




Learning Normal Dynamics in Videos with Meta Prototype Network
Hui Lv1, Chen Chen2, Zhen Cui1*, Chunyan Xu1, Yong Li1, Jian Yang1
1PCALab, Nanjing University of Science and Technology, 2University of North Carolina at Charlotte
一、论文阅读
该论文通过在AE baseline上加入动态原型单元DPU,为不同的正常模式构建动态原型,每个常态原型编码场景的不同正常属性(diverse normal attributes)。该论文验证了动态原型建模正常模式分布的可行性。
关键词:对场景构建动态原型、注意力机制、端到端学习
解决了什么问题:记忆模块无法处理在测试数据中新出现的场景。
该论文的任务是:提取出正常模式的场景动态原型;视频异常检测。
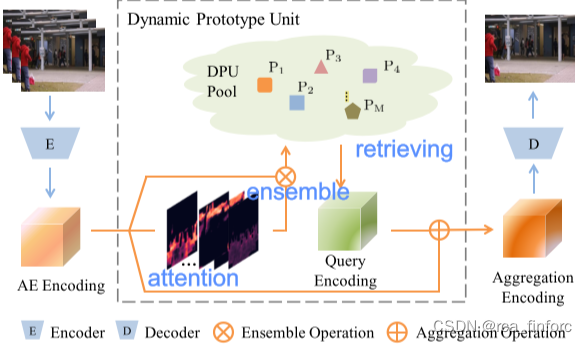
其中每种原型代表一种被记忆的场景元素,如下图:
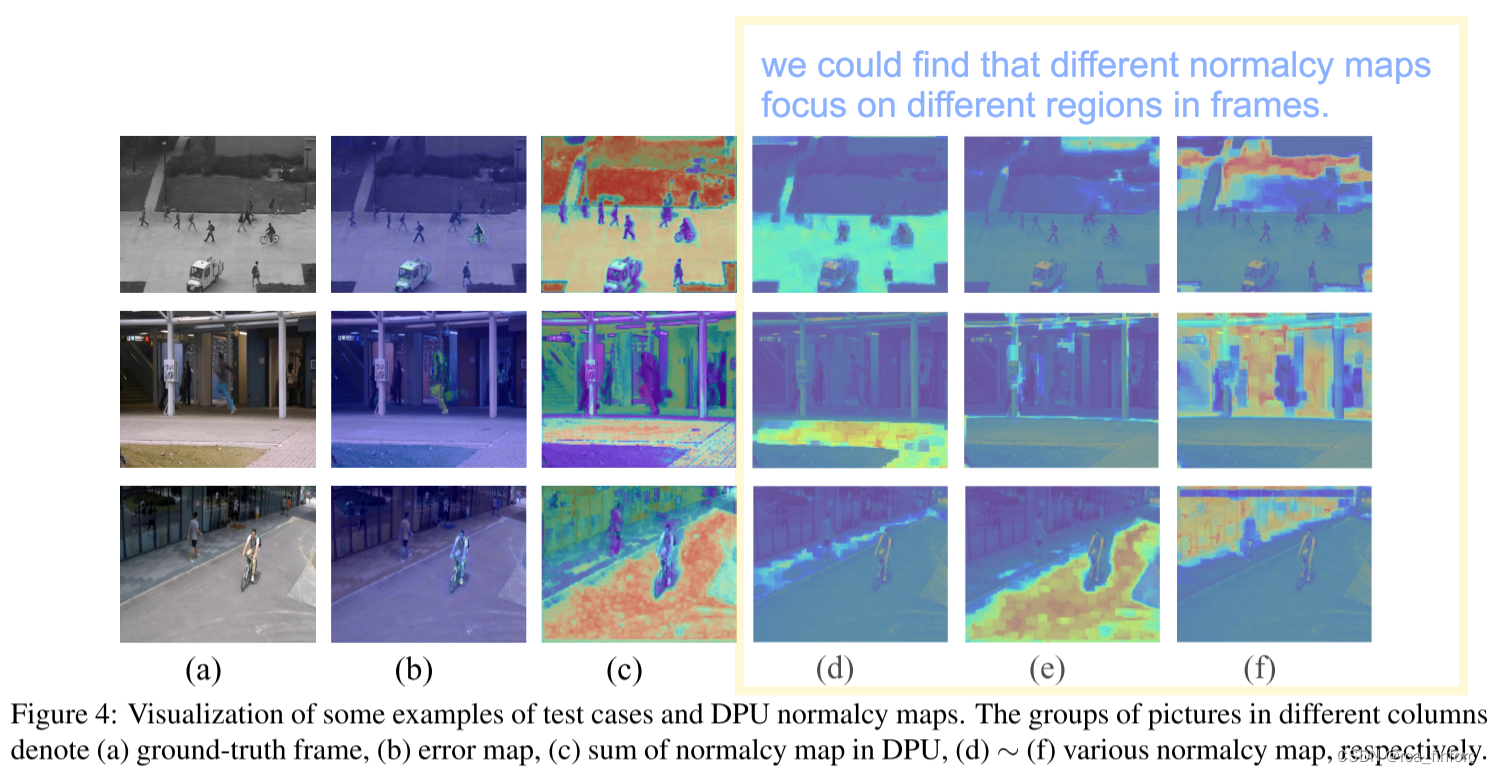
二、代码阅读
论文代码中表现出的总的结构如下所示

参数设定:
batch_size = 4
epochs = 1000
t_length = 5 # length of the frame sequences
segs = 32 # num of video segments
fdim, pdim = [128], [128] # features dim and prototype dim
1. 数据集加载

预设batch_size=4,_time_step=4,_num_pred=1,segs=32(图中的n),每个视频分为32段,随机选择4段,从中抽取出4+1个视频帧用于训练。每个图像被resize为256*256。最终作为模型输入的tensor的shape为[20, 3, 256, 256]。
核心代码
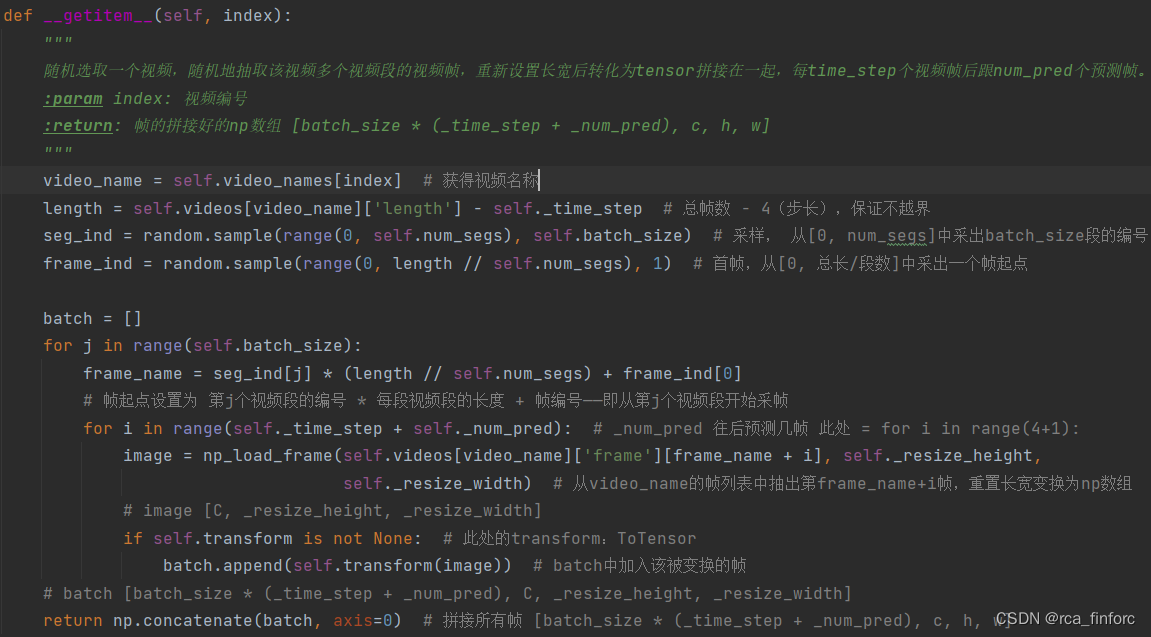
2. DPU(Dynamic Prototypes Units)
Attention 部分

进入Attention部分的输入是来自于解码器的特征向量。分为以下几步:
- 将keys输入multi-heads,得到一个多头注意力权重multi_head_weights[4, 65536,10, 1]。
- 此后对multi_head_weights作一个softmax操作,得到每个通道上每个像素点的受关注程度。
核心代码
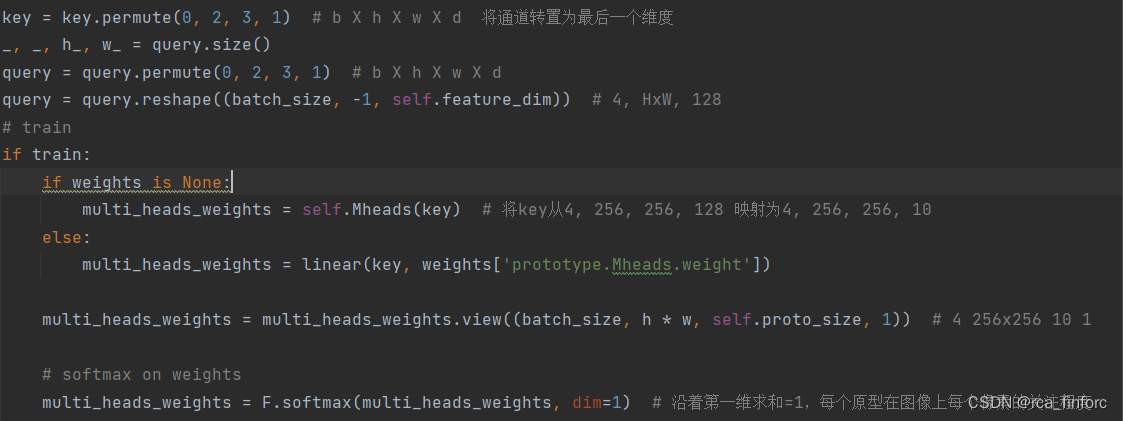
Ensemble 部分

输入该部分的输入有:特征向量key和多头注意力权重multi_head_weights。
- 将reshape后的key[4, 65536, 1, 128]与多头注意力权重相乘得到新的multi_head_weights[4, 65536, 10, 128].
- 将新的multi_head_weights与原始输入key相乘得到原型向量protos。
- 然后将不同像素位置上的原型向量求和,可以将原型向量理解为对图像上的所有像素点的注意程度。
上面的步骤对应论文中的公式1:ptm=∑n=1Nωtn,m∑n′=1Nωtn′,mxtnp_t^m=\sum\limits_{n=1}^N\frac{\omega_t^{n,m}}{\sum_{n'=1}^N\omega_t^{n',m}}\text{x}_t^nptm=n=1∑N∑n′=1N
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









