞象、Yu Writer、看云、有道云笔记、为知笔记、蚂蚁笔记、Visual Studio Code [10]、Obsidian [11]
- MacOS
Typora、Typed、Ulysses、Falcon、Visual Studio Code [10]
- Linux
Typora、Atom、GNU Emacs、Remarkable、Haroopad、ReText、UberWriter、Mark My Words、Visual Studio Code [10]
- Chromium内核浏览器插件
Markdown Preview、Markdown Here
- Android
Draft、JotterPad X、坚果云Markdown
- iOS
Byword、simplenote、坚果云Markdown

















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









