






踩坑(1)
今天发现都是用labelimg标记的数据集,但是如果数据集的文件名冲突的话,yolov5是训练不了的会报错,改文件名都没用只有在数据集刚开始的时候全部排序好才行,不然就是白做

踩坑(2)


这种情况主要是 Nms没做好或者是迭代次数太少。
踩坑(3)过拟合
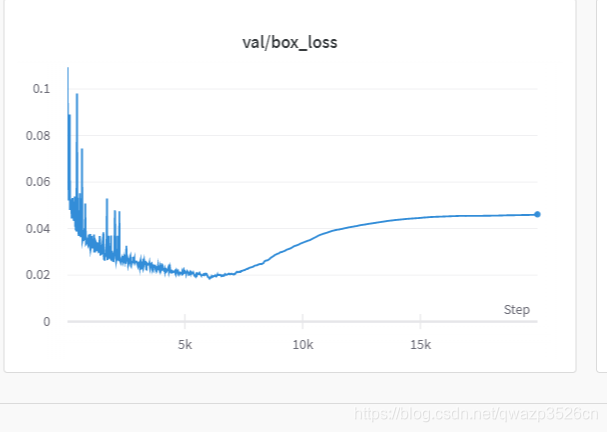
增大样本量
 本文分享了在使用labelimg标记数据集时遇到的问题,强调了文件名排序的重要性以避免Yolov5训练报错。此外,讨论了NMS算法优化和迭代次数对模型效果的影响,以及如何通过增加样本量来缓解过拟合。这些经验教训对于提升深度学习模型的训练效率和性能至关重要。
本文分享了在使用labelimg标记数据集时遇到的问题,强调了文件名排序的重要性以避免Yolov5训练报错。此外,讨论了NMS算法优化和迭代次数对模型效果的影响,以及如何通过增加样本量来缓解过拟合。这些经验教训对于提升深度学习模型的训练效率和性能至关重要。
今天发现都是用labelimg标记的数据集,但是如果数据集的文件名冲突的话,yolov5是训练不了的会报错,改文件名都没用只有在数据集刚开始的时候全部排序好才行,不然就是白做
这种情况主要是 Nms没做好或者是迭代次数太少。
增大样本量
您可能感兴趣的与本文相关的镜像

Yolo-v5
YOLO(You Only Look Once)是一种流行的物体检测和图像分割模型,由华盛顿大学的Joseph Redmon 和Ali Farhadi 开发。 YOLO 于2015 年推出,因其高速和高精度而广受欢迎
 524
1262
2812
2万+
524
1262
2812
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























