



 本文介绍了Pandas中的数据合并基础知识,包括笛卡尔积概念、数据合并的常用方法如append、assign、combine、update、concat、merge和join的适用场景及示例。此外,还探讨了merge_ordered和merge_asof的特殊用途,它们分别是merge在特定场景下的延伸应用。
本文介绍了Pandas中的数据合并基础知识,包括笛卡尔积概念、数据合并的常用方法如append、assign、combine、update、concat、merge和join的适用场景及示例。此外,还探讨了merge_ordered和merge_asof的特殊用途,它们分别是merge在特定场景下的延伸应用。
补充知识
- 笛卡尔积:
笛卡尔积:笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
知识脑图

部分代码
1.导入numpy和pandas模块,读取table.csv文件
import numpy as np
import pandas as pd
df = pd.read_csv('data/table.csv')
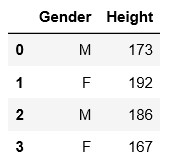
df.head()2.append举例
df_append = df.loc[:3,['Gender','Height']].copy()
df_appends = pd.Series({'Gender':'F','Height':188},name='new_row')
df_append.append(s)输出结果由:
变为:
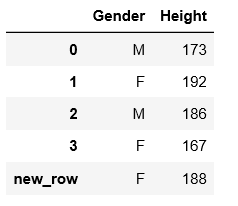
对于其他的函数这里就不再做补充了,遇到问题查一下文档再解决。
问题
【问题一】 请思考什么是append/assign/combine/update/concat/merge/join各自最适合使用的场景,并举出相应的例子。
append:在原先表的基础上可以用Series增加一行,需指定增加的name;用DataFrame增加表,指定增加的索引;(增加的都是行)
assign:添加列,列名由参数指定,添加一列或者多列;
combine:给定a表和b表,b表填充a表时,以列的顺序逐列添加,
update:默认使用左连接,没有返回值,直接在原先的表上操作,相当于更新操作;
concat:可以在两个维度上拼接,横向或者纵向,默认取拼接的并集,当inner时取交集
merge: merge函数的作用是将两个pandas对象横向合并,遇到重复的索引项时会使用笛卡尔积,默认inner连接,可选left、outer、right连接,可以用on参数指定对象进行连接
join: join函数作用是将多个pandas对象横向拼接,遇到重复的索引项时会使用笛卡尔积,默认左连接,可选inner、outer、right连接
【问题二】 merge_ordered和merge_asof的作用是什么?和merge是什么关系?
merge_ordered: 组合时间或者其他有序序列数据
merge_asof: 类似于左连接,对于左侧DataFrame中的每一行,选择on值对应小于left值的最后一行,两个DataFrame必须按键排序
都是merge的特殊情况
待续

















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









