







文章目录
- 环境
- mimic3-benchmarks-master\mimic3benchmark\scripts\extract_subjects
- 函数
- pd.to_datetime()
- .ix[ ]
- pandas.DataFrame.merge()
- .groupby().count().reset_index()
- DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
- pandas.DataFrame.drop_duplicates()
- pandas.DataFrame.set_index()
- pandas.DataFrame.fillna( )
- pandas.DataFrame.sort_values()
- pandas.DataFrame.pivot()
- pandas.DataFrame.sort_index()
- .unique()
代码地址: https://github.com/YerevaNN/mimic3-benchmarks
clone代码:
git clone https://github.com/YerevaNN/mimic3-benchmarks/
cd mimic3-benchmarks/
环境
numpy == 1.13.1,pandas == 0.20.3
mimic3-benchmarks-master\mimic3benchmark\scripts\extract_subjects
为每个SUBJECT_ID生成一个文件,将ICU住院信息写入data/{SUBJECT_ID}/stays.csv,诊断写入data/{SUBJECT_ID}/diagnoses.csv,事件写入data/{SUBJECT_ID}/events.csv,这大约需要一个小时。
执行命令:
python -m mimic3benchmark.scripts.extract_subjects {PATH TO MIMIC-III CSVs} data/root/
extract_subjects.py
from __future__ import absolute_import
from __future__ import print_function
import argparse
import yaml
import os
from mimic3benchmark.mimic3csv import *
from mimic3benchmark.preprocessing import add_hcup_ccs_2015_groups, make_phenotype_label_matrix
from mimic3benchmark.util import *
#参数设置
parser = argparse.ArgumentParser(description='Extract per-subject data from MIMIC-III CSV files.')
parser.add_argument('mimic3_path', type=str, help='Directory containing MIMIC-III CSV files.')
parser.add_argument('output_path', type=str, help='Directory where per-subject data should be written.')
parser.add_argument('--event_tables', '-e', type=str, nargs='+', help='Tables from which to read events.',
default=['CHARTEVENTS', 'LABEVENTS', 'OUTPUTEVENTS'])
parser.add_argument('--phenotype_definitions', '-p', type=str,
default=os.path.join(os.path.dirname(__file__), '../resources/hcup_ccs_2015_definitions.yaml'),
help='YAML file with phenotype definitions.')
parser.add_argument('--itemids_file', '-i', type=str, help='CSV containing list of ITEMIDs to keep.')
parser.add_argument('--verbose', '-v', type=int, help='Level of verbosity in output.', default=1)
parser.add_argument('--test', action='store_true', help='TEST MODE: process only 1000 subjects, 1000000 events.')
args, _ = parser.parse_known_args()
#建立输出文件路径
try:
os.makedirs(args.output_path)
except:
pass
#读取解压开的.csv文件
patients = read_patients_table(args.mimic3_path) #读取PATIENTS.csv
admits = read_admissions_table(args.mimic3_path) #读取ADMISSIONS.csv
stays = read_icustays_table(args.mimic3_path) #读取ICUSTAYS.csv
if args.verbose: #True
print('START:', stays.ICUSTAY_ID.unique().shape[0], stays.HADM_ID.unique().shape[0],
stays.SUBJECT_ID.unique().shape[0])
stays = remove_icustays_with_transfers(stays) #筛选
if args.verbose:
print('REMOVE ICU TRANSFERS:', stays.ICUSTAY_ID.unique().shape[0], stays.HADM_ID.unique().shape[0],
stays.SUBJECT_ID.unique().shape[0])
stays = merge_on_subject_admission(stays, admits)
#在表stays, admit中把'SUBJECT_ID', 'HADM_ID'相等的行合并成新的表
stays = merge_on_subject(stays, patients)
#在表stays, patients中把'SUBJECT_ID'相等的行合并成新的表
stays = filter_admissions_on_nb_icustays(stays)
#选择stays中HADM_ID只出现一次的行
if args.verbose:
print('REMOVE MULTIPLE STAYS PER ADMIT:', stays.ICUSTAY_ID.unique().shape[0], stays.HADM_ID.unique().shape[0],
stays.SUBJECT_ID.unique().shape[0])
stays = add_age_to_icustays(stays) #计算年龄,增加年龄列
stays = add_inunit_mortality_to_icustays(stays) #添加是否在ICU死亡列
stays = add_inhospital_mortality_to_icustays(stays)#添加是否在医院死亡列
stays = filter_icustays_on_age(stays) #年龄大于等于18岁的行
if args.verbose:
print('REMOVE PATIENTS AGE < 18:', stays.ICUSTAY_ID.unique().shape[0], stays.HADM_ID.unique().shape[0],
stays.SUBJECT_ID.unique().shape[0])
stays.to_csv(os.path.join(args.output_path, 'all_stays.csv'), index=False)
diagnoses = read_icd_diagnoses_table(args.mimic3_path)
#读取D_ICD_DIAGNOSES.csv和DIAGNOSES_ICD.csv,再通过ICD9_CODE拼接
diagnoses = filter_diagnoses_on_stays(diagnoses, stays)
# 将stays的'SUBJECT_ID', 'HADM_ID', 'ICUSTAY_ID'和diagnoses按'SUBJECT_ID', 'HADM_ID'拼接
diagnoses.to_csv(os.path.join(args.output_path, 'all_diagnoses.csv'), index=False)
count_icd_codes(diagnoses, output_path=os.path.join(args.output_path, 'diagnosis_counts.csv'))
#diagnoses的'ICD9_CODE'(会作为索引,和分组), 'SHORT_TITLE', 'LONG_TITLE'列,增加COUNT列
phenotypes = add_hcup_ccs_2015_groups(diagnoses, yaml.load(open(args.phenotype_definitions, 'r')))
#diagnoses增加两列'HCUP_CCS_2015','USE_IN_BENCHMARK'
make_phenotype_label_matrix(phenotypes, stays).to_csv(os.path.join(args.output_path, 'phenotype_labels.csv'),
index=False, quoting=csv.QUOTE_NONNUMERIC)
if args.test:
pat_idx = np.random.choice(patients.shape[0], size=1000)
patients = patients.iloc[pat_idx]
stays = stays.merge(patients[['SUBJECT_ID']], left_on='SUBJECT_ID', right_on='SUBJECT_ID')
args.event_tables = [args.event_tables[0]]
print('Using only', stays.shape[0], 'stays and only', args.event_tables[0], 'table')
subjects = stays.SUBJECT_ID.unique()
break_up_stays_by_subject(stays, args.output_path, subjects=subjects, verbose=args.verbose)
break_up_diagnoses_by_subject(phenotypes, args.output_path, subjects=subjects, verbose=args.verbose)
items_to_keep = set(
[int(itemid) for itemid in dataframe_from_csv(args.itemids_file)['ITEMID'].unique()]) if args.itemids_file else None
for table in args.event_tables:
read_events_table_and_break_up_by_subject(args.mimic3_path, table, args.output_path, items_to_keep=items_to_keep,
subjects_to_keep=subjects, verbose=args.verbose)
mimic3csv.py
from __future__ import absolute_import
from __future__ import print_function
import csv
import numpy as np
import os
import pandas as pd
import sys
from mimic3benchmark.util import *
#读取PATIENTS.csv
def read_patients_table(mimic3_path):
pats = dataframe_from_csv(os.path.join(mimic3_path, 'PATIENTS.csv'))
pats = pats[['SUBJECT_ID', 'GENDER', 'DOB', 'DOD']] #取这4列
pats.DOB = pd.to_datetime(pats.DOB) #将DOB列数据转换为日期时间
pats.DOD = pd.to_datetime(pats.DOD)
return pats
#读取ADMISSIONS.csv
def read_admissions_table(mimic3_path):
admits = dataframe_from_csv(os.path.join(mimic3_path, 'ADMISSIONS.csv'))
admits = admits[['SUBJECT_ID', 'HADM_ID', 'ADMITTIME', 'DISCHTIME', 'DEATHTIME', 'ETHNICITY', 'DIAGNOSIS']] #取这7列
admits.ADMITTIME = pd.to_datetime(admits.ADMITTIME)
admits.DISCHTIME = pd.to_datetime(admits.DISCHTIME)
admits.DEATHTIME = pd.to_datetime(admits.DEATHTIME)
return admits
def read_icustays_table(mimic3_path):
stays = dataframe_from_csv(os.path.join(mimic3_path, 'ICUSTAYS.csv'))
stays.INTIME = pd.to_datetime(stays.INTIME)
stays.OUTTIME = pd.to_datetime(stays.OUTTIME)
return stays
def read_icd_diagnoses_table(mimic3_path):
codes = dataframe_from_csv(os.path.join(mimic3_path, 'D_ICD_DIAGNOSES.csv'))
codes = codes[['ICD9_CODE', 'SHORT_TITLE', 'LONG_TITLE']]
diagnoses = dataframe_from_csv(os.path.join(mimic3_path, 'DIAGNOSES_ICD.csv'))
diagnoses = diagnoses.merge(codes, how='inner', left_on='ICD9_CODE', right_on='ICD9_CODE')
diagnoses[['SUBJECT_ID', 'HADM_ID', 'SEQ_NUM']] = diagnoses[['SUBJECT_ID', 'HADM_ID', 'SEQ_NUM']].astype(int)
return diagnoses
def read_events_table_by_row(mimic3_path, table):
nb_rows = {'chartevents': 330712484, 'labevents': 27854056, 'outputevents': 4349219}
reader = csv.DictReader(open(os.path.join(mimic3_path, table.upper() + '.csv'), 'r'))
for i, row in enumerate(reader):
if 'ICUSTAY_ID' not in row:
row['ICUSTAY_ID'] = ''
yield row, i, nb_rows[table.lower()]
def count_icd_codes(diagnoses, output_path=None):
codes = diagnoses[['ICD9_CODE', 'SHORT_TITLE', 'LONG_TITLE']].drop_duplicates().set_index('ICD9_CODE')
#取diagnoses的这3列并除去重复列,再将ICD9_CODE设置为索引
codes['COUNT'] = diagnoses.groupby('ICD9_CODE')['ICUSTAY_ID'].count()
#按ICD9_CODE分组,并计算每组的个数
codes.COUNT = codes.COUNT.fillna(0).astype(int)
#对COUNT列的空值填充0
codes = codes.ix[codes.COUNT > 0] #取count大于0的行
if output_path:
codes.to_csv(output_path, index_label='ICD9_CODE')
return codes.sort_values('COUNT', ascending=False).reset_index()
#codes按COUNT的大小重新排序,从大到小排
def remove_icustays_with_transfers(stays):
stays = stays.ix[(stays.FIRST_WARDID == stays.LAST_WARDID) & (stays.FIRST_CAREUNIT == stays.LAST_CAREUNIT)]
#筛选取stays的行,满足FIRST_WARDID == LAST_WARDID 和FIRST_CAREUNIT == LAST_CAREUNIT
return stays[['SUBJECT_ID', 'HADM_ID', 'ICUSTAY_ID', 'LAST_CAREUNIT', 'DBSOURCE', 'INTIME', 'OUTTIME', 'LOS']] #再取这8列
def merge_on_subject(table1, table2):
return table1.merge(table2, how='inner', left_on=['SUBJECT_ID'], right_on=['SUBJECT_ID'])
def merge_on_subject_admission(table1, table2): #stays,admits
return table1.merge(table2, how='inner', left_on=['SUBJECT_ID', 'HADM_ID'], right_on=['SUBJECT_ID', 'HADM_ID'])
#拼接table1和table2,选取两个表'SUBJECT_ID', 'HADM_ID'列相等的行
def add_age_to_icustays(stays):
stays['AGE'] = (stays.INTIME - stays.DOB).apply(lambda s: s / np.timedelta64(1, 's')) / 60./60/24/365
#获取年龄,np.timedelta64(1, 's'),1秒,除了之后时间数据变成以秒为单位
stays.ix[stays.AGE < 0, 'AGE'] = 90 # AGE小于0的置为90
return stays
def add_inhospital_mortality_to_icustays(stays):
mortality = stays.DOD.notnull() & ((stays.ADMITTIME <= stays.DOD) & (stays.DISCHTIME >= stays.DOD))
mortality = mortality | (stays.DEATHTIME.notnull() & ((stays.ADMITTIME <= stays.DEATHTIME) & (stays.DISCHTIME >= stays.DEATHTIME)))
stays['MORTALITY'] = mortality.astype(int)
stays['MORTALITY_INHOSPITAL'] = stays['MORTALITY']
return stays
def add_inunit_mortality_to_icustays(stays):
mortality = stays.DOD.notnull() & ((stays.INTIME <= stays.DOD) & (stays.OUTTIME >= stays.DOD))
mortality = mortality | (stays.DEATHTIME.notnull() & ((stays.INTIME <= stays.DEATHTIME) & (stays.OUTTIME >= stays.DEATHTIME)))
stays['MORTALITY_INUNIT'] = mortality.astype(int)
return stays
def filter_admissions_on_nb_icustays(stays, min_nb_stays=1, max_nb_stays=1):
to_keep = stays.groupby('HADM_ID').count()[['ICUSTAY_ID']].reset_index()
#按HADM_ID分组,计算每一组有多少个样本,ICUSTAY_ID现在是记录计算出的多少个样本,重新设置行索引
to_keep = to_keep.ix[(to_keep.ICUSTAY_ID >= min_nb_stays) & (to_keep.ICUSTAY_ID <= max_nb_stays)][['HADM_ID']]
#选择ICUSTAY_ID等于1的行(HADM_ID只出现一次的行),再只保留HADM_ID列
stays = stays.merge(to_keep, how='inner', left_on='HADM_ID', right_on='HADM_ID')
#拼接,得到的stays中HADM_ID都是只出现一次的
return stays
def filter_icustays_on_age(stays, min_age=18, max_age=np.inf):
stays = stays.ix[(stays.AGE >= min_age) & (stays.AGE <= max_age)]
return stays
def filter_diagnoses_on_stays(diagnoses, stays):
return diagnoses.merge(stays[['SUBJECT_ID', 'HADM_ID', 'ICUSTAY_ID']].drop_duplicates(), how='inner',
left_on=['SUBJECT_ID', 'HADM_ID'], right_on=['SUBJECT_ID', 'HADM_ID'])
def break_up_stays_by_subject(stays, output_path, subjects=None, verbose=1):
subjects = stays.SUBJECT_ID.unique() if subjects is None else subjects
nb_subjects = subjects.shape[0]
for i, subject_id in enumerate(subjects):
if verbose:
sys.stdout.write('\rSUBJECT {0} of {1}...'.format(i+1, nb_subjects))
dn = os.path.join(output_path, str(subject_id))
try:
os.makedirs(dn)
except:
pass
stays.ix[stays.SUBJECT_ID == subject_id].sort_values(by='INTIME').to_csv(os.path.join(dn, 'stays.csv'), index=False)
if verbose:
sys.stdout.write('DONE!\n')
def break_up_diagnoses_by_subject(diagnoses, output_path, subjects=None, verbose=1):
subjects = diagnoses.SUBJECT_ID.unique() if subjects is None else subjects
nb_subjects = subjects.shape[0]
for i, subject_id in enumerate(subjects):
if verbose:
sys.stdout.write('\rSUBJECT {0} of {1}...'.format(i+1, nb_subjects))
dn = os.path.join(output_path, str(subject_id))
try:
os.makedirs(dn)
except:
pass
diagnoses.ix[diagnoses.SUBJECT_ID == subject_id].sort_values(by=['ICUSTAY_ID', 'SEQ_NUM']).to_csv(os.path.join(dn, 'diagnoses.csv'), index=False)
if verbose:
sys.stdout.write('DONE!\n')
def read_events_table_and_break_up_by_subject(mimic3_path, table, output_path, items_to_keep=None, subjects_to_keep=None, verbose=1):
obs_header = ['SUBJECT_ID', 'HADM_ID', 'ICUSTAY_ID', 'CHARTTIME', 'ITEMID', 'VALUE', 'VALUEUOM']
if items_to_keep is not None:
items_to_keep = set([str(s) for s in items_to_keep])
if subjects_to_keep is not None:
subjects_to_keep = set([str(s) for s in subjects_to_keep])
class DataStats(object):
def __init__(self):
self.curr_subject_id = ''
self.last_write_no = 0
self.last_write_nb_rows = 0
self.last_write_subject_id = ''
self.curr_obs = []
data_stats = DataStats()
def write_current_observations():
data_stats.last_write_no += 1
data_stats.last_write_nb_rows = len(data_stats.curr_obs)
data_stats.last_write_subject_id = data_stats.curr_subject_id
dn = os.path.join(output_path, str(data_stats.curr_subject_id))
try:
os.makedirs(dn)
except:
pass
fn = os.path.join(dn, 'events.csv')
if not os.path.exists(fn) or not os.path.isfile(fn):
f = open(fn, 'w')
f.write(','.join(obs_header) + '\n')
f.close()
w = csv.DictWriter(open(fn, 'a'), fieldnames=obs_header, quoting=csv.QUOTE_MINIMAL)
w.writerows(data_stats.curr_obs)
data_stats.curr_obs = []
for row, row_no, nb_rows in read_events_table_by_row(mimic3_path, table):
if verbose and (row_no % 100000 == 0):
if data_stats.last_write_no != '':
sys.stdout.write('\rprocessing {0}: ROW {1} of {2}...last write '
'({3}) {4} rows for subject {5}'.format(table, row_no, nb_rows,
data_stats.last_write_no,
data_stats.last_write_nb_rows,
data_stats.last_write_subject_id))
else:
sys.stdout.write('\rprocessing {0}: ROW {1} of {2}...'.format(table, row_no, nb_rows))
if (subjects_to_keep is not None) and (row['SUBJECT_ID'] not in subjects_to_keep):
continue
if (items_to_keep is not None) and (row['ITEMID'] not in items_to_keep):
continue
row_out = {'SUBJECT_ID': row['SUBJECT_ID'],
'HADM_ID': row['HADM_ID'],
'ICUSTAY_ID': '' if 'ICUSTAY_ID' not in row else row['ICUSTAY_ID'],
'CHARTTIME': row['CHARTTIME'],
'ITEMID': row['ITEMID'],
'VALUE': row['VALUE'],
'VALUEUOM': row['VALUEUOM']}
if data_stats.curr_subject_id != '' and data_stats.curr_subject_id != row['SUBJECT_ID']:
write_current_observations()
data_stats.curr_obs.append(row_out)
data_stats.curr_subject_id = row['SUBJECT_ID']
if data_stats.curr_subject_id != '':
write_current_observations()
if verbose:
sys.stdout.write('\rfinished processing {0}: ROW {1} of {2}...last write '
'({3}) {4} rows for subject {5}...DONE!\n'.format(table, row_no, nb_rows,
data_stats.last_write_no,
data_stats.last_write_nb_rows,
data_stats.last_write_subject_id))
preprocessing.py
from __future__ import absolute_import
from __future__ import print_function
import numpy as np
import re
from pandas import DataFrame, Series
from mimic3benchmark.util import *
###############################
# Non-time series preprocessing
###############################
g_map = {'F': 1, 'M': 2, 'OTHER': 3, '': 0}
def transform_gender(gender_series):
global g_map
return { 'Gender': gender_series.fillna('').apply(lambda s: g_map[s] if s in g_map else g_map['OTHER']) }
e_map = {'ASIAN': 1,
'BLACK': 2,
'CARIBBEAN ISLAND': 2,
'HISPANIC': 3,
'SOUTH AMERICAN': 3,
'WHITE': 4,
'MIDDLE EASTERN': 4,
'PORTUGUESE': 4,
'AMERICAN INDIAN': 0,
'NATIVE HAWAIIAN': 0,
'UNABLE TO OBTAIN': 0,
'PATIENT DECLINED TO ANSWER': 0,
'UNKNOWN': 0,
'OTHER': 0,
'': 0}
def transform_ethnicity(ethnicity_series):
global e_map
def aggregate_ethnicity(ethnicity_str):
return ethnicity_str.replace(' OR ', '/').split(' - ')[0].split('/')[0]
ethnicity_series = ethnicity_series.apply(aggregate_ethnicity)
return {'Ethnicity': ethnicity_series.fillna('').apply(lambda s: e_map[s] if s in e_map else e_map['OTHER'])}
def assemble_episodic_data(stays, diagnoses):
data = {'Icustay': stays.ICUSTAY_ID, 'Age': stays.AGE, 'Length of Stay': stays.LOS,
'Mortality': stays.MORTALITY}
data.update(transform_gender(stays.GENDER))
data.update(transform_ethnicity(stays.ETHNICITY))
data['Height'] = np.nan
data['Weight'] = np.nan
data = DataFrame(data).set_index('Icustay')
data = data[['Ethnicity', 'Gender', 'Age', 'Height', 'Weight', 'Length of Stay', 'Mortality']]
return data.merge(extract_diagnosis_labels(diagnoses), left_index=True, right_index=True)
diagnosis_labels = ['4019', '4280', '41401', '42731', '25000', '5849', '2724', '51881', '53081', '5990', '2720',
'2859', '2449', '486', '2762', '2851', '496', 'V5861', '99592', '311', '0389', '5859', '5070',
'40390', '3051', '412', 'V4581', '2761', '41071', '2875', '4240', 'V1582', 'V4582', 'V5867',
'4241', '40391', '78552', '5119', '42789', '32723', '49390', '9971', '2767', '2760', '2749',
'4168', '5180', '45829', '4589', '73300', '5845', '78039', '5856', '4271', '4254', '4111',
'V1251', '30000', '3572', '60000', '27800', '41400', '2768', '4439', '27651', 'V4501', '27652',
'99811', '431', '28521', '2930', '7907', 'E8798', '5789', '79902', 'V4986', 'V103', '42832',
'E8788', '00845', '5715', '99591', '07054', '42833', '4275', '49121', 'V1046', '2948', '70703',
'2809', '5712', '27801', '42732', '99812', '4139', '3004', '2639', '42822', '25060', 'V1254',
'42823', '28529', 'E8782', '30500', '78791', '78551', 'E8889', '78820', '34590', '2800', '99859',
'V667', 'E8497', '79092', '5723', '3485', '5601', '25040', '570', '71590', '2869', '2763', '5770',
'V5865', '99662', '28860', '36201', '56210']
def extract_diagnosis_labels(diagnoses):
global diagnosis_labels
diagnoses['VALUE'] = 1
labels = diagnoses[['ICUSTAY_ID', 'ICD9_CODE', 'VALUE']].drop_duplicates().pivot(index='ICUSTAY_ID', columns='ICD9_CODE', values='VALUE').fillna(0).astype(int)
for l in diagnosis_labels:
if l not in labels:
labels[l] = 0
labels = labels[diagnosis_labels]
return labels.rename_axis(dict(zip(diagnosis_labels, ['Diagnosis ' + d for d in diagnosis_labels])), axis=1)
def add_hcup_ccs_2015_groups(diagnoses, definitions):
def_map = {}
for dx in definitions:
for code in definitions[dx]['codes']:
def_map[code] = (dx, definitions[dx]['use_in_benchmark'])
diagnoses['HCUP_CCS_2015'] = diagnoses.ICD9_CODE.apply(lambda c: def_map[c][0] if c in def_map else None)
diagnoses['USE_IN_BENCHMARK'] = diagnoses.ICD9_CODE.apply(lambda c: int(def_map[c][1]) if c in def_map else None)
return diagnoses
def make_phenotype_label_matrix(phenotypes, stays=None):
phenotypes = phenotypes[['ICUSTAY_ID', 'HCUP_CCS_2015']].ix[phenotypes.USE_IN_BENCHMARK > 0].drop_duplicates()
phenotypes['VALUE'] = 1
phenotypes = phenotypes.pivot(index='ICUSTAY_ID', columns='HCUP_CCS_2015', values='VALUE')
#以ICUSTAY_ID作为索引,以HCUP_CCS_2015作为列名,VALUE作为值
if stays is not None:
phenotypes = phenotypes.ix[stays.ICUSTAY_ID.sort_values()]
return phenotypes.fillna(0).astype(int).sort_index(axis=0).sort_index(axis=1)
#
###################################
# Time series preprocessing
###################################
def read_itemid_to_variable_map(fn, variable_column='LEVEL2'):
var_map = dataframe_from_csv(fn, index_col=None).fillna('').astype(str)
# var_map[variable_column] = var_map[variable_column].apply(lambda s: s.lower())
var_map.COUNT = var_map.COUNT.astype(int)
var_map = var_map.ix[(var_map[variable_column] != '') & (var_map.COUNT > 0)]
var_map = var_map.ix[(var_map.STATUS == 'ready')]
var_map.ITEMID = var_map.ITEMID.astype(int)
var_map = var_map[[variable_column, 'ITEMID', 'MIMIC LABEL']].set_index('ITEMID')
return var_map.rename_axis({variable_column: 'VARIABLE', 'MIMIC LABEL': 'MIMIC_LABEL'}, axis=1)
def map_itemids_to_variables(events, var_map):
return events.merge(var_map, left_on='ITEMID', right_index=True)
def read_variable_ranges(fn, variable_column='LEVEL2'):
columns = [variable_column, 'OUTLIER LOW', 'VALID LOW', 'IMPUTE', 'VALID HIGH', 'OUTLIER HIGH']
to_rename = dict(zip(columns, [c.replace(' ', '_') for c in columns]))
to_rename[variable_column] = 'VARIABLE'
var_ranges = dataframe_from_csv(fn, index_col=None)
# var_ranges = var_ranges[variable_column].apply(lambda s: s.lower())
var_ranges = var_ranges[columns]
var_ranges.rename_axis(to_rename, axis=1, inplace=True)
var_ranges = var_ranges.drop_duplicates(subset='VARIABLE', keep='first')
var_ranges.set_index('VARIABLE', inplace=True)
return var_ranges.ix[var_ranges.notnull().all(axis=1)]
def remove_outliers_for_variable(events, variable, ranges):
if variable not in ranges.index:
return events
idx = (events.VARIABLE == variable)
V = events.VALUE[idx]
V.ix[V < ranges.OUTLIER_LOW[variable]] = np.nan
V.ix[V > ranges.OUTLIER_HIGH[variable]] = np.nan
V.ix[V < ranges.VALID_LOW[variable]] = ranges.VALID_LOW[variable]
V.ix[V > ranges.VALID_HIGH[variable]] = ranges.VALID_HIGH[variable]
events.ix[idx, 'VALUE'] = V
return events
# SBP: some are strings of type SBP/DBP
def clean_sbp(df):
v = df.VALUE.astype(str)
idx = v.apply(lambda s: '/' in s)
v.ix[idx] = v[idx].apply(lambda s: re.match('^(\d+)/(\d+)$', s).group(1))
return v.astype(float)
def clean_dbp(df):
v = df.VALUE.astype(str)
idx = v.apply(lambda s: '/' in s)
v.ix[idx] = v[idx].apply(lambda s: re.match('^(\d+)/(\d+)$', s).group(2))
return v.astype(float)
# CRR: strings with brisk, <3 normal, delayed, or >3 abnormal
def clean_crr(df):
v = Series(np.zeros(df.shape[0]), index=df.index)
v[:] = np.nan
# when df.VALUE is empty, dtype can be float and comparision with string
# raises an exception, to fix this we change dtype to str
df.VALUE = df.VALUE.astype(str)
v.ix[(df.VALUE == 'Normal <3 secs') | (df.VALUE == 'Brisk')] = 0
v.ix[(df.VALUE == 'Abnormal >3 secs') | (df.VALUE == 'Delayed')] = 1
return v
# FIO2: many 0s, some 0<x<0.2 or 1<x<20
def clean_fio2(df):
v = df.VALUE.astype(float)
''' The line below is the correct way of doing the cleaning, since we will not compare 'str' to 'float'.
If we use that line it will create mismatches from the data of the paper in ~50 ICU stays.
The next releases of the benchmark should use this line.
'''
# idx = df.VALUEUOM.fillna('').apply(lambda s: 'torr' not in s.lower()) & (v>1.0)
''' The line below was used to create the benchmark dataset that the paper used. Note this line will not work
in python 3, since it may try to compare 'str' to 'float'.
'''
# idx = df.VALUEUOM.fillna('').apply(lambda s: 'torr' not in s.lower()) & (df.VALUE > 1.0)
''' The two following lines implement the code that was used to create the benchmark dataset that the paper used.
This works with both python 2 and python 3.
'''
is_str = np.array(map(lambda x: type(x) == str, list(df.VALUE)), dtype=np.bool)
idx = df.VALUEUOM.fillna('').apply(lambda s: 'torr' not in s.lower()) & (is_str | (~is_str & (v > 1.0)))
v.ix[idx] = v[idx] / 100.
return v
# GLUCOSE, PH: sometimes have ERROR as value
def clean_lab(df):
v = df.VALUE
idx = v.apply(lambda s: type(s) is str and not re.match('^(\d+(\.\d*)?|\.\d+)$', s))
v.ix[idx] = np.nan
return v.astype(float)
# O2SAT: small number of 0<x<=1 that should be mapped to 0-100 scale
def clean_o2sat(df):
# change "ERROR" to NaN
v = df.VALUE
idx = v.apply(lambda s: type(s) is str and not re.match('^(\d+(\.\d*)?|\.\d+)$', s))
v.ix[idx] = np.nan
v = v.astype(float)
idx = (v <= 1)
v.ix[idx] = v[idx] * 100.
return v
# Temperature: map Farenheit to Celsius, some ambiguous 50<x<80
def clean_temperature(df):
v = df.VALUE.astype(float)
idx = df.VALUEUOM.fillna('').apply(lambda s: 'F' in s.lower()) | df.MIMIC_LABEL.apply(lambda s: 'F' in s.lower()) | (v >= 79)
v.ix[idx] = (v[idx] - 32) * 5. / 9
return v
# Weight: some really light/heavy adults: <50 lb, >450 lb, ambiguous oz/lb
# Children are tough for height, weight
def clean_weight(df):
v = df.VALUE.astype(float)
# ounces
idx = df.VALUEUOM.fillna('').apply(lambda s: 'oz' in s.lower()) | df.MIMIC_LABEL.apply(lambda s: 'oz' in s.lower())
v.ix[idx] = v[idx] / 16.
# pounds
idx = idx | df.VALUEUOM.fillna('').apply(lambda s: 'lb' in s.lower()) | df.MIMIC_LABEL.apply(lambda s: 'lb' in s.lower())
v.ix[idx] = v[idx] * 0.453592
return v
# Height: some really short/tall adults: <2 ft, >7 ft)
# Children are tough for height, weight
def clean_height(df):
v = df.VALUE.astype(float)
idx = df.VALUEUOM.fillna('').apply(lambda s: 'in' in s.lower()) | df.MIMIC_LABEL.apply(lambda s: 'in' in s.lower())
v.ix[idx] = np.round(v[idx] * 2.54)
return v
# ETCO2: haven't found yet
# Urine output: ambiguous units (raw ccs, ccs/kg/hr, 24-hr, etc.)
# Tidal volume: tried to substitute for ETCO2 but units are ambiguous
# Glascow coma scale eye opening
# Glascow coma scale motor response
# Glascow coma scale total
# Glascow coma scale verbal response
# Heart Rate
# Respiratory rate
# Mean blood pressure
clean_fns = {
'Capillary refill rate': clean_crr,
'Diastolic blood pressure': clean_dbp,
'Systolic blood pressure': clean_sbp,
'Fraction inspired oxygen': clean_fio2,
'Oxygen saturation': clean_o2sat,
'Glucose': clean_lab,
'pH': clean_lab,
'Temperature': clean_temperature,
'Weight': clean_weight,
'Height': clean_height
}
def clean_events(events):
global clean_fns
for var_name, clean_fn in clean_fns.items():
idx = (events.VARIABLE == var_name)
try:
events.ix[idx, 'VALUE'] = clean_fn(events.ix[idx])
except Exception as e:
print("Exception in clean_events:", clean_fn.__name__, e)
print("number of rows:", np.sum(idx))
print("values:", events.ix[idx])
exit()
return events.ix[events.VALUE.notnull()]
函数
pd.to_datetime()
功能:将参数设置为日期格式
import pandas as pd
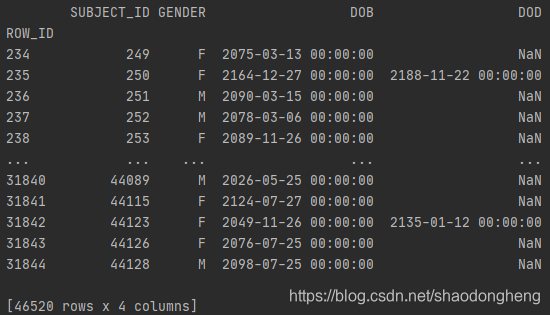
pats= pd.read_csv('F:\MIMIC\MIMIC_III\MIMIC_III\PATIENTS.CSv',header=0, index_col=0)
pats = pats[['SUBJECT_ID', 'GENDER', 'DOB', 'DOD']]
print(pats )
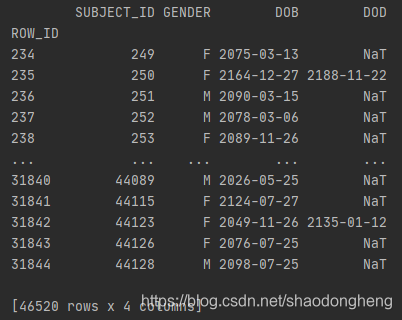
pats.DOB = pd.to_datetime(pats.DOB) # 将参数转换为日期时间
pats.DOD = pd.to_datetime(pats.DOD)
print(pats )
将参数设置为日期格式(时间就没有了),将无效参数(NaN)设置为NaT
.ix[ ]
按索引取值,赋值
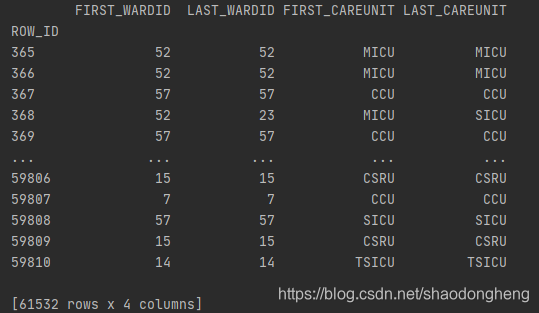
stays = pd.read_csv('F:\MIMIC\MIMIC_III\MIMIC_III\ICUSTAYS.CSV',header=0, index_col=0)
stays.INTIME = pd.to_datetime(stays.INTIME)
stays.OUTTIME = pd.to_datetime(stays.OUTTIME)
print(stays[['FIRST_WARDID', 'LAST_WARDID', 'FIRST_CAREUNIT', 'LAST_CAREUNIT']])
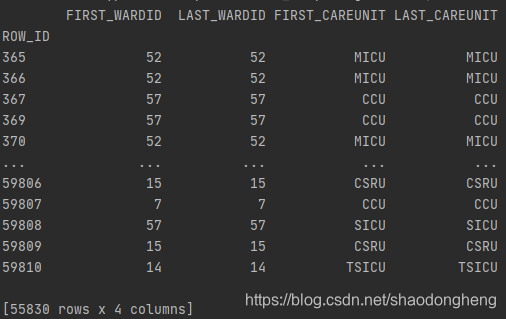
stays = stays.loc[(stays.FIRST_WARDID == stays.LAST_WARDID) & (stays.FIRST_CAREUNIT == stays.LAST_CAREUNIT)]
print(stays[['FIRST_WARDID', 'LAST_WARDID', 'FIRST_CAREUNIT', 'LAST_CAREUNIT']])
按索引取行
pandas.DataFrame.merge()
拼接数据表。
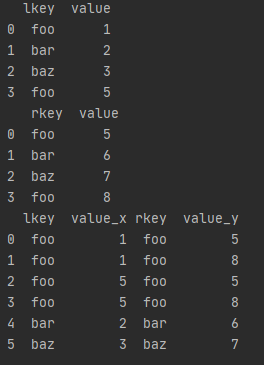
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo'],
'value': [1, 2, 3, 5]})
df2 = pd.DataFrame({'rkey': ['foo', 'bar', 'baz', 'foo'],
'value': [5, 6, 7, 8]})
print(df1,'\n', df2)
print(df1.merge(df2, left_on='lkey', right_on='rkey'))
left_on左边表的拼接主键,right_on右边表的拼接主键。选择主键值相等的行,重新组合,拼成一个新表。
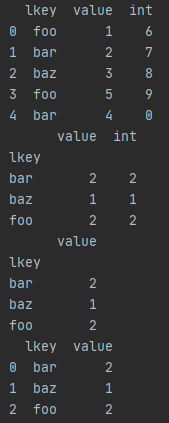
.groupby().count().reset_index()
df1 = pd.DataFrame({'lkey': ['foo', 'bar', 'baz', 'foo', 'bar'],
'value': [1, 2, 3, 5, 4],
'int':[6, 7, 8, 9, 0]})
print(df1)
print(df1.groupby(['lkey']).count()) #对df1按lkey的不同值分组,计算每一组有多少行
print(df1.groupby(['lkey']).count()[['value']])# 取value列
print(df1.groupby(['lkey']).count()[['value']].reset_index())#重新设置索引
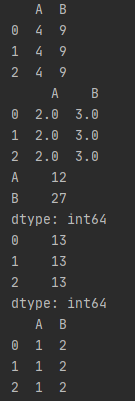
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
该函数最有用的是第一个参数,这个参数是函数。
这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
print(df)
df1 = df.apply(np.sqrt)
print(df1)
df2 = df.apply(np.sum, axis=0)
print(df2)
df3 = df.apply(np.sum, axis=1)
print(df3)
df4 = df.apply(lambda x: [1, 2], axis=1)
print(df4)
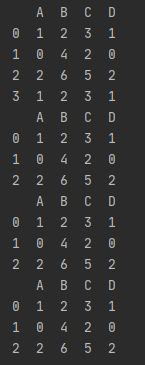
pandas.DataFrame.drop_duplicates()
去除重复值的行。
data = {
'A':[1,0,2,1],
'B':[2,4,6,2],
'C':[3,2,5,3],
'D':[1,0,2,1]
}
df = pd.DataFrame(data=data)
print(df)
df1 = df.drop_duplicates()
print(df1)
df2 = df.drop_duplicates(['A']) #按A列去除重复行
print(df2)
df3 = df.drop_duplicates(['B','C'])
print(df3)
pandas.DataFrame.set_index()
将已有的列设置为索引。
data = {
'a':['bar', 'bar', 'foo', 'foo'],
'b':['one', 'two', 'one', 'two'],
'c':['z', 'y', 'x', 'w'],
'd':[1.0, 2.0, 3.0, 4.0]
}
df = pd.DataFrame(data=data)
print(df)
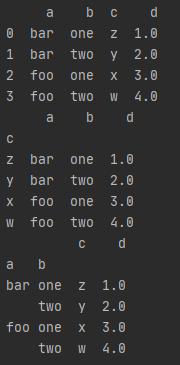
df1 = df.set_index('c') #将c列设置为索引
print(df1)
df2 = df.set_index(['a', 'b']) #将a,b列设置为索引
print(df2)
pandas.DataFrame.fillna( )
使用指定的方法填充NA / NaN值。
df = pd.DataFrame([[np.nan,2,np.nan,0],
[3,4,np.nan,1],
[np.nan,np.nan,np.nan,5],
[np.nan,3,np.nan,4]],
columns=list('ABCD'))
print(df)
df1 = df.fillna(0) #使用0填充
print(df1)

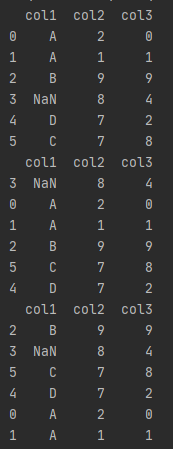
pandas.DataFrame.sort_values()
DataFrame.sort_values(self, by, axis=0, ascending=True, inplace=False, kind=‘quicksort’, na_position=‘last’, ignore_index=False)
可以将数据集依照某个字段中的数据进行排序,该函数即可根据指定列数据也可根据指定行的数据排序。
ascending:是否按指定列的数组升序排列,默认为True,即升序排列。
na_position:{‘first’,‘last’},设定缺失值的显示位置。
df=pd.DataFrame({'col1':['A','A','B',np.nan,'D','C'],
'col2':[2,1,9,8,7,7],
'col3':[0,1,9,4,2,8]
})
print(df)
print(df.sort_values(by=['col1'],na_position='first'))#依据第一列排序,并将该列空值放在首位
print(df.sort_values(by=['col2','col3'],ascending=False))#依据第二、三列,数值降序排序
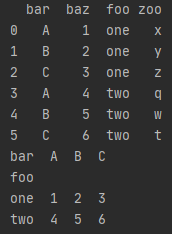
pandas.DataFrame.pivot()
返回按给定索引/列值组织的重新配置的数据格式。
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two',
'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
print(df)
df1 = df.pivot(index='foo', columns='bar', values='baz')
print(df1)
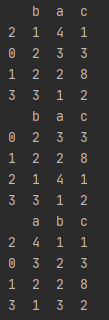
pandas.DataFrame.sort_index()
默认根据行标签对所有行排序,或根据列标签对所有列排序,或根据指定某列或某几列对行排序。
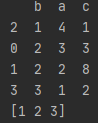
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3],columns=['b','a','c'])
print(df)
df1 = df.sort_index() #默认按“行标签”升序排序,或df.sort_index(axis=0, ascending=True)
print(df1)
#先按b列降序,再按a列升序排序
df2 = df.sort_index(axis=1) #按“列标签”升序排序
print(df2)
.unique()
以 数组形式(numpy.ndarray)返回列的所有唯一值(特征的所有唯一值)。
df = pd.DataFrame({'b':[1,2,2,3],'a':[4,3,2,1],'c':[1,3,8,2]},index=[2,0,1,3],columns=['b','a','c'])
print(df)
print(df['b'].unique())

















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









