




本文对深度学习中的过拟合问题进行了探讨,详细分析了过拟合的概念和原因,并给出了深度学习中抑制过拟合的常用方法。本文通过详细示例来解释概念、分析原因、提供参考解决方法。本文最后附有全部示例代码,读者可下载后自行试验。
2 过拟合的抑制
解决过拟合问题时,常提到一个所谓的“奥卡姆剃刀(Occam’s Razor)定律”,它是由14世纪逻辑学家奥卡姆提出的。这个定律称为“如无必要,勿增实体”,即“简单有效原理”。在模型选择中,就是在所有可以选择的模型中,能够很好地解释已知数据并且简单的模型才是最好的模型。基于这个思路,人们常采用正则化(regularization)、早停(early stopping)、随机失活(dropout)等方法来抑制过拟合。
2.1 早停法
早停法是在模型迭代训练中,在模型对训练样本集收敛之前就停止迭代以防止过拟合的方法。
前面讨论过,模型泛化能力评估的思路是将样本集划分为训练集和验证集,用训练集来训练模型,训练完成后,用验证集来验证模型的泛化能力。而早停法提前引入验证集来验证模型的泛化能力,即在每一轮训练(一轮是指遍历所有训练样本一次)完后,就用验证集来验证泛化能力,如果n轮训练都没有使泛化能力得到提高,就停止训练。n是根据经验提前设定的参数,常取10、20、30等值。这种策略称为“No-improvement-in-n”。
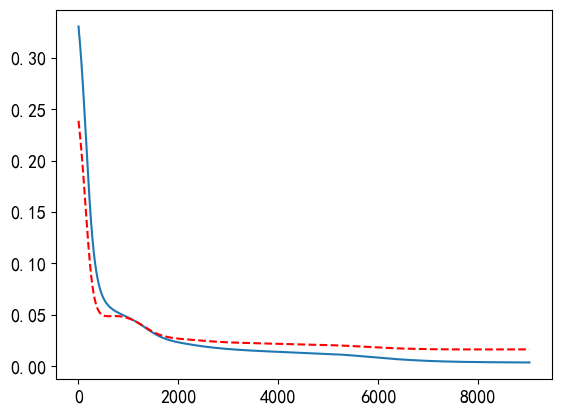
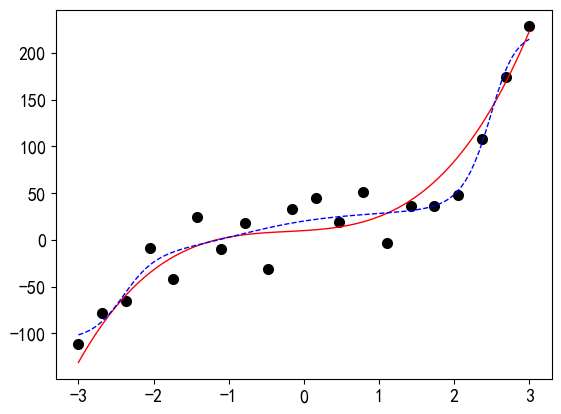
PyTorch中实现早停法抑制过拟合的示例如代码7-1.7所示。n(代码中为patience)设置为1000。另设置了一个很小的参数delta,用于评估测试误差是否保持不变。当测试误差满足1000轮保持不变的条件时,训练中止,拟合结果如输出的图形所示。
代码7-1.7 早停法抑制过拟合
model = RegressionModel_5_5() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters()) # 训练模型 train_losses = [] val_losses = [] best_loss = float('inf') patience = 1000 # 验证集损失函数持续不降的训练轮数 delta = 0.00000000001 counter = 0 epochs_stop = 0 for epoch in range(n_epoch): model.train() optimizer.zero_grad() outputs = model(x_tensor) loss = criterion(outputs, y_tensor) loss.backward() optimizer.step() # 验证 model.eval() with torch.no_grad(): val_outputs = model(x1_tensor) val_loss = criterion(val_outputs, y0_tensor) train_losses.append(loss.item()) val_losses.append(val_loss.item()) # 早停 if val_loss < best_loss - delta: best_loss = val_loss counter = 0 else: counter += 1 if counter >= patience: print(f'早停法停止训练于第{epoch}轮!') epochs_stop = epoch break if epoch % 1000 == 0: print(f'Epoch {epoch}, Train Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}') # 绘图 plt.rcParams['axes.unicode_minus']=False plt.rc('font', family='SimHei', size=13) epochs = np.arange(epochs_stop+1) + 1 plt.plot(epochs, train_losses) plt.plot(epochs, val_losses, "r--") plt.show() predict_view(model, x, yy, myfun)输出:
Epoch 0, Train Loss: 0.3304, Val Loss: 0.2386 Epoch 1000, Train Loss: 0.0471, Val Loss: 0.0465 Epoch 2000, Train Loss: 0.0231, Val Loss: 0.0267 Epoch 3000, Train Loss: 0.0166, Val Loss: 0.0231 Epoch 4000, Train Loss: 0.0139, Val Loss: 0.0217 Epoch 5000, Train Loss: 0.0119, Val Loss: 0.0205 Epoch 6000, Train Loss: 0.0082, Val Loss: 0.0181 Epoch 7000, Train Loss: 0.0051, Val Loss: 0.0165 Epoch 8000, Train Loss: 0.0039, Val Loss: 0.0162 Epoch 9000, Train Loss: 0.0035, Val Loss: 0.0163 早停法停止训练于第9028轮!
2.2 正则法
既然过拟合是由于模型过于复杂导致的,那么想办法减少模型的复杂程度是不是可以抑制过拟合?这正是正则法抑制过拟合的思路。
正则化方法是在样本集的损失函数中增加一个正则化项(regularizer),或者称罚项(penalty term),来对冲模型的复杂度。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。有关正则法方法的理论分析,参见文献[1]。
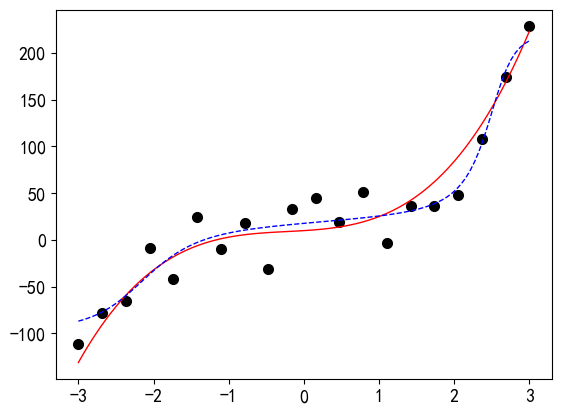
在PyTorch中实现正则法方法抑制过拟合非常简单,只需要设置优化器的weight_decay参数值即可。示例代码见代码7-1.8所示。weight_decay参数值要设置合理,过大会导致模型欠拟合,参见示例。
代码7-1.8 正则化抑制过拟合
model = RegressionModel_5_5() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), weight_decay=0.0001) # 通过设置weight_decay参数引入L2正则化 # 训练20000轮 for epoch in range(20000): optimizer.zero_grad() outputs = model(x_tensor) loss = criterion(outputs, y_tensor) loss.backward() optimizer.step() predict_view(model, x, yy, myfun)输出:
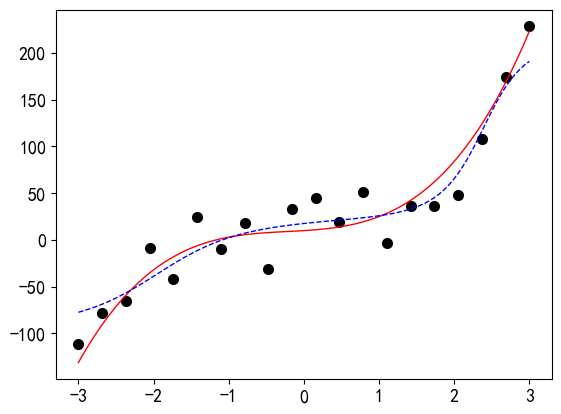
# 参数设置过大,变成欠拟合 model = RegressionModel_5_5() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), weight_decay=0.001) # 训练20000轮 for epoch in range(20000): optimizer.zero_grad() outputs = model(x_tensor) loss = criterion(outputs, y_tensor) loss.backward() optimizer.step() predict_view(model, x, yy, myfun)输出:
2.3 随机失活法
随机失活法是将神经元随机失活,即按预先设定的概率随机选择某些神经元进行失效,不参与本次训练。该方法可以一定程度上抑制过拟合问题。
PyTorch中实现随机失活是通过专门的Dropout层来实现,它的参数p是失活率,即神经元随机失活的概率。
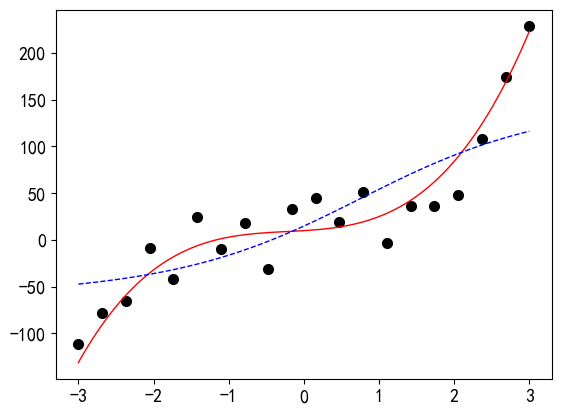
随机失活法的示例见代码7-1.9。失活率也要适当设置,过大的话也会带来欠拟合的问题。本文最后附有全部示例代码,读者可下载后自行试验,不再赘述。
代码7-1.9 Dropout抑制过拟合
# 定义增加了Dropout层的模型 class RegressionModel_5_5_dropout(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential( nn.Linear(1, 5), nn.Sigmoid(), nn.Dropout(0.001), # 添加Dropout层 nn.Linear(5, 5), nn.Sigmoid(), nn.Linear(5, 1), nn.Sigmoid() ) # 初始化权重 for layer in self.net: if isinstance(layer, nn.Linear): nn.init.uniform_(layer.weight) nn.init.zeros_(layer.bias) def forward(self, x): return self.net(x) model = RegressionModel_5_5_dropout() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters()) # 训练20000轮 for epoch in range(20000): optimizer.zero_grad() outputs = model(x_tensor) loss = criterion(outputs, y_tensor) loss.backward() optimizer.step() predict_view(model, x, yy, myfun)输出:
参考文献:
[1] 王衡军,机器学习[M].北京:清华大学出版社,2020.



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









