









1.简介
DeepSeekMath-V2 是由 DeepSeek-AI 开发的、面向自验证数学推理的大语言模型,它针对传统基于最终答案奖励的强化学习(RL)在数学推理中存在 “正确答案不代表正确推理” 及无法适配定理证明的局限性,通过训练准确且可信的验证器(含元验证机制以减少虚假问题识别)和以验证器为奖励模型的证明生成器(结合自验证实现迭代优化),构建 “验证器 - 生成器” 协同循环(生成器推动验证器处理更难证明,验证器通过扩展计算自动标注数据提升自身),最终在竞赛中表现优异:在IMO 2025和CMO 2024获金牌级成绩,Putnam 2024获 118/120 分(超人类最高分 90 分),同时在 CNML 级问题、IMO-ProofBench 等基准测试中优于 GPT-5-Thinking-High、Gemini 2.5-Pro 等模型。
模型权重:deepseek-ai/DeepSeek-Math-V2 · Hugging Face
论文地址:DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning
代码地址:deepseek-ai/DeepSeek-Math-V2
-
-
2.论文详解
简介
传统用于数学推理的 RL 方法,核心逻辑是 “根据模型预测的最终答案是否与标准答案一致来给予奖励”。这种方法虽有一定效果 —— 能让前沿 LLMs 在 AIME、HMMT 等侧重最终答案的数学竞赛中达到饱和性能(即性能不再显著提升),但存在两大根本性缺陷:
- 推理正确性与答案正确性脱节:模型可能通过错误逻辑、偶然计算误差或 “记忆解题套路” 得到正确答案,但推理过程本身不严谨、甚至完全错误。例如,在代数推导中跳过关键步骤导致中间逻辑断裂,却因最终数值巧合与标准答案一致,传统 RL 会误判其 “推理正确”。
- 无法适配定理证明任务:定理证明的核心是 “严格的分步推导”,而非输出数值答案(如证明 “存在无穷多个素数” 无需计算具体素数,只需逻辑论证)。传统 RL 的 “最终答案奖励” 在此类任务中完全失效,无法评估推导过程的严谨性。
由于上述局限,仅通过 “最终答案奖励” 训练的 LLMs 在数学推理中面临两大实际问题:
- 生成的证明存在逻辑缺陷:即使在定量推理任务中表现良好,这些模型生成的自然语言证明(如几何定理证明、数论推导)仍常出现 “数学无效” 或 “逻辑不一致” 的问题。例如,在几何证明中错误引用定理条件,或在数论推导中违反等式传递性。
- 缺乏有效的证明验证能力:模型无法可靠地判断一份证明是否正确 —— 表现为 “高假阳性率”,即经常将存在明显逻辑漏洞的错误证明判定为 “有效”,无法像人类一样识别推理中的关键缺陷。
为解决上述问题,引言明确研究核心 ——突破 “生成 - 验证差距”(generation-verification gap),让 LLMs 具备 “自验证数学推理” 能力。这一方向的提出基于三个关键观察(与人类数学推理习惯对齐):
- 人类无需参考标准答案,也能识别证明中的问题(如学生检查自己的解题过程),这一能力对解决 “无已知解的开放数学问题” 至关重要;
- 一份证明若经过多轮严格验证仍未发现问题,其有效性的可信度会显著提升(即 “验证努力程度可作为证明质量的代理指标”);
- 识别证明问题的 “努力成本” 可转化为优化信号,用于指导模型生成更严谨的证明(如通过分析 “为何某步推理被判定为缺陷”,调整后续生成逻辑)。
基于上述观察,引言提出 “迭代优化循环” 的核心思路:
- 训练 LLMs 识别证明问题(无需参考标准答案),构建可靠的 “证明验证器”;
- 以验证器的反馈为奖励,优化 “证明生成器”,使其在生成过程中主动识别并解决自身推理缺陷;
- 扩展验证计算资源,自动标注 “难验证的新证明”,生成训练数据以进一步提升验证器能力;
- 用增强后的验证器再次优化生成器,形成 “验证器 - 生成器” 相互推动的协同循环。
基于这一思路,研究团队在 DeepSeek-V3.2-Exp-Base 模型基础上,开发出DeepSeekMath-V2。初步成果显示,该模型具备强大的自验证推理能力:在 IMO 2025(国际数学奥林匹克)、CMO 2024(中国数学奥林匹克)等顶尖高中竞赛中获金牌级成绩,在 Putnam 2024(北美本科生数学竞赛)中取得 118/120 的近满分成绩,远超人类参赛者的最高得分(90 分)。
-
方法
“证明验证” 是 DeepSeekMath-V2 实现自验证数学推理的核心模块,目标是训练一个准确且可信的大语言模型验证器,使其能像数学专家一样评估证明质量 —— 识别推理缺陷并按严谨性打分,同时通过 “元验证” 机制解决验证器自身可能存在的 “虚构问题”(hallucination),为后续优化证明生成器提供可靠依据。该模块分为 “基础验证器训练” 和 “元验证优化” 两部分。
证明验证(Proof Verification)
训练验证器以识别问题并为证明打分(基础验证器)
这一部分的核心是构建验证器的“评估能力”:定义明确的评分标准,生成高质量训练数据,再通过强化学习(RL)让模型学会按标准分析证明、输出分数。
验证器的核心目标与评分标准
验证器的输入是“问题(X)”和“待评估证明(Y)”,输出是“证明分析报告”——先总结识别出的推理问题(若有),再按以下三级标准为证明打分(评分标准记为):
- 1分:证明完全正确,所有逻辑步骤均有清晰依据,无任何缺陷(如几何证明中定理引用准确、推导过程无跳跃,数论证明中边界条件全覆盖);
- 0.5分:整体逻辑正确,但存在细节遗漏或微小错误(如省略非关键的中间计算步骤,或符号标注偶发笔误,但不影响核心推理);
- 0分:证明存在根本性缺陷,包括“未解决问题核心”“致命逻辑错误”或“严重步骤缺失”(如代数推导中违反等式性质,或定理证明中遗漏关键前提条件)。
这一标准的设计初衷是模拟人类专家的评估逻辑——不仅关注“结果是否正确”,更聚焦“推理过程是否严谨”,弥补传统RL仅看最终答案的局限性。
冷启动RL数据构建(初始训练数据)
验证器训练需大量“问题-证明-分数”三元组数据,研究团队通过三步构建初始数据集(
为专家标注的分数):
- 爬取问题(
):从“Art of Problem Solving(AoPS)”平台爬取竞赛题目,优先选择需严格证明的题型(如数学奥林匹克、国家队选拔测试题),且限定2010年后题目以保证时效性,最终得到17,503个问题(记为
);
- 生成候选证明(
):使用DeepSeek-V3.2-Exp-Thinking的变体生成证明——由于该模型未针对定理证明优化,输出通常简洁但易出错,因此通过“多轮迭代提示”让其逐步补充细节、修正错误,提升证明的初始质量;
- 专家标注分数(
):随机抽取不同类型(代数、数论、几何等)的候选证明,由数学专家按上述评分标准
标注分数,确保数据的准确性与权威性。
验证器的RL训练目标与奖励函数
验证器基于“DeepSeek-V3.2-Exp-SFT”模型微调(该模型已在数学与代码推理数据上完成监督微调,具备基础逻辑分析能力),通过RL优化使其输出符合评分标准 。训练的核心是设计“双组件奖励函数”,同时约束“输出格式”与“评分准确性”:
奖励组成
- 格式奖励(
):确保验证器输出符合统一结构,便于后续解析。验证器的最终响应需包含两个关键短语:
- 问题总结部分:以“Here is my evaluation of the solution:”开头;
- 分数标注部分:以“Based on my evaluation, the final overall score should be:”开头,且分数用 \boxed{} 包裹(如\boxed{1})。 若同时满足这两个条件,
;否则为0。
- 分数奖励(
):衡量验证器预测分数(
)与专家标注分数(
例如,专家标注1分、验证器预测1分时,
;专家标注1分、验证器预测0.5分时,
,以此激励评分准确性。
RL目标函数:验证器的最终优化目标是最大化“格式奖励与分数奖励的乘积期望”,即:
其中, 是验证器的策略(参数为
),
是验证器对“问题
+ 证明
”的分析报告,
是从
中提取的预测分数。
-
引入元验证以审查证明分析(优化验证器可信度)
基础验证器存在一个关键漏洞:可能“虚构问题”——对有缺陷的证明(),验证器虽能预测出正确分数,但在分析报告中描述的“推理缺陷”并不真实存在(即hallucination),这会导致验证器的反馈不可信,进而误导证明生成器的优化。为解决这一问题,研究团队引入“元验证(Meta-Verification)”机制:训练一个“元验证器”,专门评估“基础验证器的分析报告是否合理”,并将其反馈融入基础验证器的训练,提升其缺陷识别的“忠实度”。
元验证的核心目标与标准:元验证的输入是“问题(X)”,“待评估证明(Y)”和“基础验证器的分析报告(V)”,输出是“对分析报告的审查结果”——判断V中识别的“推理缺陷”是否真实存在,且分数是否符合评分标准(元验证标准记为
)。其核心逻辑是:不直接判断证明Y是否正确,而是审查验证器的“分析过程是否严谨”。
元验证器的训练流程:元验证器同样通过RL训练,具体步骤如下:
- 获取初始验证器分析报告:用上面训练好的基础验证器
,对初始数据集
中的“问题-证明对”生成分析报告
;
- 构建元验证训练数据(
):由数学专家按元验证标准
,对“问题
(同样为0/0.5/1分),形成数据集
;
- 训练元验证器(
):元验证器的输入为“X + Y + V +
。其RL训练逻辑与基础验证器一致:
- 格式奖励:审查报告需包含指定结构(类似基础验证器);
- 分数奖励:
(
- 目标函数:最大化“格式奖励×分数奖励”的期望。
融合元验证反馈以增强基础验证器
将训练好的元验证器 作为“监督者”,优化基础验证器的训练:
- 更新奖励函数:在基础验证器的原奖励(
)中,加入元验证器的质量分数
(即元验证器对基础验证器分析报告的评分),新奖励函数为:
。 这意味着:即使基础验证器预测分数正确(
),最终奖励仍会极低,从而抑制hallucination。
- 联合训练基础验证器:用更新后的奖励函数,在“基础验证数据集
优化效果:在 的验证集上评估显示:融合元验证反馈后,基础验证器的分析报告质量(由元验证器评分)从0.85提升至0.96,且分数预测准确率完全保持不变——说明验证器在不损失评分准确性的前提下,显著减少了“虚构问题”,可信度大幅提升。
-
证明生成(Proof Generation)
“证明生成” 是 DeepSeekMath-V2 实现自验证数学推理的另一核心模块,目标是训练一个能生成高质量、严谨数学证明的生成器。该模块以可靠验证器为核心反馈工具,通过强化学习(RL)优化生成器的推理能力,并创新性引入 “自验证” 机制,让生成器主动识别并修正自身证明中的缺陷,最终实现 “生成 - 自我评估 - 迭代优化” 的闭环。模块分为 “基础证明生成器训练” 和 “自验证增强优化” 两部分。
训练用于定理证明的生成器(基础生成器)
基础生成器的核心逻辑是“以验证器的评分为奖励信号”,让模型学会生成符合数学严谨性要求的证明——不再依赖传统的“最终答案奖励”,而是以验证器对“推理过程”的评估为核心优化目标。
生成器的核心目标与输入输出:生成器的输入为“数学问题(X)”(如几何定理证明、数论命题推导等),输出为“完整的数学证明(Y)”——需包含清晰的逻辑步骤、定理引用、推导过程,确保符合数学证明的规范(如避免跳跃性推理、明确边界条件等)。其核心目标是:生成能在验证器评估中获得高分(趋近1分)的证明。
生成器的RL训练框架:生成器基于验证器构建奖励函数,通过RL迭代优化,具体设计如下:
- 基础模型与训练数据 生成器的初始模型同样基于“DeepSeek-V3.2-Exp-SFT”(已在数学与代码推理数据上完成监督微调,具备基础数学逻辑表达能力),训练数据采用上节中构建的问题集
- 奖励函数设计 生成器的奖励直接来源于验证器的评分:对于生成器针对问题
”输入验证器
。
- RL目标函数 生成器的优化目标是最大化“在问题集
。其中,
是生成器的策略(参数为
),
是验证器对
这一设计的关键优势是:将“证明质量”与“验证器的严谨评估”直接绑定,避免生成器通过“投机取巧”(如记忆答案、省略关键步骤)获得虚假高分,迫使生成器专注于推理过程的完整性与正确性。
-
通过自验证增强推理能力(解决生成器自我评估宽松问题)
基础生成器虽能通过验证器的外部反馈优化,但存在一个关键局限:自我评估能力薄弱。实验发现,当要求生成器“同时生成证明并分析自身正确性”时,它往往会“高估”自己的证明质量——即使外部验证器能轻易识别出推理缺陷,生成器仍可能声称自己的证明完全正确(即“自我评估宽松”)。这一问题导致生成器无法在无外部反馈时自主修正错误,难以应对IMO、CMO等复杂竞赛中“需多轮调整的难题”。 为解决这一问题,研究团队提出“自验证增强”方案:通过训练让生成器具备与验证器一致的评估能力,使其能自主识别自身证明的缺陷,并通过迭代优化提升证明质量。
修改生成器的输出要求:生成器针对问题 X 生成证明Y 后,需附加一份“自我分析报告 Z”——报告需严格遵循验证器的评分标准,包含两部分内容:
- 缺陷识别:分析证明 Y 中是否存在逻辑错误、步骤遗漏等问题,若有则详细说明;
- 自我评分:根据缺陷分析,为证明 Y 给出自我评分s'(同样为1/0.5/0分)。 这一设计的目的是:让生成器“换位思考”,以验证器的视角审视自己的证明,从而培养其自主纠错能力。
自验证生成器的奖励函数优化:为激励生成器进行“诚实且准确的自我评估”,设计融合“证明质量”与“自我分析质量”的复合奖励函数,具体如下:
- 奖励组成:奖励函数包含三个关键组件,兼顾格式约束、证明质量与自我评估准确性:
- 格式奖励(
):确保生成器的输出符合“证明+自我分析”的统一结构——证明部分需以“## Solution”开头,自我分析部分需以“## Self Evaluation”开头,且自我分析中需包含“Here is my evaluation of the solution:”和“Based on my evaluation, the final overall score should be: \boxed{})”等关键短语(与验证器格式一致)。若满足所有格式要求,
;否则为0。
- 证明质量奖励(
- 自我分析质量奖励(
):衡量自我分析报告 Z 的准确性,由两部分组成:
- 自我评分准确性:用外部验证器的评分 s 与生成器的自我评分 s' 的差距计算,即
(与验证器的分数奖励逻辑一致);
- 自我分析可信度:用元验证器对自我分析报告 Z 的质量评分 ms (即元验证器判断 Z 的缺陷分析是否真实、评分是否合理),记为
。 因此,自我分析质量奖励的公式为:
。
- 自我评分准确性:用外部验证器的评分 s 与生成器的自我评分 s' 的差距计算,即
- 格式奖励(
- 总奖励函数与参数设置:总奖励函数为格式奖励与“证明质量+自我分析质量”加权和的乘积,数学表达式为:
。 其中,
和
是权重参数,研究团队通过实验确定
、
——这一设置既优先保证“证明质量”(权重更高),又通过“自我分析质量”激励生成器诚实评估自身缺陷,避免自我高估。
自验证奖励的三大激励作用:该奖励函数通过权重与逻辑设计,为生成器提供明确的优化方向:它会奖励诚实认错,惩罚虚假正确,激励主动修正缺陷,促使生成器形成“生成-检查-修正”的自主迭代习惯。
-
证明验证与生成的协同作用
验证器-生成器协同”是DeepSeekMath-V2实现自验证数学推理迭代优化的核心闭环,其核心逻辑是:证明生成器的性能提升会推动验证器处理更复杂的证明,而验证器通过扩展计算能力自动标注难验证数据,反过来进一步优化生成器,形成“相互驱动、持续升级”的正向循环,最终突破单一模块的性能瓶颈。该协同机制主要通过“协同循环的形成”与“自动化标注流程的实现”两部分落地,具体设计如下:
协同循环的核心逻辑:生成器推动验证器,验证器反哺生成器。传统的“验证器-生成器”设计多为“单向依赖”(生成器仅被动接受验证器的反馈),而DeepSeekMath-V2构建了双向驱动的协同关系,其核心逻辑可拆解为两步:
- 生成器推动验证器:当证明生成器通过训练不断优化后,会生成质量更高、逻辑更复杂的证明——这些证明可能包含“细微的推理漏洞”“非标准的解题思路”或“跨领域的定理应用”,传统验证器在单次评估中难以准确识别其缺陷(即“难验证证明”)。例如,在高阶数论证明中,生成器可能采用一种新的不等式放缩技巧,验证器若未接触过类似思路,首次分析时可能无法判断该技巧的正确性,导致评分偏差。 这类“难验证证明”的出现,恰好暴露了验证器当前的能力边界——原有的训练数据
- 验证器反哺生成器:针对生成器产生的“难验证证明”,若依赖人工标注其正确性(如判断是否存在缺陷、应得多少分),会面临“成本高、效率低”的问题——随着证明复杂度提升,专家识别缺陷的时间会大幅增加,且难以覆盖所有样本。因此,研究团队提出“扩展验证计算”的方案:通过增加验证器的计算资源(如生成多份独立分析、引入元验证),自动为“难验证证明”标注质量标签,形成新的训练数据,用于提升验证器;而增强后的验证器,又能为生成器提供更精准的反馈,推动生成器进一步优化。
自动化标注流程:实现“难验证证明”的高效标注 “扩展验证计算”的核心是设计一套完全自动化的流程,无需人工干预即可为“难验证证明”标注可靠的质量标签。该流程的设计基于两个关键观察(从AI辅助标注实践中总结):
- 扩展验证样本可提升缺陷识别概率:对一份有缺陷的证明,单一验证器分析可能遗漏问题,但生成多份独立的验证分析(如n份),不同分析从不同角度检查推理,能大幅提高“捕捉真实缺陷”的概率;
- 元验证比直接找缺陷更高效:元验证(评估“验证分析是否合理”)无需从0开始识别证明缺陷,只需判断“验证器指出的问题是否真实存在”,不仅人类专家做起来更快,LLM(元验证器)也能更高效地掌握,样本利用率更高。
基于这两个观察,自动化标注流程具体分为三步(以标注某一份待评估证明 Y 为例):
- 步骤1:生成多份独立验证分析。对需要标注的“问题 X + 证明 Y ”,让验证器生成 n 份独立的验证分析(n为超参数,实验中可根据证明复杂度调整)。每份分析均包含“缺陷识别”和“分数预测”(1/0.5/0分)——通过多份独立分析,覆盖更多可能的推理检查角度,减少“单一分析遗漏缺陷”的情况。
- 步骤2:元验证筛选有效分析。对步骤1中“分数为0或0.5”的验证分析(即认为证明 Y 存在缺陷的分析),进一步生成 m 份元验证评估(m为超参数):由元验证器判断“该验证分析指出的缺陷是否真实存在”“分数是否符合评分标准
- 若多数元验证评估(如超过50%)确认该验证分析的结论合理,则判定该验证分析为“有效分析”;
- 若多数元验证评估认为该验证分析“虚构缺陷”或“分数不合理”,则判定为“无效分析”,排除在后续标注中。 这一步的目的是过滤掉验证器的“hallucination分析”(虚构缺陷的分析),确保后续用于标注的分析均为可靠的。
- 步骤3:确定证明的最终标签。综合所有“有效分析”的分数,为证明 Y 分配最终标签,具体规则如下:
- 收集所有有效分析给出的分数,找出其中的最低分(因为最低分通常对应“最严格的缺陷判断”,若最低分对应的分析有效,说明证明确实存在该分析指出的严重缺陷);
- 若至少有 k 份有效分析(k为超参数,用于控制标注严谨性)都给出了这个最低分,则将该最低分作为证明 Y 的最终标签;
- 若所有有效分析均给出1分(即未发现任何缺陷),则证明 Y 的最终标签为1分;
- 若有效分析的分数分散,无法确定最低分(如不同有效分析分数差异大,且无 k 份以上分析支持同一最低分),则将该证明 Y 标记为“存疑”,后续可选择性交由人类专家手动标注(实验中最后两轮训练已完全无需这一步,自动化流程可覆盖绝大多数情况)。
在DeepSeekMath-V2的最后两轮训练中,该自动化标注流程完全替代了人工标注——质量检查显示,自动化标注的标签与人类专家手动标注的标签“高度一致”,证明其可靠性足以支撑验证器的训练。
-
实验
训练设置
DeepSeekMath-V2的验证器与生成器训练均采用Group Relative Policy Optimization(GRPO)算法,而非传统的PPO等算法。选择GRPO的核心原因在于,其在“多智能体协同”或“多任务迭代优化”场景中,能更高效地平衡“策略更新的稳定性”与“优化速度”。对于验证器与生成器这种“相互依赖、需同步迭代”的双模块架构,GRPO可避免单一模块更新过快导致的“反馈失准”,比如验证器未充分训练就快速调整,进而使生成器接收的奖励信号不可靠,确保两者在迭代中始终保持能力匹配。
为实现“验证器-生成器”的协同循环,研究团队设计了分阶段、迭代式的训练流程,每一轮训练均遵循“先优化验证器→再优化生成器”的顺序,且从第二轮开始引入“跨轮能力继承”机制。在每一轮训练中,首先聚焦提升验证器的评估能力,输入数据方面,初始轮次采用人工标注的 和
,后续轮次则使用自动化标注流程生成的“难验证证明标注数据”;优化目标是通过GRPO最小化验证器的“评分误差”与“虚构问题率”,提升其对复杂证明的评估准确性与可信度,最终输出本轮优化后的验证器checkpoint(
)。接着,基于增强后的验证器优化生成器,生成器的初始模型不从头训练,而是直接加载本轮优化后的验证器checkpoint
,这是因为验证器已学习“如何判断证明质量”,生成器由此初始化可更快掌握“符合评估标准的推理逻辑”,减少训练成本;输入数据为问题集
(17,503个需证明的竞赛题),优化目标是通过GRPO最大化生成器生成证明的“验证器评分”,同时结合自验证奖励确保生成器兼具高质量证明生成能力与自主评估能力,最终输出本轮优化后的生成器checkpoint(
)。
为避免每一轮训练“从零开始”导致验证器丢失上一轮从生成器中学习到的“复杂证明评估经验”,从第二轮训练开始,引入拒绝微调(Rejection Fine-Tuning)机制实现验证器对“验证+生成”双能力的继承。具体操作是在启动新一轮验证器优化前,将上一轮的“生成器checkpoint ”与“验证器checkpoint
”融合,通过拒绝微调筛选出“同时具备高质量评估能力与证明逻辑理解能力”的参数,作为本轮验证器的初始checkpoint,核心目的是让验证器不仅能评估“基础证明”,还能理解生成器后续发展出的“新解题思路”,避免因“无法理解生成器的证明逻辑”导致评估失准,始终保持“生成-验证”能力同步。
-
基准测试
内部构建的CNML级问题集,该数据集包含91道定理证明题,题目类型覆盖数学竞赛中常见的五大核心领域,其中代数13题、几何24题、数论19题、组合数学24题、不等式11题,整体难度与中国高中数学联赛(CNML)相当——作为国内顶尖的高中数学竞赛,CNML的题目既注重基础推理严谨性,又包含一定复杂度的逻辑推导,适合作为模型“基础定理证明能力”的评估基准,可检验模型在常规竞赛题型中的通用性与稳定性。
IMO 2025(国际数学奥林匹克)是全球最顶级的高中数学竞赛,共6道题,题目聚焦跨领域综合推理,对逻辑严谨性与解题创新性要求极高,是衡量模型高中阶段定理证明能力的核心标杆;
CMO 2024(中国数学奥林匹克)作为中国国家级高中数学竞赛,同样包含6道题,难度与IMO接近,且题目风格更贴合亚洲数学竞赛的推理逻辑,可进一步补充验证模型在高中顶尖竞赛中的适应性;
Putnam 2024(威廉·洛厄尔·普特南竞赛)是北美最具影响力的本科生数学竞赛,共12道题,题目深度远超高中竞赛,涉及更抽象的数学概念与更复杂的推导过程,用于评估模型在本科阶段数学推理的极限能力;
ISL 2024(IMO候选名单)包含31道题,这些题目由IMO参与国提出,是IMO正式题目的备选库,难度覆盖从IMO中等至难题,可作为模型应对“多样化竞赛题型”的补充基准;
IMO-ProofBench则是由DeepMind团队(开发DeepThink IMO-Gold模型)构建的专项基准,共60道题,分为基础集与进阶集,基础集30题难度从“赛前训练级”到“IMO中等难度”,进阶集30题则模拟完整的IMO考试难度(最高至IMO难题),该基准的优势在于提供了明确的难度梯度,可精细衡量模型在“从基础到顶尖”不同难度区间的定理证明能力。
-
评估结果
评估结果围绕DeepSeekMath-V2的“单轮生成能力”“迭代优化能力”与“高计算搜索能力”三大核心场景展开,结合不同难度的评估基准,从基础到顶尖逐步验证模型的自验证数学推理性能,同时与主流模型(如GPT-5-Thinking-High、Gemini 2.5-Pro)及人类表现对比,全面凸显其优势与特点。
单轮生成(One-Shot Generation):基础定理证明能力验证
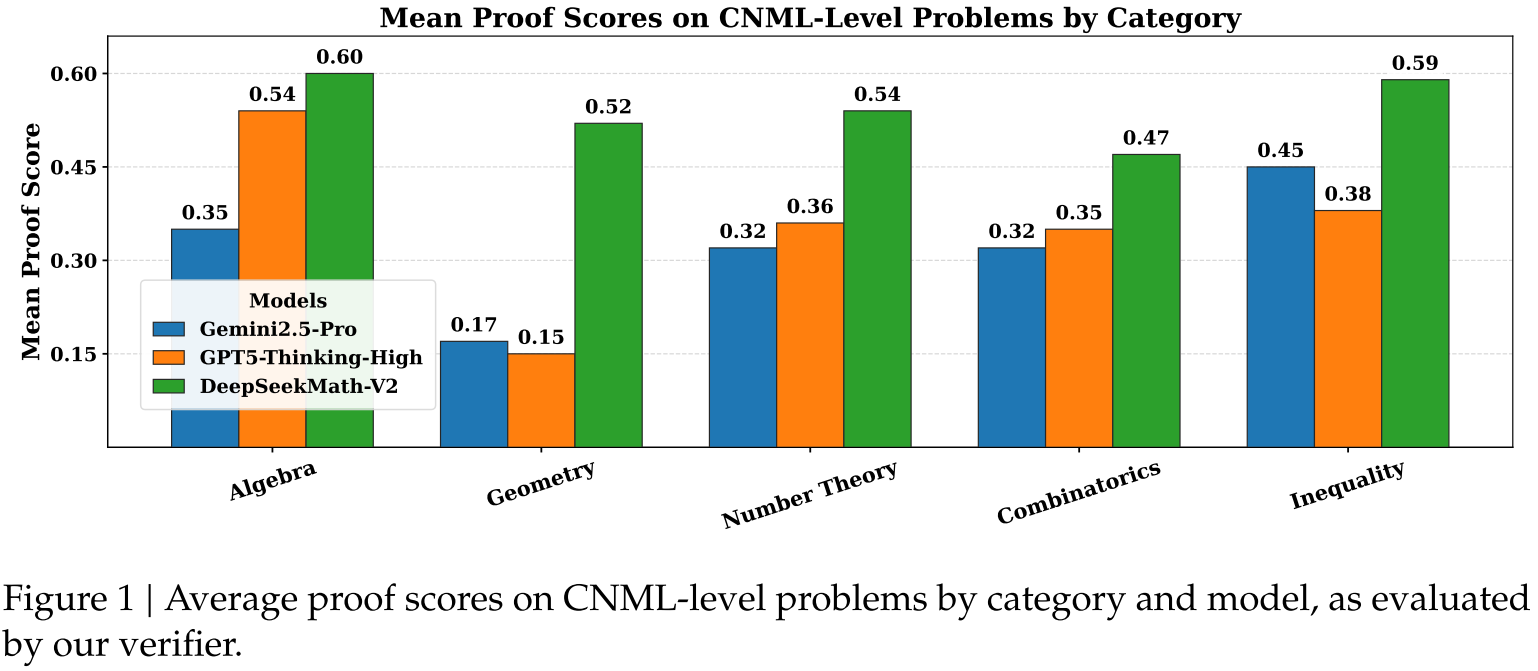
单轮生成评估聚焦模型“无迭代优化时的一次性证明能力”,核心检验其基础推理的准确性与通用性。实验中,针对内部构建的CNML级问题集(91题,覆盖代数、几何、数论、组合、不等式五大领域),为每个问题生成8份证明样本,再通过8份由最终验证器输出的分析报告进行“多数投票”,判断证明正确性(即多数分析认为正确则判定为有效)。结果显示,在所有类别的CNML级问题中,DeepSeekMath-V2的平均证明分数均持续高于GPT-5-Thinking-High(OpenAI, 2025)与Gemini 2.5-Pro(DeepMind, 2025)——例如在几何与组合数学这类对逻辑步骤严谨性要求极高的领域,模型优势尤为明显,这表明DeepSeekMath-V2在无需后续优化的情况下,已具备跨数学领域的 superior 定理证明能力,其基础推理逻辑的完整性与准确性超过当前主流大语言模型。
自验证驱动的迭代优化(Sequential Refinement with Self-Verification):复杂问题适配能力验证
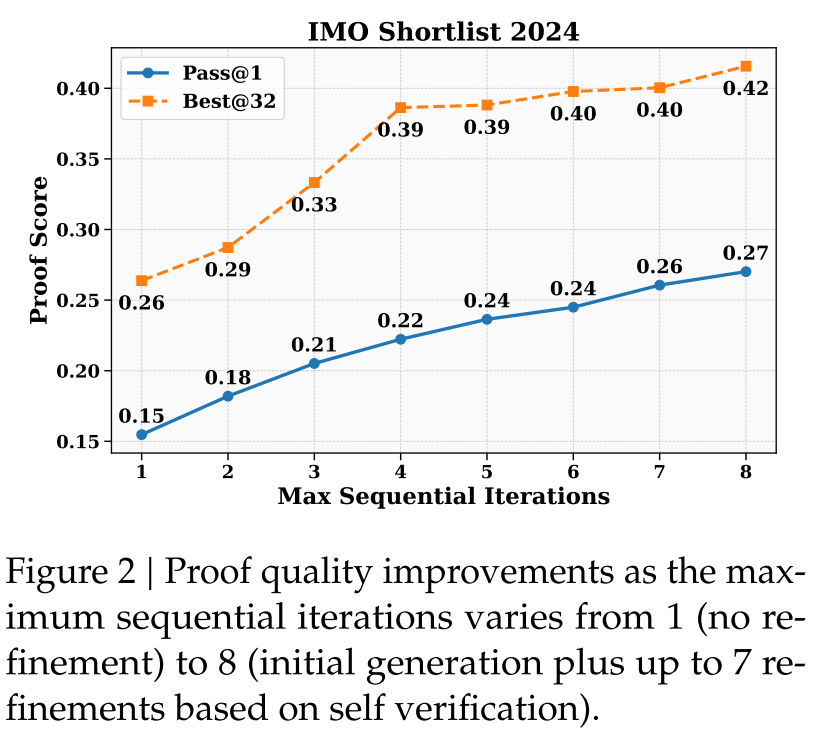
对于IMO、CMO等顶尖竞赛中的高难度问题,模型往往难以在单次生成(128K token限制内)完成全面严谨的证明,且可能因上下文长度限制无法一次性解决所有推理缺陷。为此,研究团队设计“自验证迭代优化”评估:让模型先生成证明与对应的自分析,再以“前一轮输出+自分析指出的问题”为提示,迭代重新生成证明,直至模型为自身证明打出满分或达到最大迭代次数(实验中为8次,即1次初始生成+7次优化)。
该评估以IMO Shortlist 2024(31题,IMO备选难题)为基准,启动32个独立的迭代线程,采用“Pass@1”与“Best@32”两个核心指标:Pass@1指每个线程最终输出证明的平均分数,反映模型迭代优化的整体稳定性;Best@32指每个问题在32个线程中,由模型自评分最高的证明分数,反映模型识别高质量证明的能力。结果如图2所示:一方面,Pass@1随最大迭代次数从1增加到8而显著提升,说明自验证能有效引导模型定位推理缺陷并逐步修正,迭代机制对复杂问题的证明质量提升至关重要;另一方面,Best@32的分数远高于Pass@1,且随着迭代次数增加差距进一步扩大,这证明模型能准确判断自身证明的质量——即能可靠区分“高质量证明”与“有缺陷证明”,其自评估能力可有效支撑迭代优化,避免陷入“盲目修正”的误区。
高计算搜索(High-Compute Search):顶尖竞赛与极限能力验证
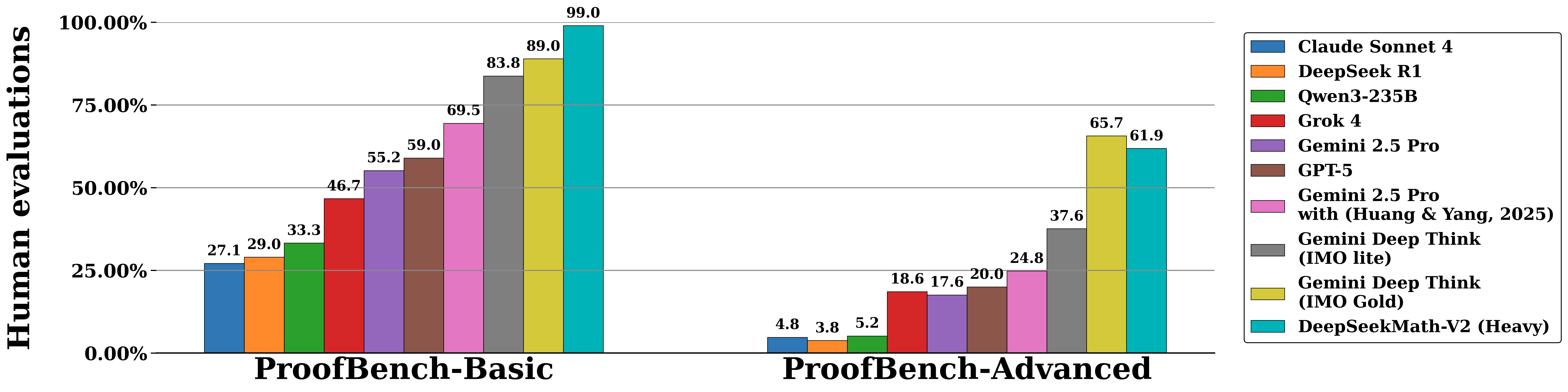
高计算搜索评估针对“最难级数学问题”(如IMO、Putnam竞赛题),通过“扩展验证计算+并行生成搜索”的方式,模拟模型在充足资源支持下的极限推理能力。具体流程为:为每个问题初始化64份证明样本,每份样本配套64份独立验证分析;每轮迭代中,筛选出64份平均验证分数最高的证明,为每份证明配对8份“优先指出问题(分数0或0.5)”的验证分析,用“证明+分析对”生成1份优化后的新证明,更新候选证明池;该过程持续至16轮迭代,或某份证明通过所有64次验证(表明高可信度正确)。 最终结果通过数学专家人工评估确认,在顶尖竞赛中表现尤为突出:在IMO 2025(6题)中,模型完整解决5题,得分率83.3%,达到金牌级标准;在CMO 2024(6题)中,完整解决4题且1题获部分分数,得分率73.8%,同样处于金牌水平;在本科阶段的Putnam 2024(12题)中,模型11题完全正确,仅1题存在微小错误,最终得分118/120,远超该竞赛人类参赛者的最高得分(90分),首次展现AI在本科顶级数学竞赛中的超越人类表现。在IMO-ProofBench基准中,模型在基础集(pre-IMO至IMO-Medium难度)的表现超过DeepMind的DeepThink(IMO Gold)模型,进阶集(IMO-Hard难度)与之一持平,且显著优于Claude Sonnet 4、Qwen3-235B等其他基线模型。值得注意的是,对于未完全解决的难题,模型通常能准确识别自身证明中的真实缺陷;而完全解决的问题则能通过所有64次验证,这进一步证明模型训练的验证器已具备评估“传统难以自动验证的复杂证明”的能力——通过高计算搜索,模型可将验证器的指导作用最大化,解决人类需耗时数小时才能完成的推理任务。

-
-
3.总结
本文围绕“自验证数学推理”这一核心方向,提出并开发了大语言模型DeepSeekMath-V2,旨在突破传统基于最终答案奖励的强化学习(RL)在数学推理中的局限。传统RL方法虽能让大语言模型在AIME、HMMT等侧重最终答案的数学竞赛中达到饱和性能,但存在“正确答案不代表正确推理”以及无法适配定理证明任务的根本性问题,而定理证明需严格的分步推导而非数值答案,且传统模型生成的证明常存在逻辑缺陷,还缺乏可靠的证明验证能力。
为解决这些问题,研究团队构建了“验证器-生成器”协同架构。首先训练证明验证器,依据“1(完整严谨)、0.5(整体正确但有细节问题)、0(致命缺陷)”的三级评分标准,采用包含格式奖励(确保输出符合指定结构)和分数奖励(基于预测分数与标注分数差距)的RL目标函数训练基础验证器;同时引入元验证机制,训练元验证器评估基础验证器分析报告的合理性,将元验证反馈融入基础验证器训练,大幅提升其可信度。 在证明生成器训练方面,以验证器评分为奖励优化生成器,同时为解决生成器自我评估宽松的问题,要求生成器生成证明后附加符合验证器标准的自分析报告,设计融合证明质量、自分析准确性与格式要求的复合奖励函数(α=0.76,β=0.24),激励生成器诚实评估并主动修正缺陷。此外,构建“验证器-生成器”协同循环,生成器性能提升产生难验证证明,验证器通过扩展计算(生成多份独立分析并结合元验证筛选有效分析)自动标注这些证明形成新训练数据,反哺验证器提升能力,进而优化生成器,且最后两轮训练中自动化标注完全替代人工。
尽管DeepSeekMath-V2证明了自验证数学推理的可行性,且LLMs可发展出复杂推理的自我评估能力,但在研究级数学问题上仍有挑战,未来需进一步推动自验证AI系统发展,以助力前沿数学研究。

















 391
391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









