




1.摘要
1 月 20 日,月之暗面推出 Kimi 全新 SOTA 模型 ——k1.5 多模态思考模型,其实现了 SOTA (state-of-the-art)级别的多模态推理和通用推理能力。官方表示,在 short-CoT 模式下,Kimi k1.5 的数学、代码、视觉多模态和通用能力大幅超越了全球范围内短思考 SOTA 模型 GPT-4o 和 Claude 3.5 Sonnet 的水平,领先达到 550%。
-
在这篇报告中,作者介绍了最新的多模态LLM Kimi k1.5的训练方法,它是用强化学习(RL)训练的。作者的目标是探索一种可能的新方向,以便继续扩展。使用RL和LLM,模型学习以奖励进行探索,因此不限于预先存在的静态数据集。
关于k1.5的设计和训练有几个关键要素。
- 长上下文缩放。我们将RL的上下文窗口缩放到128 k,并观察到随着上下文长度的增加,性能持续改善。方法背后的一个关键思想是使用部分部署来提高训练效率,即:通过重新使用先前轨迹来采样新轨迹,从而避免了从头开始重新生成新轨迹的成本。
- 改进政策优化。作者推导了长CoT的RL公式,并采用online mirror descent的变体来实现鲁棒的策略优化。通过有效的采样策略、长度惩罚和数据配方的优化,对算法进行了进一步的改进。
- 简单化框架。长上下文缩放结合改进的策略优化方法,建立了一个简化的学习资源模型学习框架。由于作者能够对上下文长度进行缩放,因此所学习的CoT表现出计划、反射和校正的属性。结果表明,在不依赖于诸如蒙特卡罗树搜索、价值函数和过程奖励模型等更复杂的技术的情况下,可以实现更强的性能。
- 多模态。模型是在文本和视觉数据上联合训练的,它具有对两种模态进行联合推理的能力。
其中长上下文扩展和改进的策略优化方法是作者方法的关键组成部分,它建立了一个简单有效的RL框架,而不依赖于更复杂的技术,如蒙特卡洛树搜索,值函数和过程奖励模型。
-
此外,作者提出了有效的long2short方法,使用长CoT技术来改善短CoT模型。具体来说,作者的方法包括对长CoT激活和模型合并应用长度惩罚。
作者的长CoT版本在多个基准测试和模型中实现了最先进的推理性能-例如,77.5在AIME上为96.2,在MATH 500上为94%,在Codeforces上为74.9,与OpenAI的o 1匹配。作者的模型还实现了最先进的短CoT推理结果-例如,60.8在AIME上为94.6,在MATH 500上为94.6,在LiveCodeBench上为47.3,比现有的短CoT模型(如GPT-4 o和Claude Sonnet 3.5)表现更好(高达+550%)。
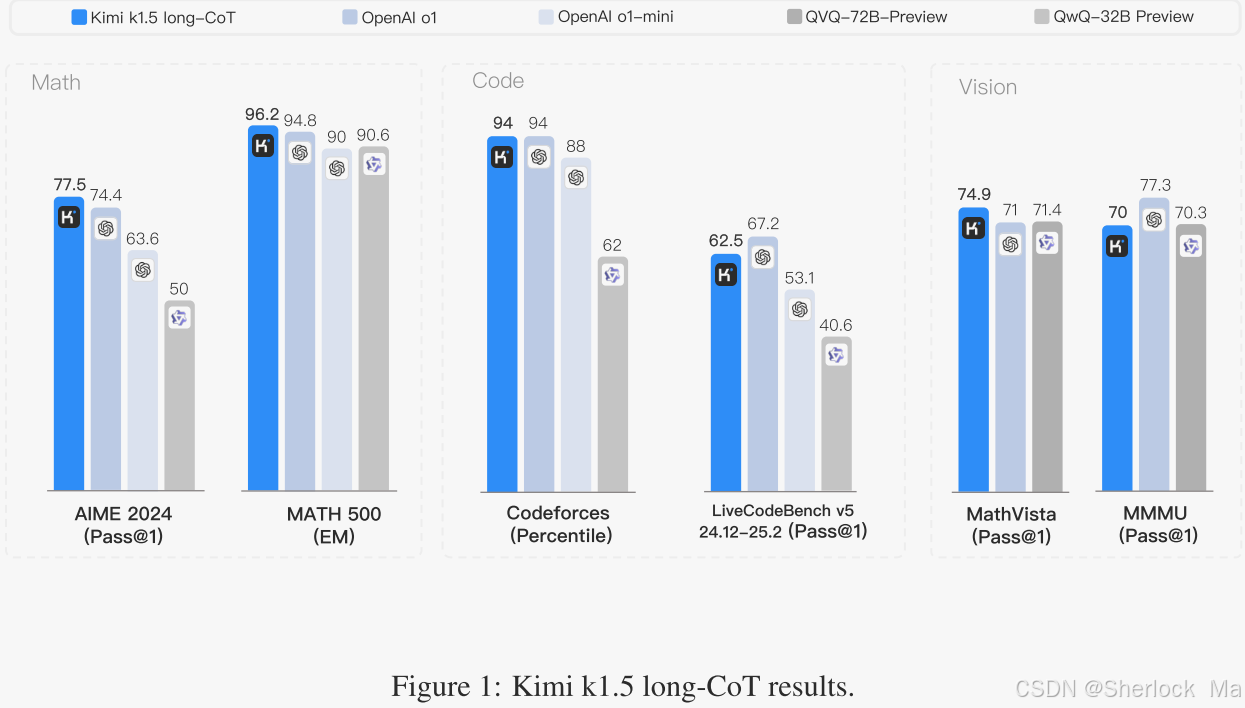
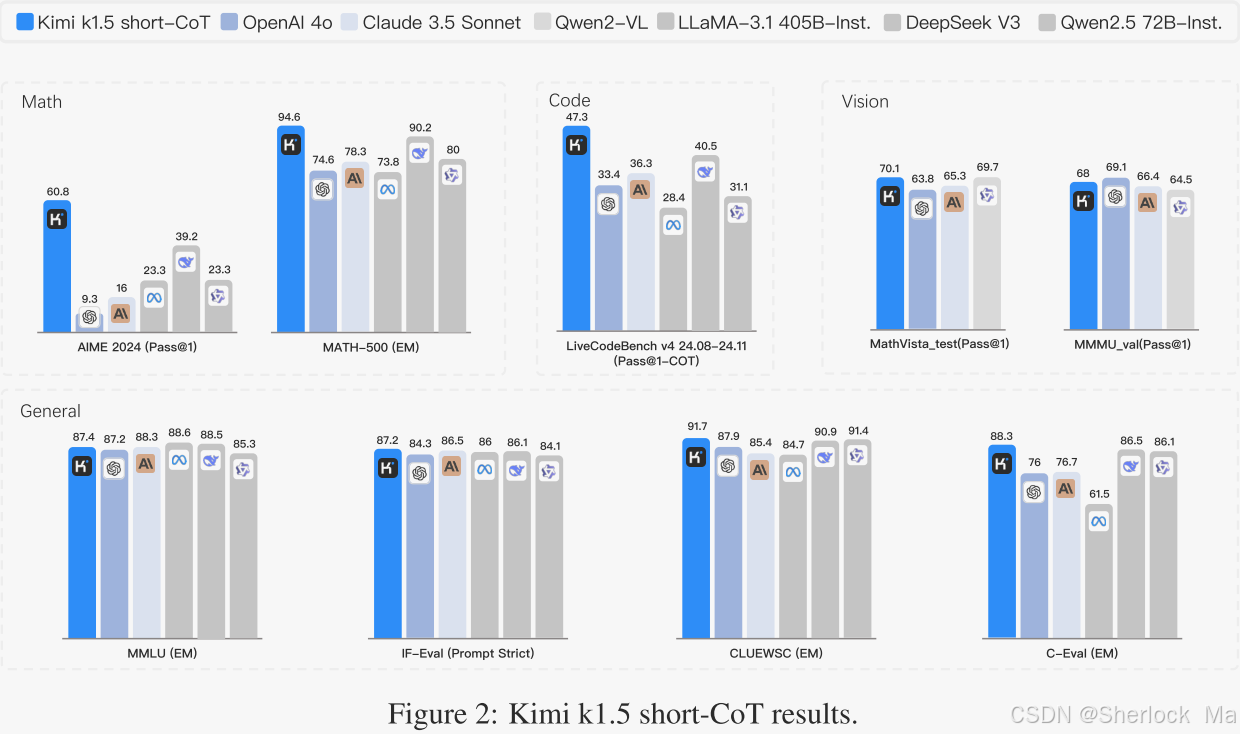
-
-
2.方法
Kimi k1.5的开发包括几个阶段:预训练,原始监督微调(SFT),长CoT监督微调和强化学习(RL)。本报告重点介绍RL。
RL提示设置
通过初步实验,作者发现RL提示集的质量和多样性在确保强化学习的有效性方面起着至关重要的作用。一个构造良好的提示集不仅可以引导模型进行稳健的推理,还可以减轻奖励黑客攻击和过度拟合表面模式的风险。具体来说,三个关键属性定义了一个高质量的RL提示集:
- 多样的覆盖范围:模型应该跨越广泛的学科,如STEM、编码和一般推理,以增强模型的适应性,并确保在不同领域的广泛适用性。
- 平衡难度:提示集应该包括一系列分布均匀的简单、中等和困难的问题,以促进渐进式学习,并防止过度拟合特定的复杂性水平。
- 准确的可评估性:验证者应该允许验证者进行客观和可靠的评估,确保模型性能是基于正确的推理而不是肤浅的模式或随机猜测来衡量的。
提示集策划的具体方法
-
自动筛选(Automatic Filtering):作者开发了一个标记系统,按领域和学科对提示进行分类,确保不同学科领域的均衡代表性。
-
难度评估(Difficulty Assessment):通过模型自身的回答成功率来评估每个提示的难度,成功率越低,提示难度越高。这种方法允许难度评估与模型的内在能力保持一致,使其对RL训练非常有效。通过利用这种方法,可以预过滤大多数琐碎的情况,并在RL训练期间轻松探索不同的采样策略。
-
避免奖励欺骗(Avoiding Reward Hacking):一些复杂的推理问题可能很容易猜测到答案,导致模型通过不正确的推理过程达到正确的答案。因此作者排除容易被模型“猜测”正确答案的问题,例如多项选择题和是非题。确保每个提示的推理过程和最终答案都能得到准确的验证。
-
Long-CoT监督微调
通过改进的RL提示集,作者采用提示工程来构建一个小而高质量的长CoT预热数据集,其中包含文本和图像输入的精确验证的推理路径,其侧重于通过即时工程生成长CoT推理路径。由此产生的预热数据集旨在封装对类人推理至关重要的关键认知过程,包括
- 规划,其中模型系统地概述了执行前的步骤;
- 评估,涉及对中间步骤的关键评估;
- 反思,使模型能够重新考虑和改进其方法;
- 探索,鼓励考虑替代解决方案。
在热身数据集上进行轻量级的监督微调(SFT),帮助模型内化这些推理策略,从而在各种推理任务中表现得更好。因此,微调的长CoT模型在生成更详细和逻辑连贯的响应方面表现出更好的能力,这增强了其在不同推理任务中的性能。
-
强化学习
问题设置
给定问题xi的训练数据集和相应的真实答案yi*,目标是训练策略模型πθ来准确地解决测试问题。在复杂推理的上下文中,问题x到解决方案y的映射是非对应(non-trivial)的。为了应对这一挑战,思想链(CoT)方法提出使用一系列中间步骤z =(z1,z2,...,zm)来桥接x和y,其中每个zi是一个连贯的令牌序列,充当解决问题的重要中间步骤。当解决问题x时,思想
进行自回归采样,然后是最终答案
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









