



Pandas基础学习——分组
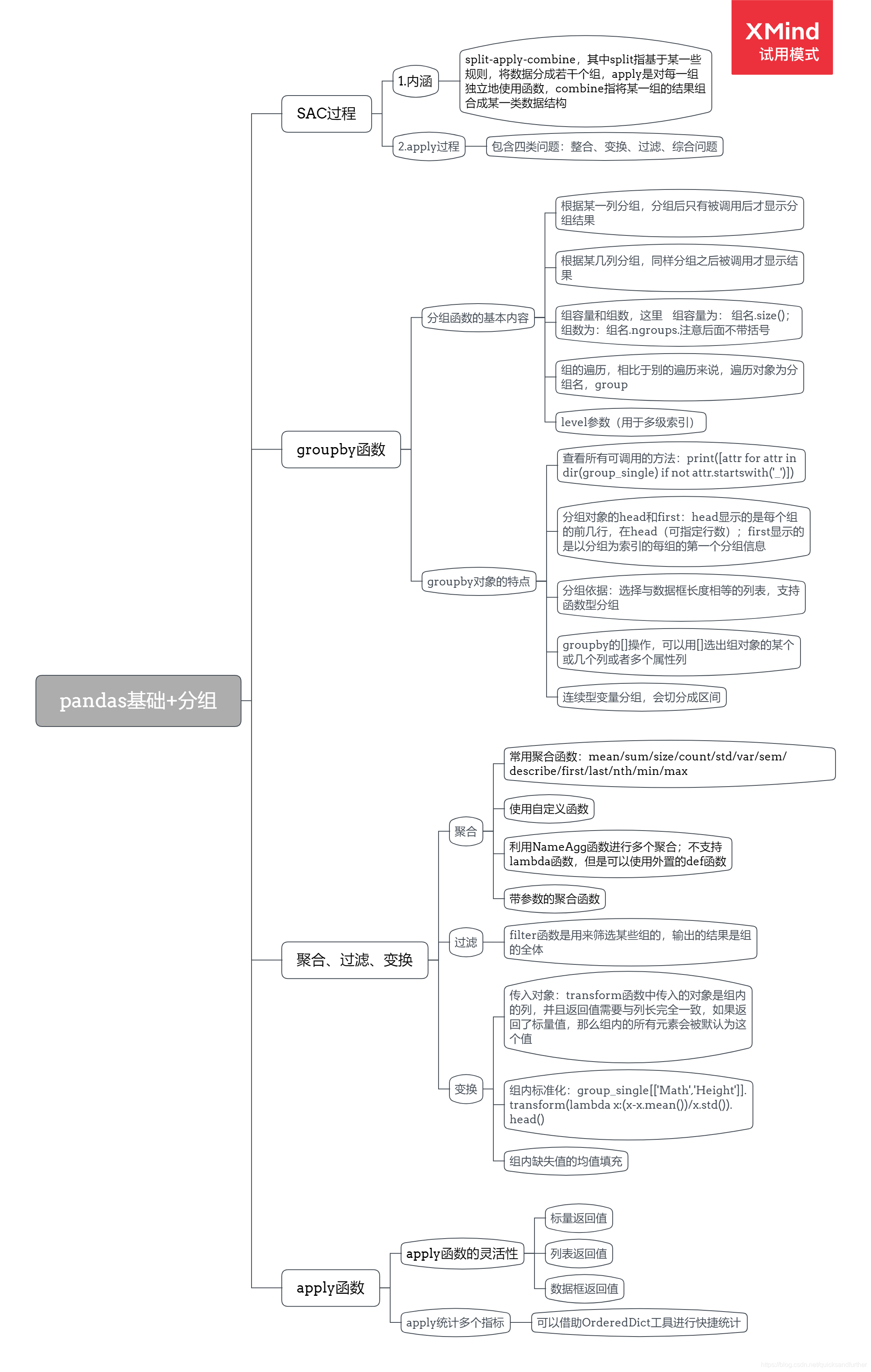
(1)分组,就是将一整个列表,以某一个属性分成若干个组,分别对组内成员进行操作,总体有三个过程,分别为split--apply--combine三个操作,在这三个操作之下又延申了一些细节的操作。
Pandas基础学习——分组
(1)分组,就是将一整个列表,以某一个属性分成若干个组,分别对组内成员进行操作,总体有三个过程,分别为split--apply--combine三个操作,在这三个操作之下又延申了一些细节的操作。
 8295
511
8295
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























