




1.摘要
近日,Deepseek发布了自家的第一代推理模型,DeepSeek-R1-Zero和DeepSeek-R1。其中DeepSeek-R1-Zero是一种通过大规模强化学习(RL)训练的模型,没有监督微调(SFT)作为初步步骤,其展示了卓越的推理能力。通过强化学习,DeepSeek-R1-Zero显示出了许多强大而有趣的推理行为。然而,它遇到了诸如可读性差和语言混合等挑战。
为了解决这些问题并进一步增强推理性能,作者引入了DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeekR1在推理任务上实现了与OpenAI-o1-1217相当的性能。
为了支持研究社区,作者开源了DeepSeek-R1-Zero,DeepSeek-R1和六个基于Qwen和Llama的DeepSeek-R1的蒸馏模型(1.5B,7 B,8B,14 B,32 B,70 B)。
2.简介
最近,post-training已成为大模型训练的一个重要组成部分。它可以提高推理任务的准确性,并适应用户的偏好,同时相对于预训练,它只需要相对最少的计算资源。
在推理能力方面,OpenAI的o 1系列模型是第一个通过增加思维链推理过程的长度来引入推理时间缩放的模型。这种方法在数学、编码和科学推理等各种推理任务中取得了显著的改进。然而,有效的测试时间缩放的挑战仍然是一个开放的问题。
一些先前的工作已经探索了各种方法,包括基于过程的奖励模型、强化学习,以及诸如蒙特卡罗树搜索和波束搜索。然而,这些方法中没有一种能够达到与OpenAI的o 1系列模型相当的通用推理性能。
在本文中,作者使用纯强化学习(RL)来提高语言模型推理能力。目标是探索在没有任何监督数据的情况下,通过纯RL过程的自我进化促使LLM发展推理能力的潜力。具体地说,作者使用DeepSeek-V3-Base作为基础模型,并采用GRPO作为RL框架,以提高模型在推理中的性能。在训练过程中,DeepSeek-R1-Zero自然地出现了许多强大而有趣的推理行为。经过数千个RL步骤,DeepSeek-R1-Zero在推理基准测试中表现出超强的性能。例如,AIME 2024上的pass@1得分从15.6%提高到71.0%,在多数投票的情况下,得分进一步提高到86.7%,与OpenAI-o 1 -0912的性能相当。
然而,DeepSeek-R1-Zero遇到了可读性差和语言混合等挑战。为了解决这些问题并进一步提高推理性能,作者引入了DeepSeek-R1,它包含了少量的冷启动数据和多阶段训练管道。具体来说,开始是收集数千个冷启动数据来微调DeepSeek-V3-Base模型。在此之后执行面向推理的RL。在RL过程中接近收敛时,通过RL权重上的拒绝采样创建新的SFT数据,结合DeepSeek-V3在写作,事实QA和自我认知等领域的监督数据,然后重新训练DeepSeek-V3-Base模型。在使用新数据进行微调之后,检查点会经历一个额外的RL过程,考虑到所有场景的提示。在这些步骤之后,作者获得了一个称为DeepSeek-R1的权重,它的性能与OpenAI-o 1 -1217相当。
贡献:
Post-training:
- 作者直接将强化学习(RL)应用于基础模型,而不依赖监督微调(SFT)作为初步步骤。这种方法允许模型探索解决复杂问题的思想链(CoT),从而开发了DeepSeek-R1-Zero。DeepSeek-R1-Zero展示了自我验证、反射和生成长CoT等功能,标志着研究界的一个重要里程碑。值得注意的是,这是第一个验证LLM的推理能力可以纯粹通过RL来激励,而不需要SFT的开放式研究。这一突破为该领域的未来发展铺平了道路。
- 作者介绍了开发DeepSeek-R1的管道。该管道包含两个RL阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个SFT阶段,作为模型推理和非推理能力的种子。
蒸馏:
- 较小的模型也可以很强大,作者证明了较大模型的推理模式可以被提取到较小的模型中,与通过RL在小模型上发现的推理模式相比,性能更好。开源的DeepSeek-R1及其API将使研究社区在未来提取更好的更小的模型。
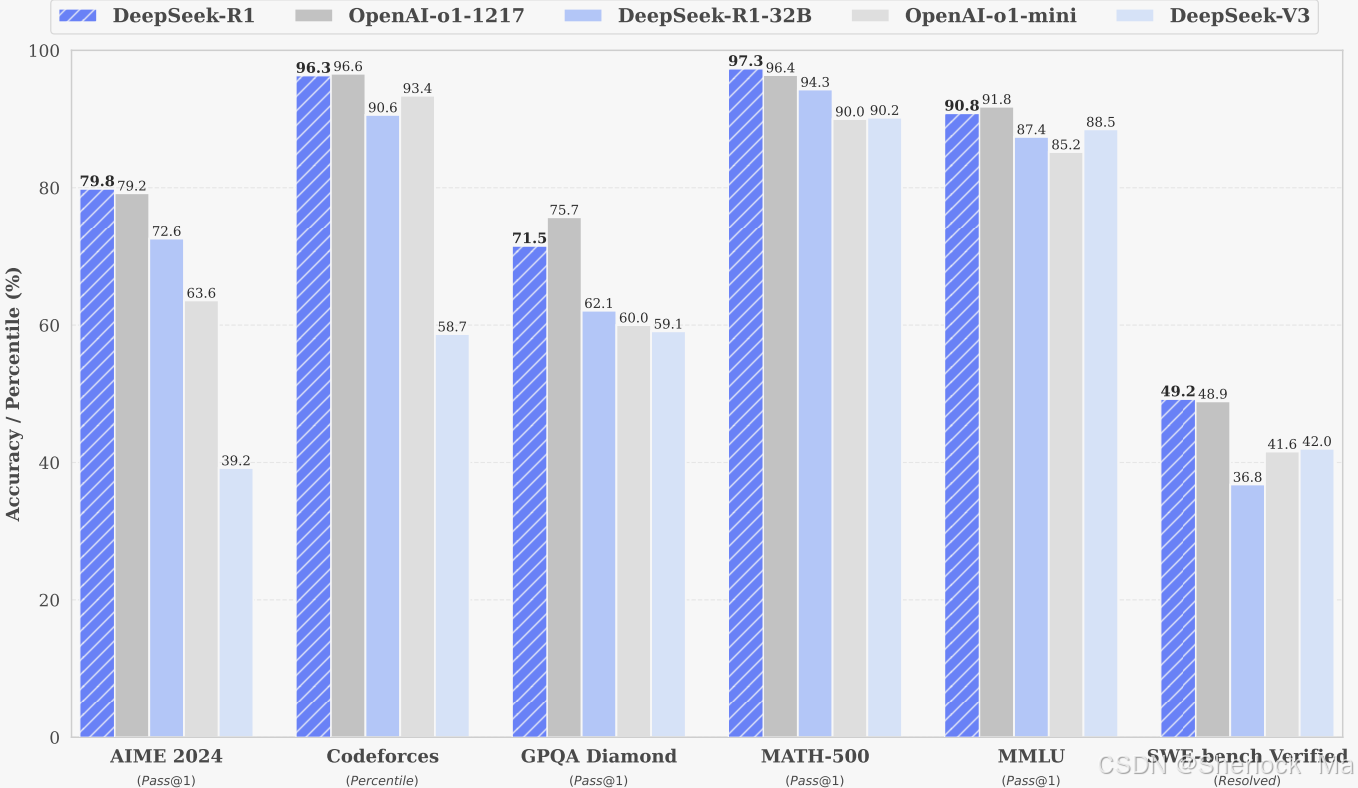
- 使用DeepSeek-R1生成的推理数据,作者微调了几个在研究界广泛使用的密集模型。评估结果表明,蒸馏较小的密集模型在基准测试中表现非常好。DeepSeekR 1-Distill-Qwen-7 B在AIME 2024上获得了55.5%的成绩,超过了QwQ-32 B-Preview。此外,DeepSeek-R1-Distill-Qwen-32 B在AIME 2024上的得分为72.6%,在MATH-500上为94.3%,在LiveCodeBench上为57.2%。这些结果明显优于以前的开源模型,并与o 1-mini相当。作者开源了基于Qwen2.5和Llama 3系列的1.5B、7 B、8B、14 B、32 B和70 B权重。
3.方法
之前的工作严重依赖大量监督数据来增强模型性能。在本研究中,作者证明了即使不使用监督微调(SFT)作为冷启动,通过大规模强化学习(RL)也可以显著提高推理能力。此外,通过包含少量冷启动数据,可以进一步增强性能。
在下面的部分中,我们将介绍:(1)DeepSeek-R1-Zero,它直接将RL应用于基础模型,而不需要任何SFT数据,以及(2)DeepSeek-R1,它从检查点开始应用RL,并通过数千个长的思想链(CoT)示例进行微调。3)将推理能力从DeepSeek-R1中提炼到小的密集模型。
DeepSeek-R1-Zero:基于基础模型的强化学习
强化学习在推理任务中已经证明了显著的有效性,然而,这些工作在很大程度上依赖于监督数据,而这些数据的收集是耗时的。在这一节中,我们将探讨LLM在没有任何监督数据的情况下发展推理能力的潜力,重点关注它们通过纯强化学习过程的自我进化。
强化学习
为了节省RL的训练成本,我们采用组相对策略优化(GRPO),其放弃了通常与策略模型大小相同的批评者模型,而是根据组分数来估计基线。具体而言,对于每个问题𝑞,GRPO从旧策略模型中抽取一组输出
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









