




 本文介绍了感知器学习算法,从模型介绍、原理证明到代码实现,探讨了如何利用数学和编程构建简单的线性分类模型,处理邮件垃圾邮件问题。
本文介绍了感知器学习算法,从模型介绍、原理证明到代码实现,探讨了如何利用数学和编程构建简单的线性分类模型,处理邮件垃圾邮件问题。
阅读本文需要的背景知识点:数学基础知识、一丢丢编程知识
一、引言
前面一节我们了解了机器学习算法系列(〇)- 基础知识,接下来正式开始机器学习算法的学习,首先我们从最简单的一个算法——感知器学习算法(Perceptron Learning Algorithm)开始。
我们在使用电子邮件时,应该注意到现代邮箱都有反垃圾邮件的功能,系统根据邮件的内容自动判断是否是垃圾邮件,节省了我们的时间,试想一下这个功能应该如何实现呢?
我们可以先收集一批邮件,总结出对判断是否是垃圾邮件有用的一些特征值(例如:邮件是否包含链接、邮件出现过多少个营销词语、邮件的发送时间等等),然后对每一封邮件先人工的判断是否是垃圾邮件,最后试图通过这些数据来找到里面所包含的关联关系。以后给到一封新邮件的时候,我们就可以通过这些关系来判断是否是垃圾邮件了。
二、模型介绍
回想一下在初中生物教材上介绍过的神经细胞,它是由树突、轴突、突触和细胞体组成的结构体。神经细胞是否激活并输出电信号是由其接收到的输入信号量和突触的强度所决定的,当其总和超过某个阈值时,细胞体就会激动并输出电信号。由这一神经细胞的行为,人们提出了感知器的概念和对应的感知器学习算法。
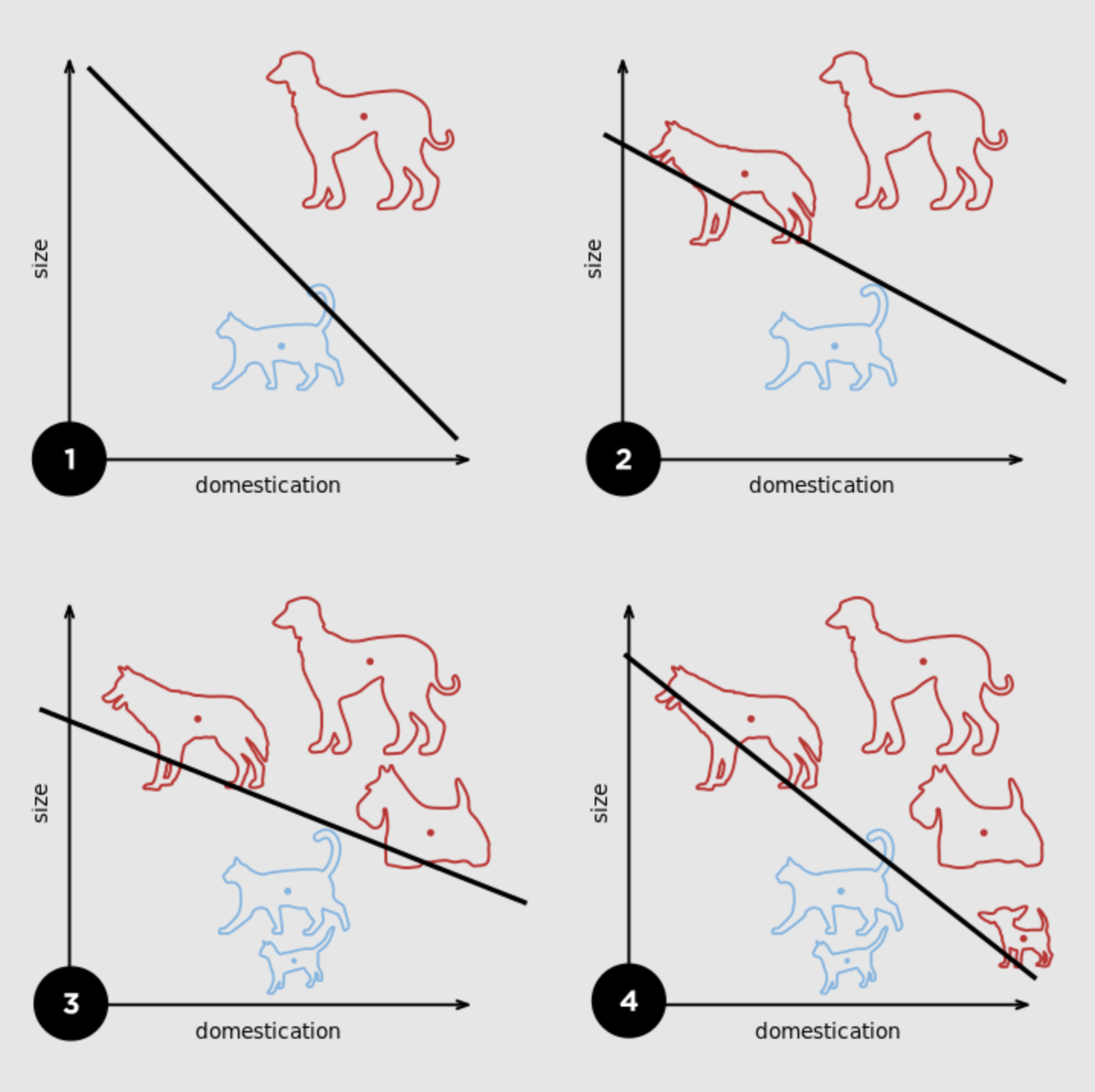
感知器1(Perceptron)是一种二元线性分类器,将一个线性可分的数据集通过线性组合分成两种类型。在人工神经网络领域中,感知机也被指为单层的人工神经网络。
几何意义:在二维平面内找到一条直线将两种类型的数据完全分开。在高维空间里为找到一个超平面将两类数据分开。
数学定义:把矩阵上的输入 X(实数值向量)映射到输出值 h(x) 上(一个二元的值 -1 或 +1 )。假设存在 d 个 x ,通过 w 的加权求和,大于某个临界值时返回 +1,小于某个临界值时返回 -1。
∑ i = 1 d w i x i > 临界值 + 1 ( A 分类 ) ∑ i = 1 d w i x i < 临界值 − 1 ( B 分类 ) \begin{array}{cc} \sum_{i=1}^{d} w_{i} x_{i}>\text { 临界值 } & +1(A \text { 分类 }) \\ \sum_{i=1}^{d} w_{i} x_{i}<\text { 临界值 } & -1(B \text { 分类 }) \end{array} ∑i=1dwixi> 临界值 ∑i=1dwixi< 临界值 +1(A 分类 )−1(B 分类 )
将上式写成一个函数的形式(sign函数称为符号函数2,当输入小于 0 则输出 -1,当输入大于 0 则输出 +1)
h ( x ) = sign ( ∑ i = 1 d w i x i − 临 界 值 ) h(x) = \operatorname{sign}\left(\sum_{i = 1}^dw_ix_i - 临界值\right) h(x)=sign(i=1∑dwixi−临界值)
将负的临界值当作第 0 个 w,正1 当作第 0 个 x
h ( x ) = sign ( ( ∑ i = 1 d w i x i ) + ( − 临界值 ) ⏟ w 0 ⋅ ( + 1 ) ⏟ x 0 ) h(x)=\operatorname{sign}(\left(\sum_{i=1}^{d} w_{i} x_{i}\right)+\underbrace{(-\text { 临界值 })}_{w_{0}} \cdot \underbrace{(+1)}_{x_{0}}) h(x)=sign((i=1∑dwixi)+w0
(− 临界值 )⋅x0
(+1))
可将临界值合到从 1 到 d 的连加运算中,则连加运算的下界变为 0
h ( x ) = sign ( ∑ i = 0 d w i x i ) h(x) = \operatorname{sign}\left(\sum_{i=0}^dw_ix_i\right) h(x)=sign(i=0∑dwixi)
最后函数可改写为两个向量(w、x)的点积形式
h ( x ) = sign ( w T x ) h(x) = \operatorname{sign}\left( w^Tx \right) h(x)=sign(wTx)
感知器是一种特别简单的线性分类模型,但是它的本质缺陷是不能处理线性不可分的问题,后面的小节将介绍一个可以允许存在一些错误的发生,能处理线性不可分数据集的算法——口袋算法(Pocket Algorithm)
三、算法步骤
感知器学习算法(Perceptron Learning Algorithm)- 其核心思想就是以错误为驱动,逐步修正错误最后收敛的过程。
初始化向量 w,例如 w 初始化为零向量
循环 t = 0,1,2 …
按顺序或随机遍历全部数据并计算 h(x) ,直到找到其中一个数据的 h(x) 与目标值 y 不符
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6134
6134

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









