




作者:黄哲威,PKU - 阶跃星辰
原文:https://zhuanlan.zhihu.com/p/21706980653
Paper:Demystifying Long Chain-of-Thought Reasoning in LLMs
Abs:https://arxiv.org/pdf/2502.03373太长不看版本,主要有四个发现
-
1. 有监督微调 SFT 可以简化训练流程,为强化学习 RL 提供更好的基础
-
2. RL 不是总能顺利提高思维链的长度和复杂性,可以通过长度奖励函数鼓励复杂推理行为
-
3. 可验证奖励信号对于稳定长链思维推理的 RL 至关重要,如果再结合使用包含噪声的、从网络提取的解决方案的数据,可以提高模型分布外任务能力
-
4. 长链推理的核心技能(如分支和错误验证)在基础模型中已经存在,但通过 RL 有效地激励这些技能以解决复杂任务需要仔细的设计。
论文所有的 Takeaway:
-
• SFT 与 Long CoT:SFT 使用 Long CoT 能达到更高的性能上限。
-
• SFT 对 RL 的初始化:SFT 使用 Long CoT 更易进一步 RL 改进。
-
• Long CoT 冷启动:高质量的 Long CoT 模式带来更好的泛化和 RL 收益。
-
• CoT 长度稳定性:CoT 长度不总是稳定扩展。
-
• 主动缩放 CoT 长度:奖励塑造可稳定和控制 CoT 长度,提高准确性。
-
• 余弦奖励超参数:余弦奖励可通过调整超参数鼓励不同长度缩放行为。
-
• 上下文窗口大小:模型可能需更多训练样本以利用更大上下文窗口。
-
• 长度奖励破解:长度奖励会被破解,但可被重复惩罚缓解。
-
• 最佳折扣因子:不同类型奖励和惩罚有不同最佳折扣因子。
-
• 使用噪声可验证数据的 SFT:添加噪声数据到 SFT 可平衡不同任务性能。
-
• 使用噪声可验证数据的 RL:过滤提示集并使用基于规则的验证器可最好地从噪声可验证数据中获取奖励信号。
介绍
这是一个对 o1 / r1 的研究工作,主要是探讨激发长链式思维 Long CoT 的一些技术选择和原理
大型语言模型(LLMs)在数学和编程等领域展示了令人印象深刻的推理能力。一种关键技术是通过链式思维(CoT)提示,引导模型在给出最终答案之前生成中间推理步骤。然而,即使有了CoT,LLMs在高度复杂的推理任务上仍然存在困难,如数学竞赛、博士级科学问答和软件工程等。
最近,OpenAI的o1模型在这些任务上取得了重大突破。这些模型的一个关键特点是能够通过扩展推理时间和使用Long CoT,包括识别和纠正错误、分解困难步骤和迭代替代方法等策略,从而实现更长、更结构化的推理过程。
为了复制o1模型的性能,一些研究尝试通过训练LLMs来生成 Long CoT。然而,对于模型如何学习和生成 Long CoT 的全面理解仍然有限。在这项研究中,我们系统地研究了 Long CoT生成的机制。具体来说,我们探索了以下内容:
-
1. 监督微调(SFT)对 Long CoT 的影响:作为实现 Long CoT 推理的最直接方法,我们分析了其缩放行为和对RL的影响,发现 Long CoT SFT允许模型达到更高的性能,并促进RL的改进。
-
2. RL驱动的链式思维扩展挑战:我们观察到RL并不总是稳定地扩展链式思维的长度和复杂性。为了解决这个问题,我们引入了一种带有重复惩罚的余弦长度缩放奖励,以稳定链式思维的增长,同时鼓励出现分支和回溯等推理行为。
-
3. 扩展可验证信号以支持 Long CoT 的 RL:可验证的奖励信号对于稳定 Long CoT 的 RL 至关重要。然而,由于高质量的可验证数据有限,扩展这些信号仍然具有挑战性。为了解决这个问题,我们探索了使用包含噪声的、从网络提取的解决方案的数据。尽管这些“银”监督信号引入了不确定性,但我们发现,通过适当的混合和过滤,它们在解决OOD(分布外)推理场景(如STEM问题解决)方面具有潜力。
-
4. Long CoT 能力的起源和 RL 挑战:核心技能如分支和错误验证在基础模型中已经存在,但通过RL有效地激励这些技能以解决复杂任务需要仔细的设计。我们研究了RL对 Long CoT 生成的激励,追踪了预训练数据中的推理模式,并讨论了测量其出现的细微差别。
Long CoT 不仅展示了比通常更大的符号长度,还展示了更复杂的行为,如:
-
• 分支和回溯:模型系统地探索多个路径(分支),并在特定路径被证明错误时返回到早期点(回溯)。
-
• 错误验证和纠正:模型检测其中间步骤中的不一致或错误,并采取纠正措施以恢复连贯性和准确性。
实验主要是在 Llama 8B 和 Qwen 7B 上做的,训练数据主要是 MATH 7500 题,后续也考虑用 WebInstruct 这样的数据,测试集用 MATH-500、AIME 2024、TheoremQA 和 MMLU-Pro-1k,算法尝试用 PPO 和 REINFORCE,关于 SFT 和 RL 基础知识这里跳过介绍。
Long CoT 实验
SFT 和 LongCoT
Llama8B 从 QWQ-32B(长链)和 Qwen2.5-72B(短链)进行蒸馏,前者持续收益,后者较快饱和
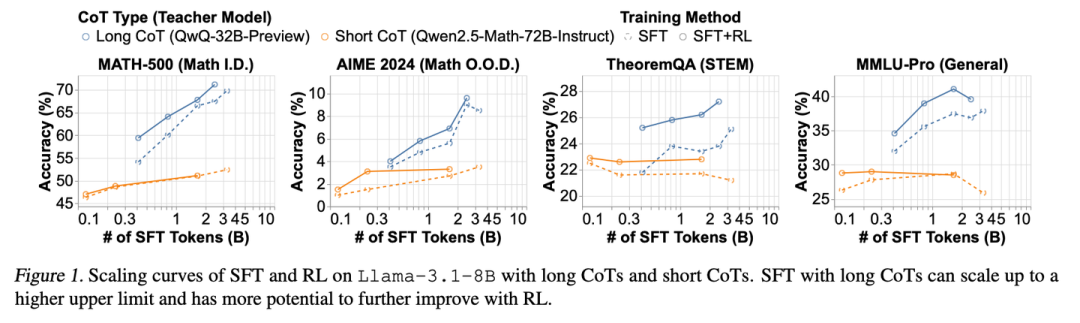
为了比较 Long CoT 和短链式思维,第一步是使模型具备相应的行为。最直接的方法是通过在链式思维数据上微调基础模型来装备模型。由于短链式思维很常见,因此通过从现有模型中拒绝采样来为它策划 SFT 数据相对简单。然而,如何获得高质量的 Long CoT 数据仍然是一个未解决的问题。
设置:为了策划 SFT 数据,对于 Long CoT,我们从 Qw
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









