







LangChain其它五类组件详解(5)——检索器(Retrievers)
本章目录如下:
- 《LangChain其它五类组件详解(1)—— 文档加载器(Document loaders)》
- 《LangChain其它五类组件详解(2)—— 文本分割器(Text splitters)》
- 《LangChain其它五类组件详解(3)—— 嵌入模型(Embedding models)》
- 《LangChain其它五类组件详解(4)—— 向量存储(Vector stores)》
- 《LangChain其它五类组件详解(5)—— 检索器(Retrievers)》
- 《LangChain其它五类组件详解(6)—— 查询分析(Query analysis)》
本篇摘要
本章主要详细介绍LangChain的其它五类组件:Document loaders/Text splitters/Embedding models/Vector stores/Retrievers,详细讲解技术细节后给出使用样例。
15. LangChain其它五类组件详解
前面介绍了LangChain的组件Chat models和Tools/Toolkits,本章按照项目中的应用顺序,依次介绍其余四种主要组件Document loaders、Embedding models、Vector stores、Retrievers,再加入非主要但常用的Text splitters,而查询分析(Query analysis)是对Retrievers概念的补充,在讲解原理后对每个组件给出简单示例。
15.5 检索器(Retrievers)
检索器(Retrievers)是本章非常重要的一节,本节将从检索器概念、接口、常见检索器类型、高级检索模式及查询分析等方面介绍检索器(Retrievers)。
15.5.1 检索器概述
检索器是一种接口,根据非结构化查询返回文档,它不需存储文档,只需返回(或检索)它们。检索器可以从向量存储创建,但比向量存储更通用,甚至广泛到维基百科搜索和Amazon Kendra。检索器接受字符串查询作为输入,并返回一个文档列表作为输出,有关如何使用检索器的具体信息,请参阅相关的操作指南:how-to: Retrievers。
需要注意的是,所有向量存储都可以转换为检索器。有关可用的向量存储,请参阅向量存储集成文档,它列出了通过子类化BaseRetriever实现的自定义检索器。
15.5.2 创建检索器
创建检索器非常简单,检索器的唯一要求是能够接受查询并返回文档。具体来说,LangChain的检索器类仅要求实现 _get_relevant_documents方法,该方法接受一个query: str并返回与查询最相关的Document对象列表;其用于获取相关文档的底层逻辑由该方法指定,可以是应用程序中最有效的任何逻辑。让我们实现一个小型检索器,它返回所有文本包含用户查询中文本的文档。示例如下:
from typing import List
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_core.retrievers import BaseRetriever
class ToyRetriever(BaseRetriever):
"""A toy retriever that contains the top k documents that contain the user query.
This retriever only implements the sync method _get_relevant_documents.
If the retriever were to involve file access or network access, it could benefit
from a native async implementation of `_aget_relevant_documents`.
As usual, with Runnables, there's a default async implementation that's provided
that delegates to the sync implementation running on another thread.
"""
documents: List[Document]
"""List of documents to retrieve from."""
k: int
"""Number of top results to return"""
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""Sync implementations for retriever."""
matching_documents = []
for document in documents:
if len(matching_documents) > self.k:
return matching_documents
if query.lower() in document.page_content.lower():
matching_documents.append(document)
return matching_documents
# Optional: Provide a more efficient native implementation by overriding
# _aget_relevant_documents
# async def _aget_relevant_documents(
# self, query: str, *, run_manager: AsyncCallbackManagerForRetrieverRun
# ) -> List[Document]:
# """Asynchronously get documents relevant to a query.
# Args:
# query: String to find relevant documents for
# run_manager: The callbacks handler to use
# Returns:
# List of relevant documents
# """
检索器创建方法可参考:How to create a custom Retriever。
15.5.3 接口方法
现在存在许多不同类型的检索系统,包括向量存储、图数据库和关系数据库。随着大型语言模型的普及,检索系统已成为人工智能应用(例如RAG)中的重要组成部分。由于其重要性和多样性,LangChain提供了一个统一的接口,使用自然语言查询检索文档,用于与不同类型的检索系统交互。
LangChain检索器是一个可运行对象(runnable),这是LangChain组件的标准接口。这意味着它具有一些常用方法如invoke,用于与其交互,可以通过查询调用检索器:
retriever = ToyRetriever(documents=documents, k=3)
docs = retriever.invoke(query)
检索器返回一个Document对象列表,这些对象具有两个属性:
page_content:文档的内容,目前为字符串;
metadata:与此文档关联的任意元数据(例如文档 ID、文件名、来源等)。
15.5.4 常见检索器类型
尽管检索器接口非常灵活,但以下几种常见的检索系统经常被使用,包括搜索API检索器、关系数据库或图数据库检索器、词汇搜索检索器和向量存储检索器。
1. 搜索API检索器
需要注意的是,检索器并不需要实际存储文档。例如,我们可以在搜索API之上构建检索器,这些API只需返回搜索结果!使用方法请参阅LangChain与Amazon Kendra 或Wikipedia Search的检索器集成。示例如下:
# %pip install --upgrade --quiet boto3
from langchain_community.retrievers import WikipediaRetriever
retriever = WikipediaRetriever()
docs = retriever.invoke("TOKYO GHOUL")
print(docs[0].page_content[:400])
2. 关系数据库或图数据库检索器
检索器可以构建在关系数据库或图数据库之上,在这些情况下,从自然语言构建结构化查询的查询分析技术(见下)至关重要。例如使用text-to-SQL转换来为SQL数据库构建检索器,这使得自然语言查询(字符串)检索器可以在幕后转换为SQL查询,而text-to-Cypher则将自然语言查询转换为Cypher查询。延伸阅读:
- 如何使用SQL数据库和text-to-SQL构建检索器:Build a Question/Answering system over SQL data;
- 如何使用图数据库和文本到text-to-Cypher构建检索器:Build a Question Answering application over a Graph Database。
3. 词汇搜索检索器
正如我们在检索的概念回顾中所讨论的,许多搜索引擎基于单词匹配,它们将查询中的单词与被搜索文档中的单词进行匹配,比如BM25和TF-IDF就是两种流行的词汇搜索算法。因此LangChain提供了许多基于流行的词汇搜索算法/引擎的检索器,比如:
- BM25检索器集成:BM25 Retriever;
- TF-IDF检索器集成:TF-IDF Retriever;
- Elasticsearch检索器集成:ElasticsearchRetriever。
4. 向量存储检索器
向量存储即本章讲到的Vector stores,它是一种强大且高效的非结构化数据索引和检索方式,通过调用as_retriever() 方法,向量存储就可以用作检索器:
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
15.5.5 高级检索模式
除了上述的四种常见类型,还有一些高级检索模式,包括集成检索器、保留原文档、多向量检索器与父文档检索器。
1. 集成(Ensemble)
由于检索器接口非常简单(给定搜索查询后返回一个文档对象列表),因此可以使用集成技术将多个检索器结合起来,它在使用多个擅长查找不同类型文档的检索器时特别有用。利用集成接口EnsembleRetriever,可以轻松创建一个集成检索器将多个检索器与线性加权分数结合起来,示例如下:
from langchain.retrievers import EnsembleRetriever
ensemble_retriever = EnsembleRetriever(retrievers=[retriever1, retriever2], weights=[0.5, 0.5])
在集成时,我们如何结合多个检索器的搜索结果?这引出了**重新排序(Re-ranking)**的概念,它采用多个检索器的输出,并使用更复杂的算法(如 Reciprocal Rank Fusion, RRF)将它们结合起来。关于互惠排名融合RRF请参阅:Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods。
2. 设置保留源文档
许多检索器利用某种索引使文档易于搜索,索引过程可能包括一个转换步骤(例如向量存储通常使用文档分割)。无论使用何种转换,保留转换后文档与原始文档之间的链接都非常有用,这使得检索器能够溯源原始文档。我们进行如下设置即可实现原文档保留:
# 示例:保留源文档链接
retriever = VectorStoreRetriever(vector_store, source_key="original_document_id")
此时将创建Docstore存储原始文档,示意图如下:
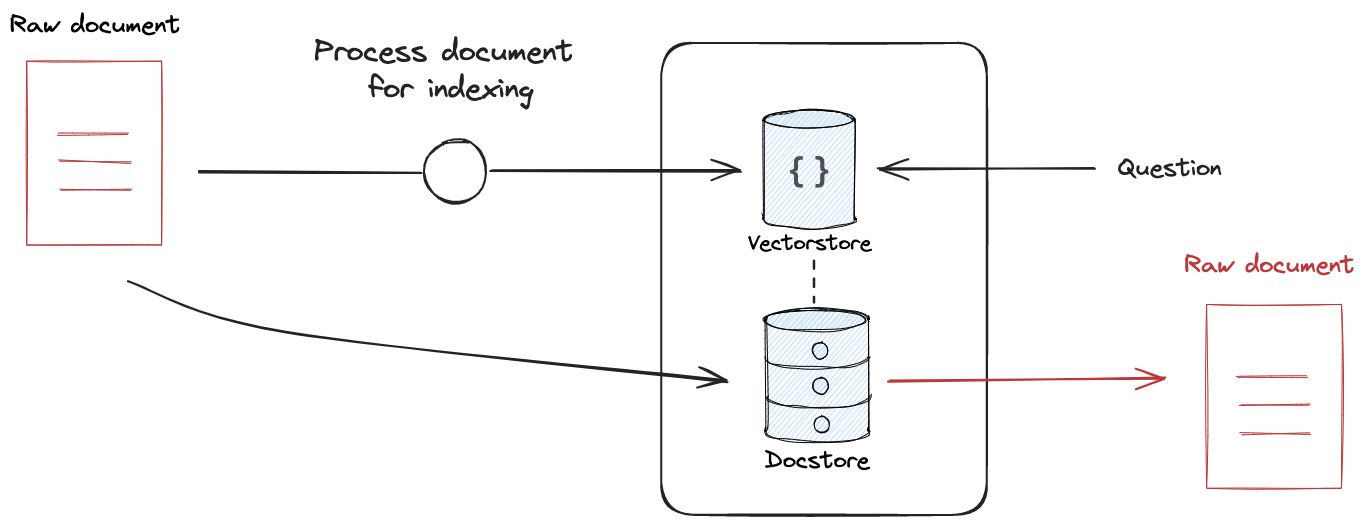
这在人工智能应用中特别有用,因为它确保了模型不会丢失文档上下文。例如,当使用较小的块chunk来索引向量存储中的文档时,如果仅返回这些块作为检索结果,那么模型将丢失这些块的原始文档上下文,而设置保留源文档就可以解决这种问题。
3. 多向量检索器与父文档检索器
LangChain也提供了另外两种不同的检索器来解决源文档问题:
- 多向量检索器(Multi-Vector Retriever):允许用户使用任何文档转换(例如使用LLM编写文档摘要)进行向量索引,同时保留与源文档的链接;
- 父文档检索器(ParentDocument Retriever):在使用文本分割器转换中,链接文档块(document chunks)以进行索引,同时保留文档块与源文档的链接。
这些检索器确保在检索过程中保留文档的上下文,从而提高模型的理解和性能。两种检索器总结如下:
| 名称 | 索引类型 | 是否使用LLM | 使用场景 | 描述 |
|---|---|---|---|---|
| 多向量检索器(Multi-Vector Retriever) | 向量存储 + 文档存储 | 有时在索引期间使用 | 如果能够从文档中提取出比文本本身更相关的信息进行索引。 | 这涉及为每个文档创建多个向量,每个向量可以通过多种方式创建——例如包括文本摘要和假设性问题。 |
| 父文档检索器(ParentDocument Retriever) | 向量存储 + 文档存储 | 否 | 如果页面包含许多较小的独立信息片段,这些片段可以单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块,查询时在嵌入空间中检索到最相似的块,此时返回整个父文档(而不是单个块)。 |
延伸阅读:
- 了解如何使用父文档检索器,请参阅How to use the Parent Document Retriever;
- 了解如何使用多向量检索器检索文档,请参阅How to retrieve using multiple vectors per document;
- 使用多向量检索器从零开始构建RAG的教学视频,请参阅RAG from scratch: Part 12 (Multi-Representation Indexing) 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









