







 本文介绍了PVTv2,通过改进线性复杂度注意层、重叠斑块嵌入和卷积前馈网络,降低了PVTv1的计算成本并增强局部连续性。PVTv2在视觉任务上表现出色,且在YOLOv5中作为backbone被应用。
本文介绍了PVTv2,通过改进线性复杂度注意层、重叠斑块嵌入和卷积前馈网络,降低了PVTv1的计算成本并增强局部连续性。PVTv2在视觉任务上表现出色,且在YOLOv5中作为backbone被应用。
摘要:最近,Transformer在计算机视觉方面取得了令人鼓舞的进展。在本研究中,本文通过增加(1)线性复杂度注意层、(2)重叠贴片嵌入和(3)卷积前馈网络三种设计,改进了原始的金字塔视觉转换器(PVT v1),提出了新的基线。通过这些改进,PVT v2将PVT v1的计算复杂度降为线性,并在分类、检测和分割等基本视觉任务上实现了显著改进。值得注意的是,PVT v2与Swin Transformer等最近的作品相比,取得了相当或更好的性能。本文希望这项工作将促进最先进的变压器在计算机视觉的研究。
相较于PVT,PVTv2增加了三部分 (1) Linear complexity attention layer, (2) Overlapping patch embedding (3) Convolutional feed-forward network.
PVT存在的三点限制:
(1)与ViT类似,当处理高分辨率输入时,PVT v1的计算复杂度相对较大
(2)PVT v1将图像视为非重叠块序列,这在一定程度上失去图像的局部连续
(3)PVT v1中的位置编码是固定大小,这对于任意大小的处理图像是不灵活的
Linear Spatial Reduction Attention (Linear SRA)
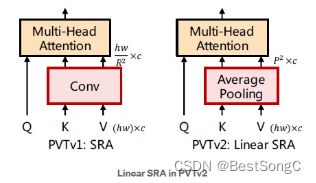
首先为了降低注意操作引起的高计算成本,本文提出了线性空间注意(Linear SRA)层ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9791
9791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









