




目录
2.代价函数数学定义,有助于弄清楚如何把最有可能的直线与我们的数据相拟合
3.前面给出了代价函数的数学定义,接下来给出例子直观理解代价函数的作用
1.线性回归算法:监督学习算法的例子

这里还是住房价格的例子,假设你有一个朋友有一个1250平方的房子,想要卖掉,那么根据这个模型,可以用一条直线来拟合,告诉他可以卖到220K,这是监督学习的例子,因为每一个例子有一个“正确答案”。
现在有一个房价的训练集,我们的工作是从这个数据集中学习如何预测房价,下面要定义一些符号:
假设小写字母m表示训练样本的数量,x代表输入变量或特征,y表示输出变量,用(x,y)表示一个训练样本
![]() 用他来表示第i个训练样本,上标i只是一个训练集的索引,指的是这个表格中第i行。
用他来表示第i个训练样本,上标i只是一个训练集的索引,指的是这个表格中第i行。

学习算法会得出一个假设函数h,而h就是一个引导从x得到y的函数。
函数h的作用是预测y是关于x的线性函数![]()
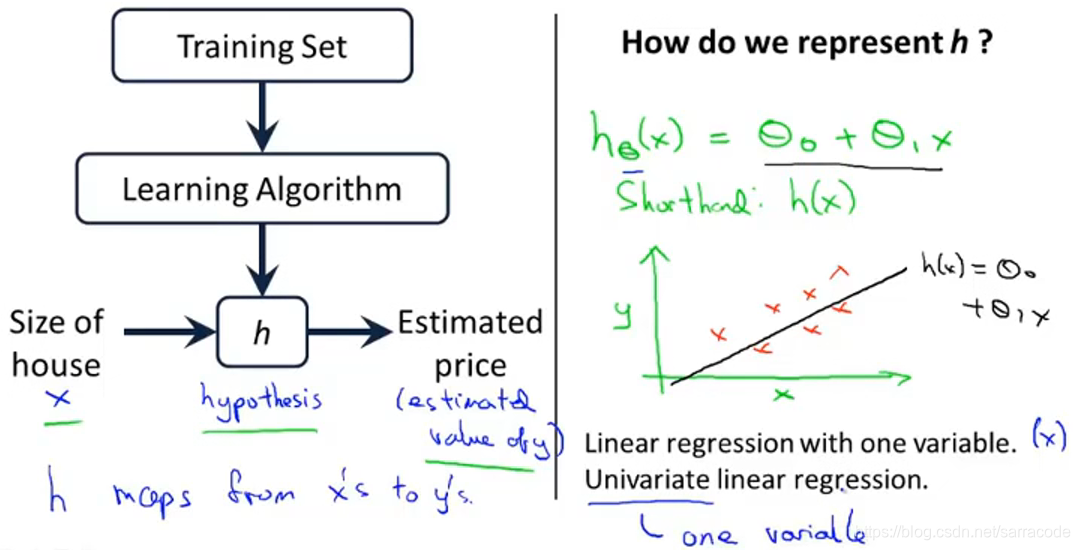
线性函数是学习复杂函数的基础,先拟合线性函数再处理更加复杂的模型
这个模型称为线性回归,这个例子是一个一元线性回归,变量是x,另一个名字是单变量线性回归
2.代价函数数学定义,有助于弄清楚如何把最有可能的直线与我们的数据相拟合

在线性回归中有一个这样的训练集,i是模型参数,如何选择这两个参数,选择的参数不同的得到的假设函数就不同,如下所示
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









