




 本文介绍了在PCL(Prototypical Contrastive Learning)框架下,使用EM算法结合K-Means聚类进行模型训练的过程。作者在CUDA11.4+torch1.8.2环境下,针对调整后的batch大小和线程数对imagenet100数据集进行实验,并详细阐述了聚类数量的调整原因和规则。
本文介绍了在PCL(Prototypical Contrastive Learning)框架下,使用EM算法结合K-Means聚类进行模型训练的过程。作者在CUDA11.4+torch1.8.2环境下,针对调整后的batch大小和线程数对imagenet100数据集进行实验,并详细阐述了聚类数量的调整原因和规则。
Prototypical Contrastive Learning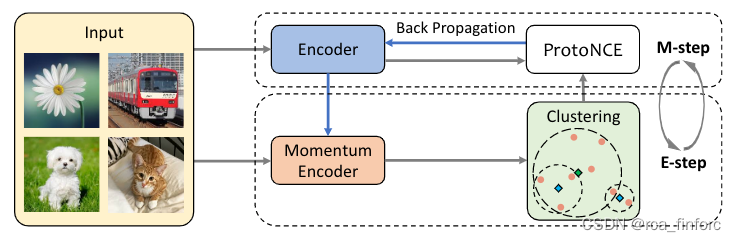
该论文模型与MoCo出奇地相似。使用了EM算法的步骤,在E步骤调用run_kmeans函数对特征进行聚类;在M步骤使用ProtoNCE loss更新encoder的参数。
代码来源:https://github.com/salesforce/PCL.git
本机环境:CUDA11.4+torch1.8.2+1080x2
train
训练main_pcl.py
$ python mail_pcl.py -a resnet50 --lr 0.03 --batch-size 64 --num-cluster 2500,5000,7500 --pcl-r 1664 --temperature 0.2 --workers 4 --mlp --aug-plus --cos --dist-url tcp://localhost:10001 --multiprocessing-distributed --world--size 1 --rank 0 --exp-dir experiment_pcl [imagenet_folder]
原文中采用--batch_size为256且线程数为32,机器显存不够用故调整batch为64,线程数4。
我下载的数据集是imagenet100,其中共100个类别,每个类别训练图片为1000,测试图片为300。拆分方法见https://blog.youkuaiyun.com/ECHOSON/article/details/108242639。
所以对聚类数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1699
1699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









