







 该博客记录了10月至12月期间的医学影像研究,如X-CT重建、医学影响的MINE模型,自然图像中的异常检测和元学习,以及步态识别与无监督学习的深入探讨。讨论了工作汇报中的关键实验、模型比较和未来研究方向。
该博客记录了10月至12月期间的医学影像研究,如X-CT重建、医学影响的MINE模型,自然图像中的异常检测和元学习,以及步态识别与无监督学习的深入探讨。讨论了工作汇报中的关键实验、模型比较和未来研究方向。
目录
【10月13日-医学影像X-】
汇报主题:
X2CT-GAN: Reconstructing CT from Biplanar X-Rays with Generative Adversarial Networks
个人记录:
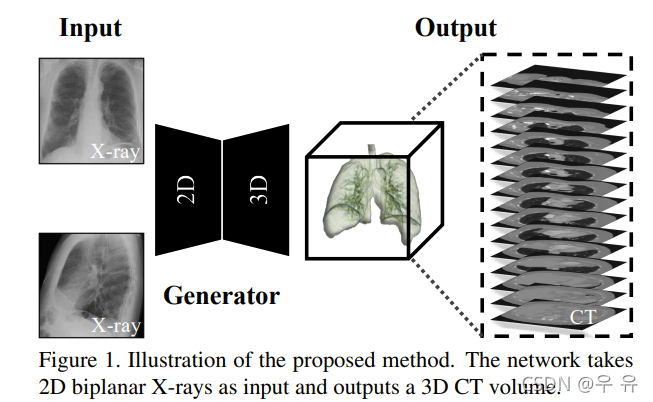
意义:CT的辐射很大,如果通过若干X光图得到CT
(参数量大 所以有个Convd c/2 contact feature map是相加 |残差???)
Instance Normalize(Batch Norm Instance Norm | BN和IN 区别)
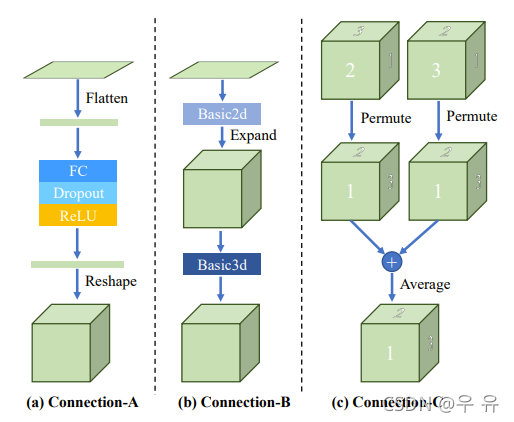
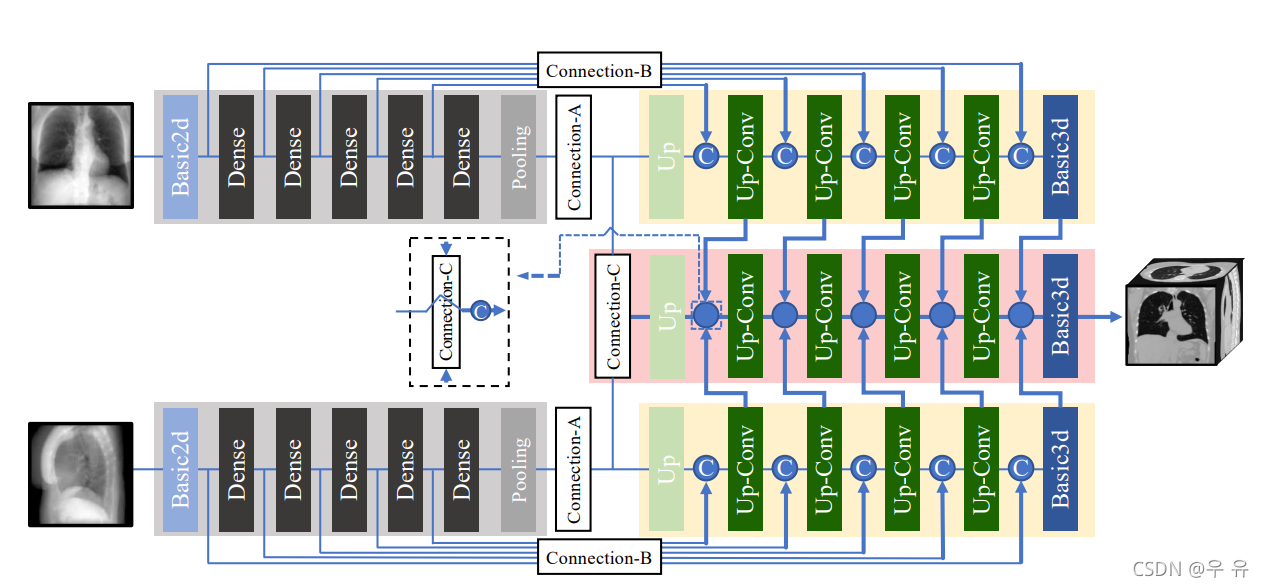
connection -ABC
损失函数 |
FC 全连接神经网络 | FC
reshape:单维变三维
输入的时候 就是正面和侧面的X光照,那么得到的feature map就是已经包含方位信息
permute操作:先将两个feature map转到相同的方向,然后取平均值
三个损失函数:
GAL GAL论文/ 正交投影?/点光源投影
(GAL:geometric adversarial loss for single-view 3D-object reconstruction)
connect 模块评估
常见指标:
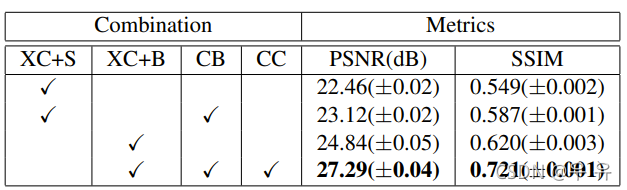
PSNR SSIM结构相似度评价 (常见指标×3) dias?
分割上 LU 霍夫曼距离???
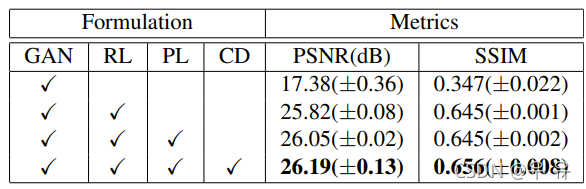
RL:MSE损失PL投影损失CD
【问题讨论:】
X光片上 椎骨 离群点(噪声)
landmark | 双平面预测 |
【10月21日-医学影响-MG-C2L】
[MINE]论文研读/Self-supervised、unsupervised learning/2002新 |论文腾讯开源大规模X光预训练模型及代码| MICCAI 2020 追踪之论文纲要(上) |
Models Genesis
[MINE]三维迁移学习 |
GM模型
pic1
非线性变换学习外观
局部像素变换学习纹理
外部和内部的分割来学习环境
预训练过程
pic2 胸部
模型必须区分出原始图像和变换后的图像,区分变换类型,并在变换后恢复图像
=>自我监督学习 处理多任务的模型
encoder-decoder|e-d | 架构 | 架构详解 | 架构介绍 | E-D模型和Attention模型 | Pytorch实现E-D模型|
验证 fine-tuning
一个证明3D优于2D/2.5D的说明
C2L模型
comparing to learn:Surpassing ImageNet pretraining on Radiographs By comparing image representations 文章 |腾讯天衍 MICCIA 2020
pic3
【10月22-自然图像-】
1、Anomaly:Learning Normal Dynamics in Videos with Meta Prototype Network
异常检测、阈值、异常检测 | 异常 |时序数据异常检测算法简述与分类 | 算法及发展趋势|new研究| 值得研究的问题|工业图像异常检测|复现异常检测的未来帧预测|异常检测综述|
主流:重构和预测的异常检测视频异常检测|
缺点:没有学习到正常模式 进来什么就输出什么<=加一个记忆模块Memory(记忆正常模式信息)
总体框架:
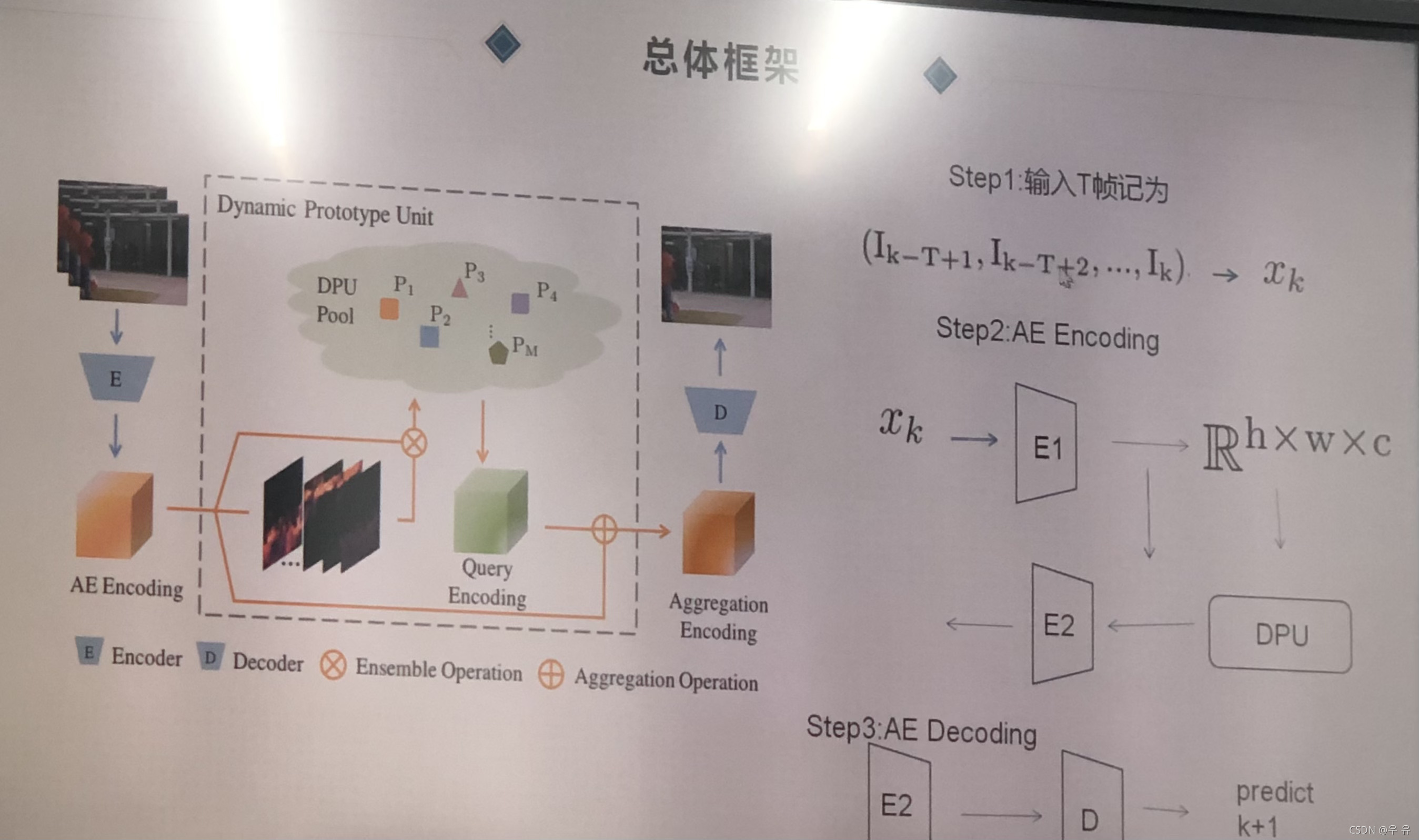
(强调 正常模式||在讲论文的时候 预设哪些地方大家会提问/连贯的逻辑性/不要等提问再解释 )
DPU模块
笔记|dpu芯片发展前景|数据处理器(DPU)行业概览2021|算力经济下DPU芯片的发展机遇|
2、Meta-Learning与Machine Learning
元学习|介绍&代码| LHY |元学习综述 | 初探元学习 | √-元学习论文、视频、书籍资源整理 | 了解 |概念梳理|最新元学习综述-A Survey of Deep Meta-Learning | √-综述及五篇顶会论文推荐 |笔记元学习与迁移学习|
论文不一定去看他具体怎么做,而是看到别人正在做什么?有什么方向正在做?=>开题你的想法
多看论文!多看论文!!多看论文!!!
【师姐】
HRNet|详解 | 笔记&代码 | 笔记 | 超级快的HRNet | HRNET网络结构简单分析 | 源代码结构详解 | HRNet 之后,姿态估计还有研究空间么 | 人体姿势估计神经网络概述– HRNet + HigherHRNet,体系结构和常见问题解答 |
PPT里的细节:学校Logo、会议名称
★会议 CCF等 看看deadline 准备 要主动 有自己的目标和计划=>提升
【10月27日-工作汇报】
【积累】
工作汇报内容/表述要完整
写大论文的时候一定要有整体性,后面的内容也要考虑到对前面内容的延续性not两个小论文拼凑
图-拉近关系(双向) || 绘图也要体现关系 ||东西放在ppt上要说清楚/完整清晰/你的困惑点想要得到的 || 在汇报的时候 要考虑别人能不能看清楚-基本 ||
【工作汇报】
1、消融实验|FASPell论文阅读 | ablation study | 是什么 |是什么| 最佳解释 |是什么-Faster R-CNN | 1 | cv里的消融实验 | 2 | 消融 | 3 | 4 |
2、transformer本身是基于attention的模型比CNN更容易关注到与服务无关的特征
详解transformer | transformer模型详解 | 工作原理 | 小白详解 | 介绍 | 图解 | 各层网络结构详解 | 模型详解 | 印象深刻的魔改transformer | 详解 |
相互学习、
self Attention矩阵的mask:自适应mask(如何得到/还在探索中)
交换中间Patch,从而不依赖于人体解析(transform已分Path了)=换装|直接交换Patch不上下身
问:
(1)这几个想法目前实验好跑吗?
(2)第二个确实不容易定
(3)第三个 transformer有时序关系,那在交换Patch时怎么体现呢?就说patch序列本身之间有什么?
交换是同一个人还是不同人?交换时实际的情况是,不光换了衣服但其实也换了人的轮廓
<学习师兄要多思考:基于服装颜色换之外,是否还有其他的交换方式?这里师兄就是想到了patch交换,虽然不是最好的可能有别的方法,但是要有思考>
拍的时候做裁剪的时候会压缩吗?成同一个size?tensow-resize、
周纵苇颜色反转,然后训练(因为颜色背后还是结构关系?)抛弃颜色对结构有很好的学习,类似R曲线做类似连续的变换
静态图片,只有像素图像没有动态,就没有用来明显识别特征的信息了||灰度图效果不好 就像后面说的 这样人和场景更加难以识别辨别 ||轮廓和背景有关系,解析就是为了要从背景中扣出人,行人再识别是实际状况背景更复杂且轮廓上有噪声,对识别有困扰 ||
(SOME:backbone)
3、
互学习 |效果不明显 (和不加轮廓的效果基本持平)|| MSE损失
热图中17个点 挑7个关键点 (无监督自己找better)
文献中热图 | 热图-统计学 | heatmap | 数据可视化之热图 | 热图的解读及边界聚类的意义 |
KL散度 | KL与PCA区别 | 交叉熵与KL散度 | 熵,交叉熵,KL散度的理解 | KL散度的数学概念 |
问:
热图的作用?为什么用?互学习的目的?
为什么用RGB?
4、
轻量型特征提取头 | coco数据集 | crowdpose数据集 -19年| MPII数据集 | 轻量级 |
目标检测中map ar、图邻接矩阵、
NCIIP会议
问:
轻量级怎么设计/体现?|| 模型设计时,将参数量、计算量↓
如何剪枝?
深度学习没有推理? 深度学习+推理 || 逻辑
5、inception V1 / V2 / -resnet
池化 | inception和pooling | inception |
UNet |
SE注意力 |
【10月28日-】
3D U2-Net| 同 -3-| Separable Convolution实现参数压缩 | Domain adapter 浅析 | Loss Function | Expetimental Results-independent/shared/universal- |模型压缩等/论文用到的模型也是15左右较旧的,那本文的卖点和创新点在哪里?(模型结构上是很常规的,但是模态上可以做创新卖点) |
CT、MR 的提取是针对完全不用的图像提取,有时图片/特征的提取是不能迁移的|亮的部分不一样
You Only Learn Once: Universal Anatomical Landmark Detection -论文
YOLO算法 | MRE等误li差 | 消融实验 | 三个一起放的效果比单独某个数据集的效果好 | 多视角多域 |
Unsupervised..Landmarks | 面部关键特征点(Landmark)的定位 | |Facial Landmark Detection(人脸特征点检测) |人脸关键点landmark算法:FPS3000 |如何理解SLAM中的路标(landmark)|
讲一下论文的发表背景、对文章的模块/阅读等更加深入清晰一点 (流程、想法)
【论文阅读】
论文+开源代码 | 深度学习基础知识
带着主题看论文 | 参考文献/作者的相关、对某个领域有系统性认知
几篇综述+名词 (明确what) => 针对某一个任务做论文的调研/论文数据集Paper入手(要解释这个问题需要论证哪些方面、好的数据集设计)
论文先看其来源 | 读思结合(解释的够嘛)
VGG、GN、DN等经典网络结构 、看CVPR等偏应用的一些 从简单的文章入手 | 高引用量文
下次课开始基础领域介绍
【10月29日-步态无监督】
步态无监督
Gait Recognition via Effective Global-Local Feature Representation and Local Temporal Aggregation 论文
步态识别是什么
全局和局部特征的提取、空间和时间的信息融合
帧=>时间信息 、图片本身=>空间信息
LTA GLFE
【11月5日-步态】
Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification |翻译 |
跨模态对齐策略:
传统:①注意力模型来获取身体部位和单词之间的对应关系|依赖于每个图像-文本对的跨模式操作|穷举 计算量大②外部工具将一个文本描述分成若干组名词短语(对图像也是分part),每组名词短语对应一个特定的身体部位|缺陷是文本特征的质量对外部工具的可靠性很敏感
前一种对单词没有划分,只是提取图像part;后一种有对文本的划分,将文本划分为短语的过程会破坏名词短语之间的相关性,降低文本特征的质量
讲论文的时候 要把这些要点、区别、具体不足在哪里要自己提出来讲清楚
本文贡献:①SSAN语义自对齐网络-有效提取语义对齐的视觉和文本part特征 | part之间本身存在一定的关联性 | 解决上述第二种 、②多视图non-local网络捕捉身体部位之间关系、③复合排名CR损失,用于数据增强|、④构建ICFG-PEDES的新数据集
整体网络架构:
Global Feature Extraction + Part-specific Feature Learning =>
全局特征学习+Part特征学习(特定part特征的学习&part间关系网络学习)
合理的part特征,以白线在图像中人的身体部位为eg:裤子上的白线、上衣的白线...
在描述的时候,文本无次序(),但图像描述有顺序,所以用后者监督前者
Part-specifuc特征学习:首先引入单词注意力模块WAM来推断单词-part之间对应关系,第i个单词属于第k个part的预测概率;
【11月12日-步态识别】
步态:预防犯罪、法医鉴定、社会安全| 医学运用(心理疾病、智力疾病 | 老人 、一个人的过去和现在or一类相同症状群体 | 数据集的构建-对比/评价/ | )
深度学习:网络结构优化】损失函数、提升步态基准
=>做一个新的领域的时候 对于其数据集的构造的思考
=>轮廓图只能获取外部框架,当手放在前面的时候会捕捉不到;但是热图可以,热图能够补充提醒手的存在=>师兄的论文要先看 已经遇到的研究的做到的 要先去了解| 这里论文的数据集也可以在师兄上跑一下
=>本文的实验效果并没有特别突出,但是他提出了一个好的数据集,也是一种工作
1、论文内容很多,讲解语速也均匀无停顿=>听者如何来抓住重点呢?而且有逻辑和概念错误等问题 导致听者混乱 | 可反复 停顿 来突出重点、需要自己提炼、也要注意讲话方式让听者能抓住重点
2、步态和ReID的界限模糊1 | 交叉
3、数据集ICCV 三篇 很多东西没做可做=>跨域UDA(姿态很差 姿态+轮廓better 自己构造姿态到热图 | )
没给属性 用聚类 可以不准但是起到分类作用就行 | 只要用了就是新的
ECCV2020ReID | ReID |
应用不高原因:自然场景下的数据集更加复杂-考虑多因素 | 数据集的提升空间有限
数据集:多细节、拥挤、单序列干扰集
干扰集合:仅出现在一个相机视角下的序列 |
GEI:能量图&若干帧融合到一帧,丢失时间信息
【讨论】
1、预训练+微调再训练=>80% 这里fine-tuning的结果提升并不好|微调
预训练可以提供基础的参数?
2、跨域 |提取轮廓图、视角问题 | 监控视角俯视 CASIA-B视角水平 |
else:
occlusion、distractor set干扰集、silhouette序列?、GEI、2D/3D pose、probe、CASIA-B-1、FLOGPs、光流-提高识别的准确度|光流、解纠缠、生物识别、fine-tuning微调
提交数据的格式 | 数据结构=>数据集的读取
【会议|11月13日-智能成像分会】
医学图像多模态融合综述 | 多模态医学图像融合 |
【11月17日-脊柱侧弯】
厦门:边界分割网络=>角回归网络、中间有个PPBlock|注意力机制、不是关键点计算而是回归出3个cobb角、
√腾讯优图:分割=>回归、s1分割脊柱和椎体之间的间隙、回归3个cobb角、
科大讯飞:M1检测单个椎体并框,再检测每个框的4个关键点|无法控制椎骨预测顺序、M2-baseline hrnet|粗略patch再精细patch|固定顺序预测椎骨=>M1M2两方法结合、
尼泊尔(经典):目标检测椎体=>后处理留下7个框=>映射回原来、patch检测关键点未考虑全局信息、直接回归点相比回归偏移量会受本身并不固定的patch的影响、
↑ ↑ 师姐借鉴较多/效果较好
↓ ↓ 方法/效果不太好
西安电子科技:裁剪peeling crop=>全局Global stage=>局部Local stage、先裁剪出需要区域,全局进行框,局部用patch预测关键点、
加州大学:S1胸部x光片预训练分裂=>S2预测回归标志点检测|全连接层|landmark=>S3建立关键点和cobb角之间联系回归
放射科和医学系:x光片中提取脊柱中线,通过中线计算cobb角、
PAT:基于脊椎旋转的两阶段关键点检测网络,先预测旋转角度,后一个基于前一个旋转角度进行椎骨匹配并框出脊柱|框大小预先定、有旋转角度框的意义就是在预测的时候你的预测结果不能在框外面、
之前其他方法目标检测出椎骨,区别=>得到patch方法不同
基于深度学习,算法×2:检测感兴趣区域ROI、估计cobb角
不做旋转、图像增强、增加噪声的原因
SMAPE|越小越好√、CMAE、欧几里得距离、曼哈顿距离、
数据集标注也有一些错误、只有17节且单独考虑脊椎切除盆骨等、裁剪图时用什么方法
师姐目前两阶段:粗略定位|应用到实际=>精准定位、先提高精度再压缩模型、
轻量级hrnet、high resolution net HR-net High-Resolution net 高分辨率网络 |HRnet剪枝应用到轻量级/降计算量、轻量级和实际应用/硬件结合GPU-硬件软件结合的新思路 -轻量级的研究人很多有很多可做
数据增强:脊柱侧弯需要考虑脊柱之间的形变、不一定是旋转的变化也可能是平移变化|脊柱实际侧弯可能不是上下变化而是水平变化|这样的数据增强考虑是不是更有效呢、数据增强需要考虑实际场景和应用而做、
任务两步:UNet得到类似marsk/roi的分割=>更重要的是关键点检测、全局+分块局部检测,然后两者结合在一起reset、
脑出血有真有假,可做正样本可做负样本,按快分
考虑问题的特殊性来确定方案,如脑出血和肿瘤形状一个规律一个不规律
【12.3进度汇报】
【余-】
SLRNet
transform learning 从一个域到另一个域,这两个域本身肯定是有重合的(中间域 分布重合)
多读论文 才有想法、实验要充分和细致=>出新点
关于进度进化/工作进展 后期需要更加明确清晰
【李-】
1、论文返修:reviewer
HP module
STM介绍:写作(介绍方式|太多介绍传统方法 关于自己的还不够)、
GREW实验补充:now轮廓+姿态、
实验要尽快做,因为出了新数据集就需要做对比
【张-】
1、进度
已完成实验:在原有网络架构上,增加姿态热图
增加GREW数据集实验、在步态中引入姿态热图,3DCNN提取时空特征
关于投稿和拒稿等情况:
11月投 1月底出结果
【许-】
1、
期刊Neurocomputing
NCIIP
轻量型特征提取头|剪枝
Focal Conv提取局部信息、加入先验知识 分割网络(stem)
注意力动态卷积(微软CVPR2020):本质是根据输入动态的集成多个卷积核生成新的参数
分组卷积实验、设计HPE任务优化模块
动态关节点优化模块
2、
注意力动态卷积 添加的目的?
数字孪生:什么是数字孪生? - 知乎 (zhihu.com)、数字孪生是什么? | 万字图文讲解 - 知乎 (zhihu.com)
【孙-】
创新还不够,需要多读一点论文
【王-】
1、局部信息提取(轮廓->肢体热图|HRNet)
【陈-】
IoU
可视化已经不是体素 已经转换成mash/match?
下采样 精度损失
样子上的真实not、分辨率太低需要加纹理
CT 体素 光滑
【高-】
参数 SS PI AVR
labelme 基于点
3D可视化
基于patch的关节点检测
分割 vbc ?
通过算法自动检测椎骨的vbc、上下端板、椎弓根
【邹-】
mmseg框架 脊柱分割+ mmdec框架 椎骨目标检测 => 第一阶段脊柱定位
改进关键点检测网络:加强关键点预测网络、加入模型先验知识&修改版SE模块
借鉴姿态识别中的PAF向量概念,设计网络预测中线向量
添加中心线约束,预测中心线热图
郭:
数据集标注
检测准确性
基于偏移量| 基于四个点求中心线 |基于vbc 向量 累加误差
数据集、改进算法、可视化
【方-】
【12.15-基于二维投影做损失优化|三维重建中】
RGB=>3D
三维形状中的几何信息
基于体素、mask |01 | 只显示轮廓
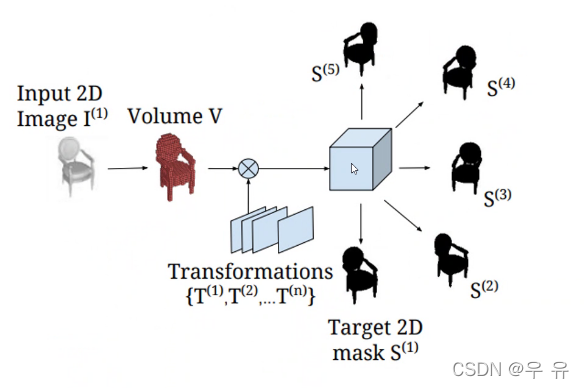
在体素范围内 GT和预测 的L2损失、投影损失、
网络结构:Encoder-Decoder
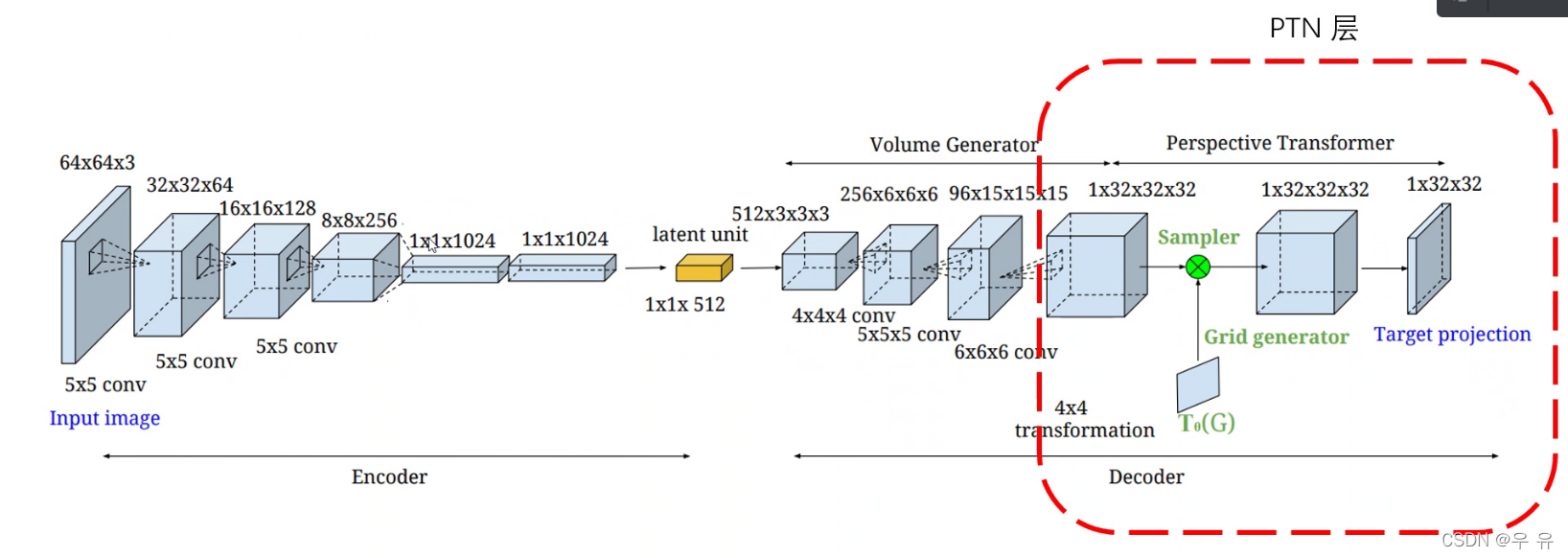
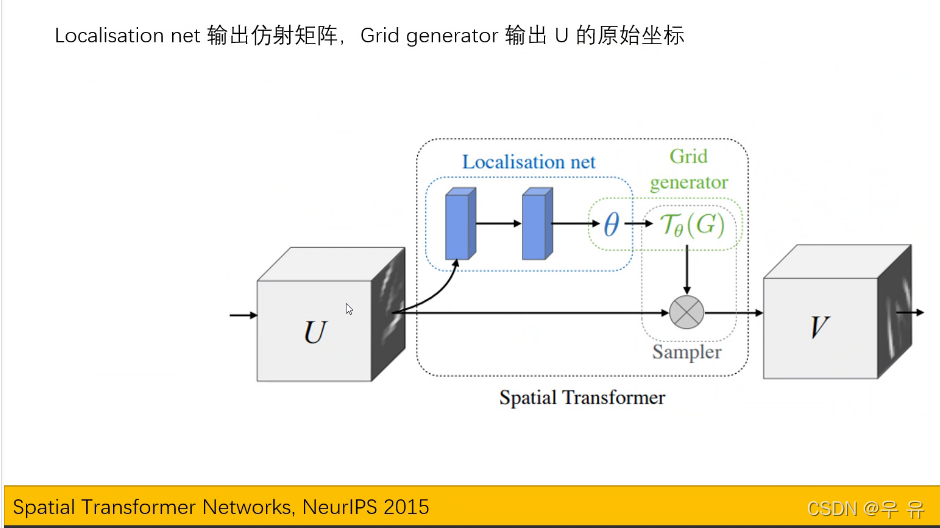
FTN层:别人提 | 这其中透视变换网络介绍↓
出发点“对图像中的物体做处理/筛选
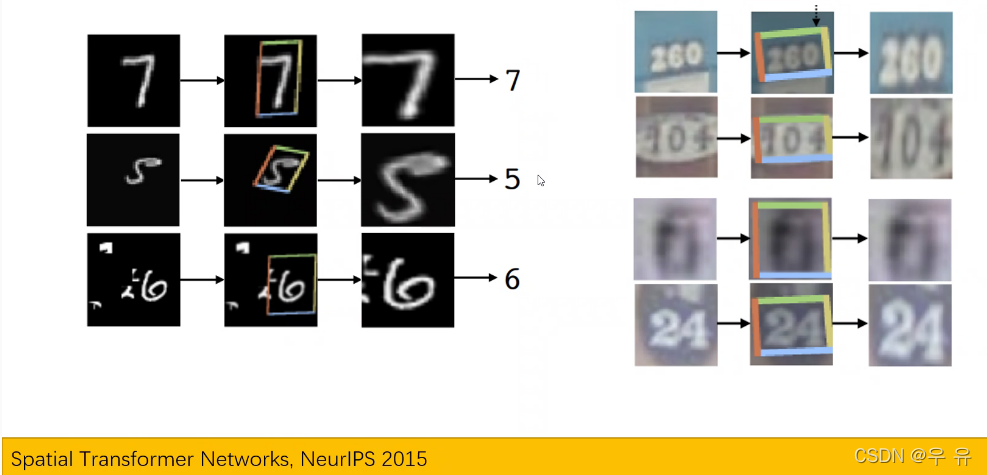
=>二维仿射变换(包含缩放、旋转、平移),只要知道仿射矩阵(👇得到-网络自己学习)和原始坐标
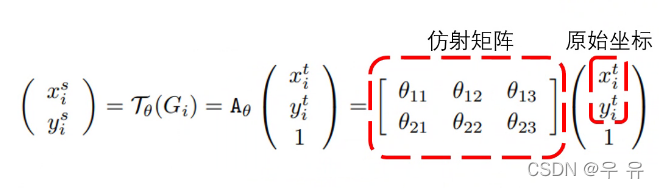
以上透视变换网络↑
chair 、chair-N投影数量少/只做一部分投影
研二研三 建议在之后的论文/汇报中,尽量将其与自己的工作结合起来进行分享,大家一起提建议
12.22 工作汇报
1、注重积累:平时实验等过程中有一些小的进展和收获的时候就记录下来
12.23 MAE
自监督检索目录 |
MAE主要思想 |
写作学习Tip:
①图语义表示:结构表示,关系表示、量化表示
②一致性和差异性(色彩、区块、线条、文字)
小讨论 Attention
1、注意力机制
提及论文-《sequence to sequence learning with Neural Network》论文、笔记
2、soft attention 和 hard attention
3、计算机视觉中的注意力机制
spatial domain(自注意力)、channel domain(通道与关键信息的相关度给权重 | SENet-2017CVPR-获得ImageNet2017的图像识别冠军、Squeeze-and-Excitation Networks)、mixed domain(CBAM-Concolution Block Attention Module、)
4、总结
优:多任务(分类-预测-强化学习-聚类…)、多领域、多结结构
缺:引入参数
5、提问
transformer、cvm定位等、long local、se等都是注意力=>这些注意力机制之间有什么差异和联系



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









