







南京理工大学 PCALab 的一篇工作,该实验室在 cvpr2020 也发表过一篇 zsl 的文章,感觉是准备在 zsl 上深耕的吧。
这篇文章的出发点在于原始的特征空间缺少鉴别性信息,然后学习一个新的嵌入空间。本文主要利用自监督对比学习来解决。作者贡献如下:
- 提出 hybrid GZSL framework 把生成方法和嵌入方法融合在一起(故事说的还挺好的);
- 提出 contrastive embedding ,既使用 class-wise supervision 也使用 instance-wise supervision。
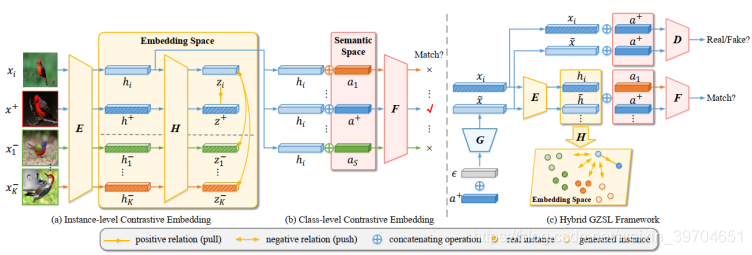
直接说方法,作者首先把原始特征通过 E 映射到 embedding space,即视觉样本 x x x 的 embedding 表示为 h = E ( x ) h=E(x) h=E(x)。
Instance-level contrastive embedding
作者想在潜空间中构造对比学习,同种类别的样本作为正样本,不同种类别的样本作为负样本。作者参考 SimCLR 的方法使用 non-linear projection head
H
H
H,使得
z
i
=
H
(
h
i
)
=
H
(
E
(
x
i
)
)
z_{i}=H\left(h_{i}\right)=H\left(E\left(x_{i}\right)\right)
zi=H(hi)=H(E(xi))。则对比学习 loss 如下
ℓ
c
e
i
n
s
(
z
i
,
z
+
)
=
−
log
exp
(
z
i
⊤
z
+
/
τ
e
)
exp
(
z
i
⊤
z
+
/
τ
e
)
+
∑
k
=
1
K
exp
(
z
i
⊤
z
k
−
/
τ
e
)
,
\ell_{c e}^{i n s}\left(z_{i}, z^{+}\right)=-\log \frac{\exp \left(z_{i}^{\top} z^{+} / \tau_{e}\right)}{\exp \left(z_{i}^{\top} z^{+} / \tau_{e}\right)+\sum_{k=1}^{K} \exp \left(z_{i}^{\top} z_{k}^{-} / \tau_{e}\right)},
ℓceins(zi,z+)=−logexp(zi⊤z+/τe)+∑k=1Kexp(zi⊤zk−/τe)exp(zi⊤z+/τe),
L c e i n s ( G , E , H ) = E z i , z + [ ℓ c e i n s ( z i , z + ) ] \mathcal{L}_{c e}^{i n s}(G, E, H)=\mathbb{E}_{z_{i}, z^{+}}\left[\ell_{c e}^{i n s}\left(z_{i}, z^{+}\right)\right] Lceins(G,E,H)=Ezi,z+[ℓceins(zi,z+)]
Class-level contrastive embedding
这也是一个比较有意思的点,由于视觉特征和属性不是一个维度的,所以不能通过余弦距离计算相似度,但是作者将他们拼接在一起从而获得预测结果。这个思路在 2019 的一篇基于生成模型的方法中也出现过。loss 如下
ℓ
c
e
c
l
s
(
h
i
,
a
+
)
=
−
log
exp
(
F
(
h
i
,
a
+
)
/
τ
s
)
∑
s
=
1
S
exp
(
F
(
h
i
,
a
s
)
/
τ
s
)
\ell_{c e}^{c l s}\left(h_{i}, a^{+}\right)=-\log \frac{\exp \left(F\left(h_{i}, a^{+}\right) / \tau_{s}\right)}{\sum_{s=1}^{S} \exp \left(F\left(h_{i}, a_{s}\right) / \tau_{s}\right)}
ℓcecls(hi,a+)=−log∑s=1Sexp(F(hi,as)/τs)exp(F(hi,a+)/τs)
L c e c l s ( G , E , F ) = E h i , a + [ ℓ c e c l s ( h i , a + ) ] \mathcal{L}_{c e}^{c l s}(G, E, F)=\mathbb{E}_{h_{i}, a^{+}}\left[\ell_{c e}^{c l s}\left(h_{i}, a^{+}\right)\right] Lcecls(G,E,F)=Ehi,a+[ℓcecls(hi,a+)]
总 loss
max
D
min
G
,
E
,
H
,
F
V
(
G
,
D
)
+
L
c
e
i
n
s
(
G
,
E
,
H
)
+
L
c
e
c
l
s
(
G
,
E
,
F
)
\max _{D} \min _{G, E, H, F} V(G, D)+\mathcal{L}_{c e}^{i n s}(G, E, H)+\mathcal{L}_{c e}^{c l s}(G, E, F)
DmaxG,E,H,FminV(G,D)+Lceins(G,E,H)+Lcecls(G,E,F)
这里第一项是 GAN loss。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B4p2UjMe-1629430485200)(image-20210428174025228.png)]](https://i-blog.csdnimg.cn/blog_migrate/39bb0222da0034594488d35fa6424eac.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LpkrSzdp-1629430485202)(image-20210428155547874.png)]](https://i-blog.csdnimg.cn/blog_migrate/4a5b7d68ee6bd89e6f43d845718525d0.png)
效果极好啊,可以说不可思议。当然直观的看可能是由于对比学习产生的,最好的结果是 TF-VAEGAN 了,作者的效果在 CUB 上直接高出 7 个点。然而如果从消融实验出发,即使是没有自监督对比学习,CUB 的效果依然都是 60 以上,感觉作者应该是某种训练技巧让性能已经大幅度提升了,挺值得研究下的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









